Проблемы больших языковых моделей (LLM)
Большие языковые модели требуют много вычислительных и памятьных ресурсов для обработки длинных последовательностей. Это приводит к медленной работе и высоким затратам на оборудование. Механизм внимания, который является ключевым компонентом, усугубляет эти проблемы из-за своей квадратичной сложности.
Основные ограничения LLM:
- Не могут обрабатывать последовательности длиннее обученного контекстного окна.
- Снижение производительности при работе с длинными входами.
- Неэффективное управление памятью и высокие затраты на вычисления.
Решения для обработки длинного контекста
Существуют различные подходы для решения проблемы обработки длинного контекста:
- FlashAttention2 (FA2) – оптимизирует использование памяти, но не решает вычислительную неэффективность.
- Выборочное внимание токенов – снижает накладные расходы на обработку.
- Стратегии удаления кэша KV – могут навсегда удалить важную информацию.
- HiP Attention – переносит редко используемые токены во внешнюю память, но может увеличивать задержку.
Инновация InfiniteHiP
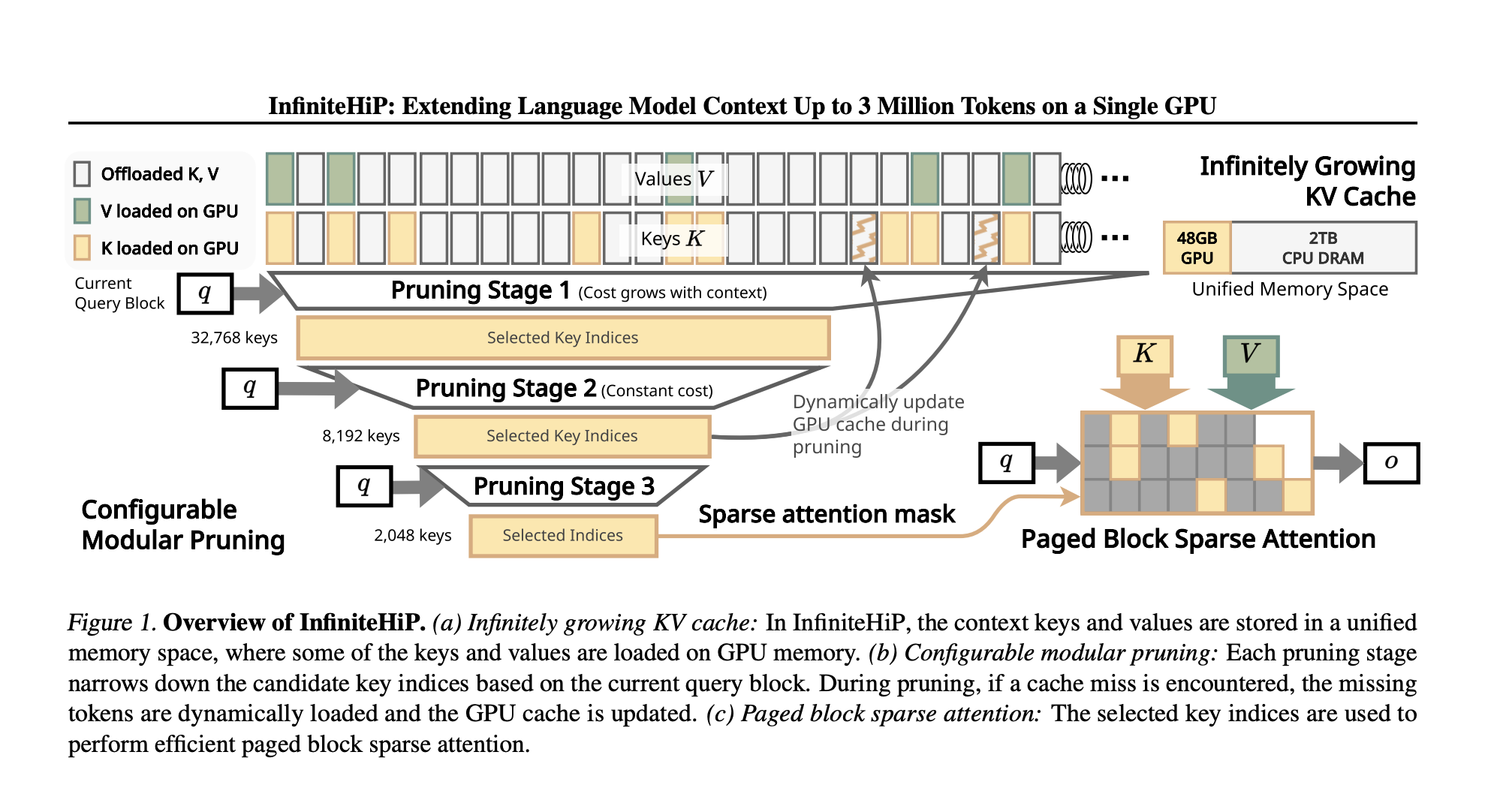
Исследователи из KAIST и DeepAuto.ai представили InfiniteHiP, передовую систему, которая обеспечивает эффективное извлечение длинного контекста и снижает нагрузку на память. Модель использует алгоритм иерархической обрезки токенов, который динамически удаляет менее релевантные токены.
Преимущества InfiniteHiP:
- Динамическое удаление токенов, которые не способствуют вычислениям внимания.
- Адаптивные корректировки RoPE для работы с длинными последовательностями.
- Новый механизм выгрузки кэша KV для эффективного извлечения токенов.
- Обработка до 3 миллионов токенов на GPU с 48 ГБ памяти.
Результаты и производительность
InfiniteHiP обеспечивает ускорение декодирования внимания в 18.95 раз для контекста в один миллион токенов по сравнению с традиционными методами. Выгрузка кэша KV снижает потребление памяти GPU до 96%.
Преимущества:
- Увеличение производительности на потребительских и корпоративных GPU.
- Постоянно превосходит современные методы в бенчмарках.
Значение для бизнеса
InfiniteHiP решает основные проблемы длины контекста, улучшая возможности LLM. Это позволяет моделям обрабатывать длинные последовательности без потери контекста и увеличения затрат на вычисления. Решение масштабируемое и эффективно для различных AI приложений.
Как внедрить AI в ваш бизнес:
- Анализируйте, как AI может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI).
- Выбирайте подходящее решение AI.
- Внедряйте AI постепенно с небольших проектов.
- Расширяйте автоматизацию на основе полученных данных.
Если вам нужны советы по внедрению ИИ, пишите нам.
Попробуйте ИИ ассистент в продажах, который помогает отвечать на вопросы клиентов и снижает нагрузку на команду.

























