Проблемы и решения в области биомедицинских моделей с использованием ИИ
Развитие моделей понимания языка и изображения (VLMs) в биомедицинской области сталкивается с рядом трудностей. Основные проблемы связаны с отсутствием крупных, аннотированных и доступных многомодальных наборов данных. Хотя существуют наборы данных из биомедицинской литературы, они часто узко специализированы, например, на радиологии и патологии, игнорируя важные области, такие как молекулярная биология и фармакогеномика.
Практическое решение: BIOMEDICA
Исследователи Стэнфордского университета разработали BIOMEDICA — открытый фреймворк, который извлекает, аннотирует и организует данные из PubMed Central. Этот архив включает более 24 миллионов пар изображений и текстов из 6 миллионов статей, обогащенных метаданными и экспертными аннотациями.
Модели BMCA-CLIP, предобученные на BIOMEDICA, показывают выдающиеся результаты по 40 задачам, включая радиологию и молекулярную биологию, с улучшением на 6.56% в нулевой классификации и снижением вычислительных ресурсов.
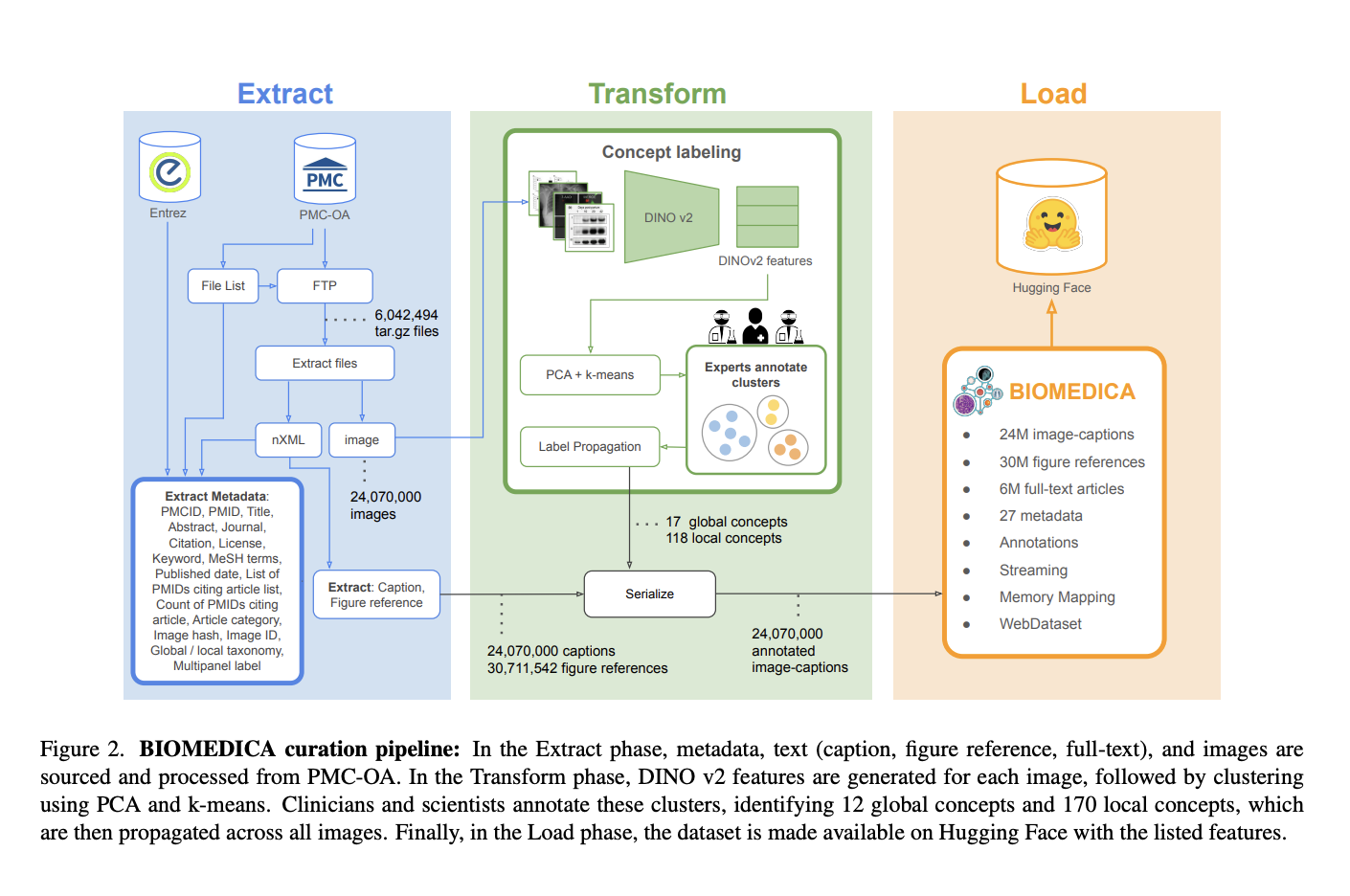
Процесс курирования данных BIOMEDICA
Процесс курирования включает в себя извлечение данных, маркировку концептов и сериализацию. Статьи и медиафайлы загружаются с сервера NCBI, извлекаются метаданные и подписи. Изображения группируются и маркируются через иерархическую таксономию, уточненную экспертами. Набор данных сериализован в формате WebDataset для эффективной передачи.
Оценка и эффективность BIOMEDICA
Оценка предобучения на наборе данных BIOMEDICA использовала 39 установленных задач классификации и новый набор данных для поиска из Flickr. Модели, обученные на BIOMEDICA, достигли лучших результатов, значительно превзойдя предыдущие методы.
Заключение
BIOMEDICA представляет собой комплексный фреймворк, который превращает набор данных PubMed Central в крупнейший готовый для глубокого обучения набор, содержащий 24 миллиона пар изображений и текстов с 27 полями метаданных. Этот открытый источник решает проблему нехватки разнообразных аннотированных биомедицинских наборов данных, обеспечивая масштабируемое решение для извлечения и аннотирования многомодальных данных.
Как ИИ может помочь вашей компании
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, рассмотрите следующие шаги:
- Определите, как ИИ может изменить вашу работу.
- Найдите возможности для автоматизации, где клиенты могут извлечь выгоду из ИИ.
- Установите ключевые показатели эффективности (KPI), которые хотите улучшить.
- Выберите подходящее решение, внедряйте ИИ постепенно, начиная с небольшого проекта.
Если вам нужны советы по внедрению ИИ, пишите нам.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.









