«`html
Борьба с взломом языковых моделей (LLM) с помощью E-RLHF от Meta AI и исследователей NYU
Большие языковые модели (LLM) в области глубокого обучения продемонстрировали исключительные возможности в таких областях, как помощь, генерация кода, здравоохранение и доказательство теорем. Однако LLM требуют помощи в генерации соответствующего контента, так как они подвержены производству оскорбительного или неподходящего контента из-за наличия вредоносных элементов в их обучающих наборах данных. Это создает сложные вызовы для исследователей в области безопасности LLM.
Практические решения и ценность
Исследователи представили теоретическую модель для анализа уязвимостей LLM и предложили инновационный подход E-RLHF для улучшения безопасности языковых моделей. Этот подход позволяет уменьшить уязвимости взлома и повысить безопасность моделей без ущерба для их производительности.
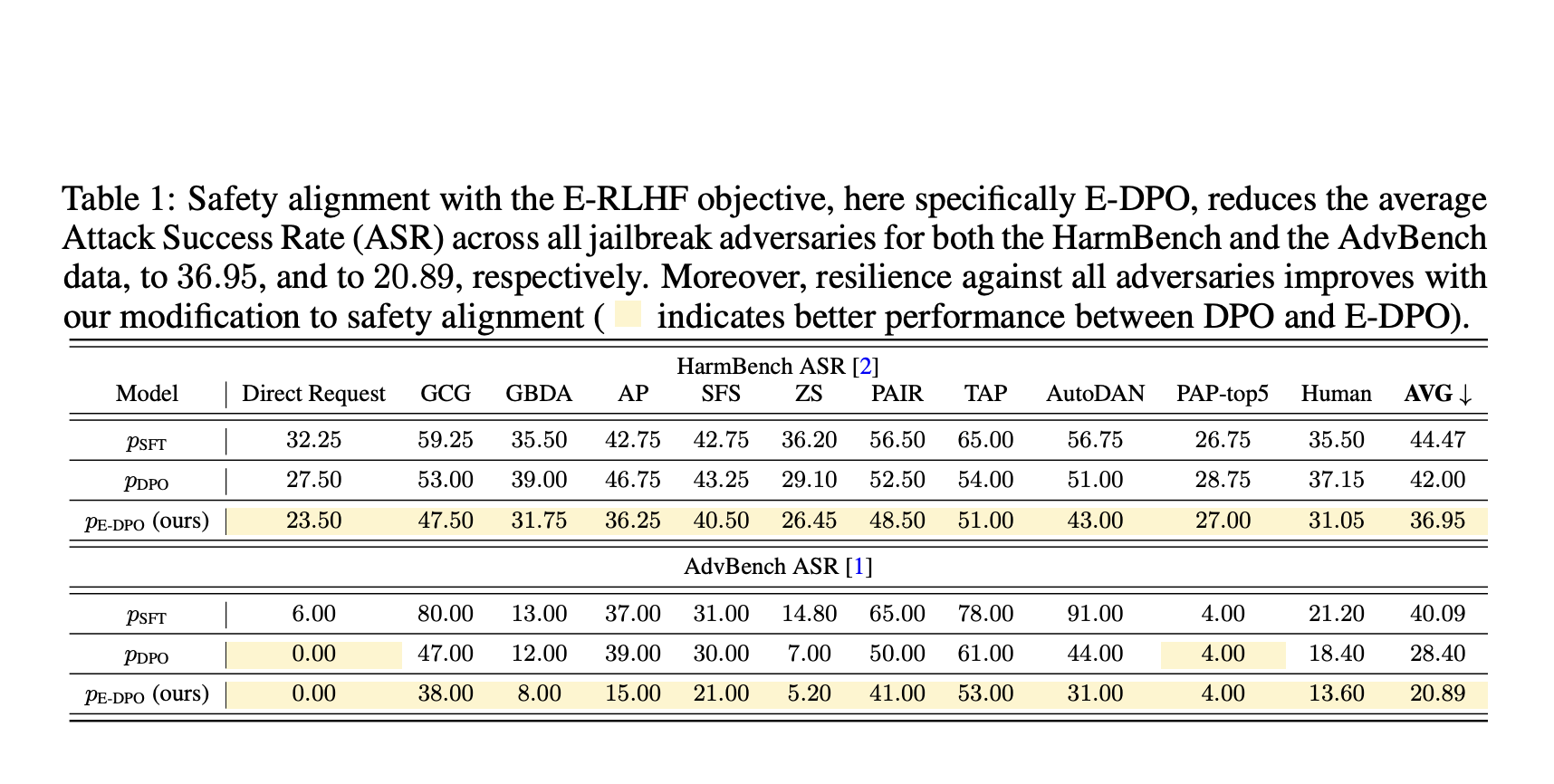
Эксперименты показали, что предложенный метод E-DPO снизил средний процент успешных атак (ASR) на всех типах атак для двух наборов данных, что демонстрирует улучшение по сравнению с стандартным DPO. Исследование также оценило полезность с помощью проекта MT-Bench, где E-DPO показал результат 6.6, превзойдя показатель модели SFT в 6.3.
Это исследование представило теоретическую модель для предварительного обучения языковых моделей и взлома, фокусируясь на разборе входных запросов на пары запросов и концепций. Исследователи разработали простую, но эффективную технику для улучшения безопасности моделей, что способствует созданию более безопасных и надежных языковых моделей.
«`

























