«`html
Технологические новшества в области сенсоров, искусственного интеллекта и вычислительной мощности за последние десятилетия подняли навигацию роботов на новый уровень. Для того чтобы роботы стали обычной частью нашей жизни, многие исследования предлагают переносить естественное языковое пространство ObjNav и VLN в мультимодальное пространство, чтобы робот мог одновременно выполнять команды как в текстовом, так и визуальном форматах. Этот вид морской деятельности исследователи называют Мультимодальной Инструкционной Навигацией (MIN).
Практическое применение
MIN включает в себя широкий спектр действий, включая исследование окружающей среды и выполнение инструкций для навигации. Однако использование обзорного тура, охватывающего всю область, позволяет избежать необходимости частого исследования.
Решения и ценность
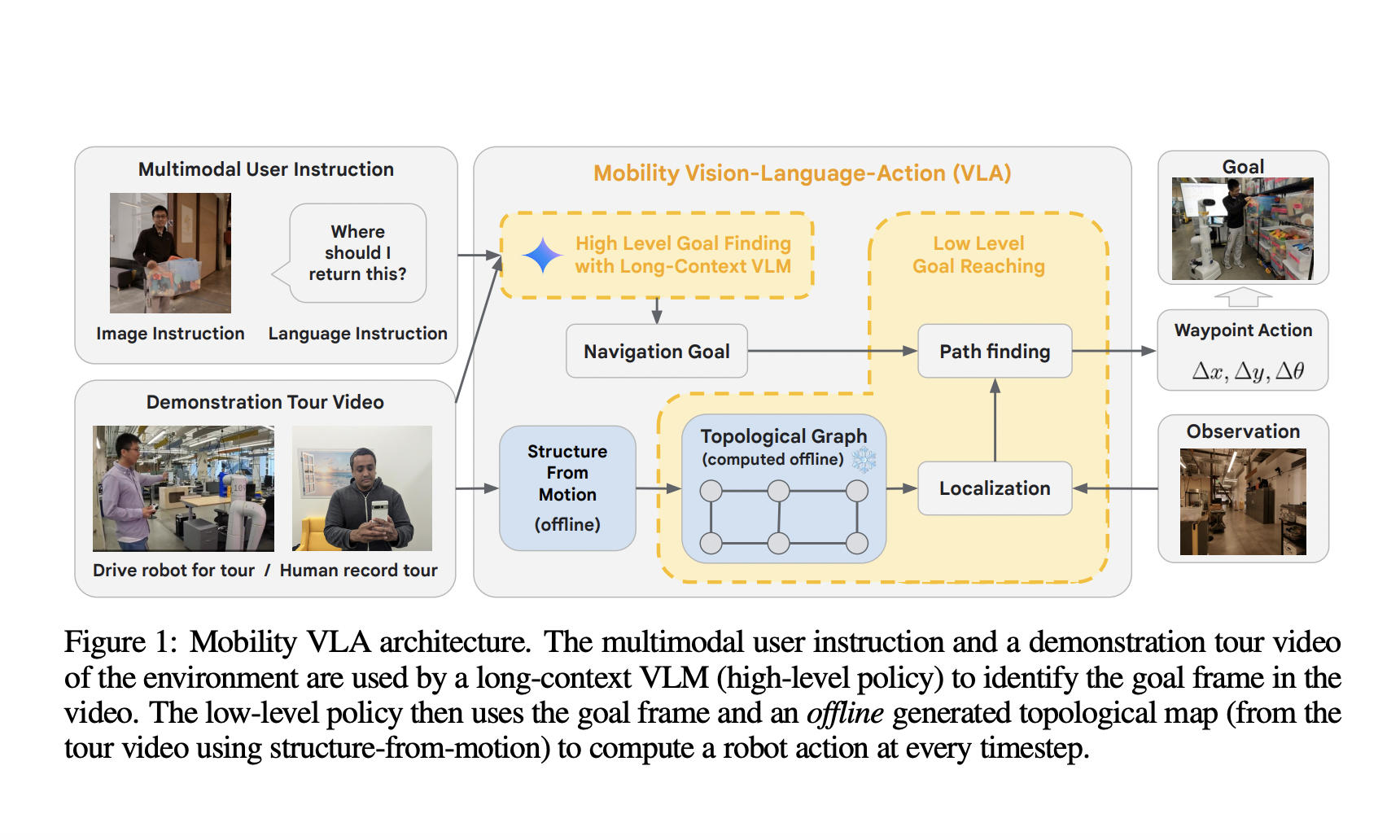
Исследование Google DeepMind представляет и исследует класс задач, называемый Мультимодальной Инструкционной Навигацией с Турами (MINT). MINT использует обзорные туры и занимается выполнением мультимодальных пользовательских инструкций. Важные возможности массовых моделей видения и языка (VLM) в интерпретации языка и изображений, а также в рассуждениях на основе здравого смысла, недавно продемонстрировали значительный потенциал в решении задач MINT.
Для решения MINT команда предлагает Mobility VLA, иерархическую навигационную политику Vision-Language-Action (VLA), которая интегрирует знание окружающей среды и способность интуитивного рассуждения на основе VLM с низкоуровневой навигационной политикой на основе топологических сетей. Тестирование Mobility VLA в реалистичной офисной среде и жилой зоне показало многообещающие результаты, подтверждающие его способности в реальных сценариях.
Помимо этого, Mobility VLA может быть реализован на множестве роботов благодаря низким требованиям к вычислительным мощностям и использованию только RGB-изображений, что открывает перспективы для широкого внедрения в области робототехники и искусственного интеллекта.
«`

























