«`html
Внедрение Docmatix: набор данных для визуального ответа на вопросы по документам
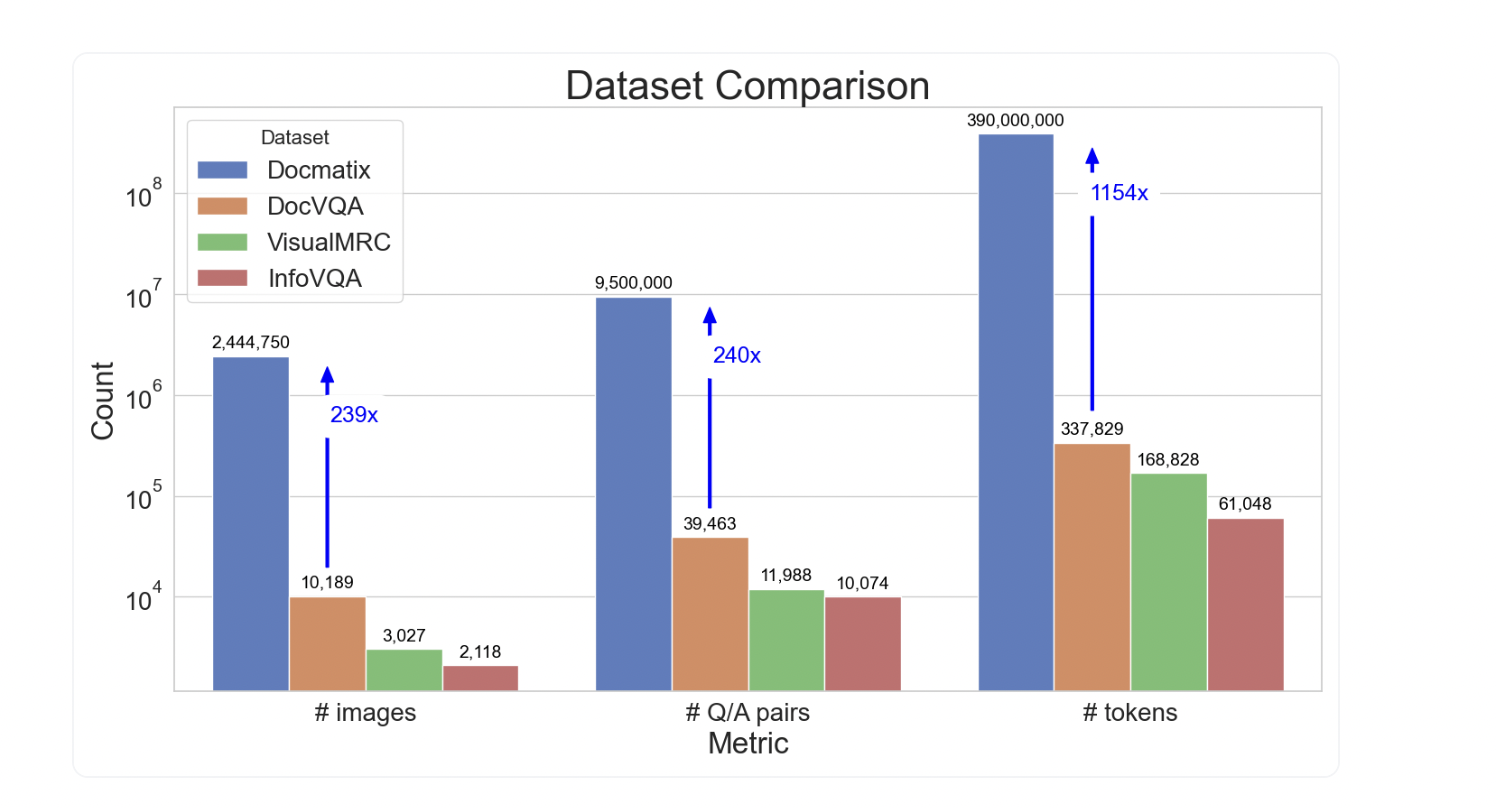
Docmatix — это масштабный набор данных для визуального ответа на вопросы по документам (DocVQA), содержащий 2,4 миллиона изображений и 9,5 миллиона пар вопрос-ответ. Этот набор данных позволяет обучать и улучшать модели для автоматического анализа и ответа на запросы по содержимому документов.
Практическое применение
Docmatix обеспечивает возможность автоматизировать процессы работы с документами в различных отраслях, делая их более доступными через генерацию кратких сводок и ответов на запросы. Это значительно упрощает доступ к информации, содержащейся в документах, и повышает эффективность работы с ними.
Для более широкого применения моделей Vision-Language Models (VLMs), таких как Idefics2, Docmatix предоставляет возможность улучшения их производительности, так как обучение на более крупных и качественных наборах данных способствует повышению обобщаемости моделей.
Создание и обработка набора данных
Docmatix был создан на основе коллекции PDFA, содержащей более двух миллионов PDF-документов. С помощью модели Phi-3-small были созданы пары вопрос-ответ на основе транскрипций PDFA. После обработки документов, изображения с разрешением 150 dpi были сохранены в Hugging Face Hub для общего доступа.
Набор данных Docmatix прошел тщательную фильтрацию, чтобы исключить ложные ответы, и теперь доступен для использования в различных приложениях и исследованиях.
Применение в работе
Docmatix представляет собой ценный инструмент для обучения и улучшения моделей для визуального ответа на вопросы по документам. Он позволяет сократить разрыв между проприетарными и открытыми моделями VLMs и способствует развитию и применению искусственного интеллекта в различных областях бизнеса.
Используйте Docmatix для улучшения процессов работы с документами и обеспечения более эффективного доступа к информации. Это позволит вашей компании оставаться на передовой в области применения искусственного интеллекта.
Для получения дополнительной информации о наборе данных и его применении обращайтесь к исследователям проекта.
Не забудьте следить за нашими обновлениями в социальных сетях и присоединиться к нашему сообществу.
«`

























