Оптимизация поиска с использованием искусственного интеллекта
Сегодня одной из значительных задач в поиске информации является определение наиболее эффективного метода поиска ближайших векторов, особенно с увеличением сложности моделей плотного и разреженного поиска. Практики должны выбирать между различными методами индексации и поиска, включая графы HNSW (Hierarchical Navigable Small-World), плоские индексы и инвертированные индексы. Эти методы предлагают различные компромиссы в скорости, масштабируемости и качестве результатов поиска. При увеличении размеров наборов данных и их сложности отсутствие четкого руководства затрудняет оптимизацию систем, особенно для приложений, требующих высокой производительности, таких как поисковые системы и приложения на основе искусственного интеллекта, например, системы вопросов и ответов.
Традиционные методы поиска ближайших соседей
Традиционно поиск ближайших соседей осуществляется с использованием трех основных подходов: индексы HNSW, плоские индексы и инвертированные индексы. Индексы HNSW часто используются из-за их эффективности и скорости в задачах поиска на больших масштабах, особенно с плотными векторами, но они требуют значительных вычислительных затрат и времени индексации. Плоские индексы, хотя точны в результатах поиска, становятся неэффективными для больших наборов данных из-за медленной производительности запросов. Разреженные модели поиска, такие как BM25 или SPLADE++ ED, используют инвертированные индексы и могут быть эффективны в конкретных сценариях, но часто лишены богатого семантического понимания, предоставляемого моделями плотного поиска. Основным ограничением всех этих подходов является то, что ни один из них не является универсально применимым, поскольку каждый метод обладает различными преимуществами и недостатками в зависимости от размера набора данных и требований к поиску.
Практические рекомендации на основе исследования
Исследователи из Университета Ватерлоо представляют тщательную оценку компромиссов между индексами HNSW, плоскими и инвертированными индексами как для моделей плотного, так и для разреженного поиска. Это исследование предоставляет подробный анализ производительности этих методов, измеренный по времени индексации, скорости запросов (QPS) и качеству поиска (nDCG@10), с использованием набора данных BEIR в качестве бенчмарка. Исследователи стремятся дать практические, основанные на данных советы по оптимальному использованию каждого метода в зависимости от размера набора данных и требований к поиску. Их результаты показывают, что HNSW чрезвычайно эффективен для наборов данных большого масштаба, в то время как плоские индексы лучше всего подходят для небольших наборов данных из-за своей простоты и точности. Кроме того, исследование исследует преимущества использования техник квантования для улучшения масштабируемости и скорости процесса поиска, предлагая значительное улучшение для практиков, работающих с большими наборами данных.
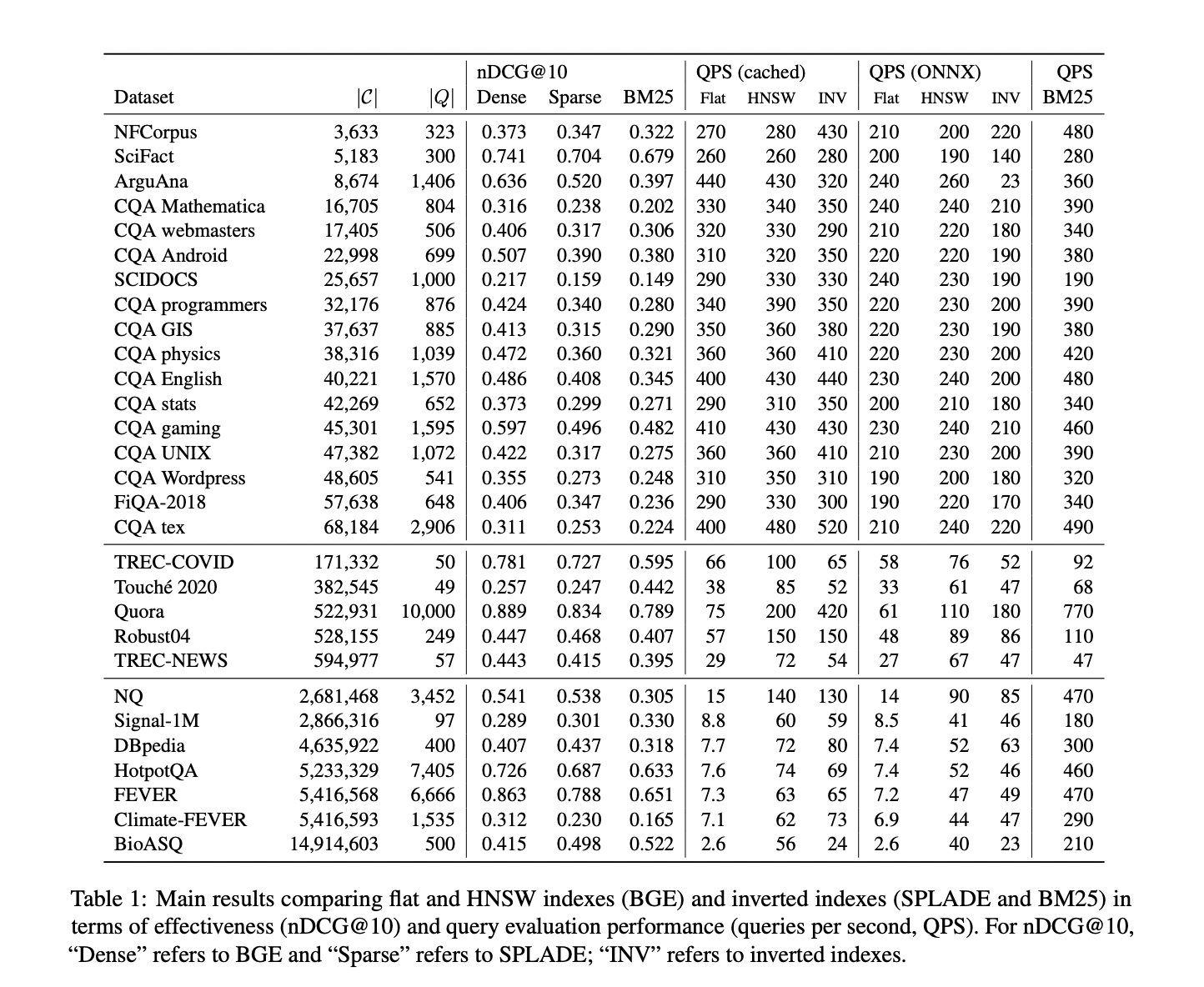
Экспериментальная настройка использует набор данных BEIR, включающий 29 наборов данных, разработанных для отражения реальных вызовов поиска информации. В качестве модели плотного поиска используется BGE (Base General Embeddings), а в качестве базовых для разреженного поиска — SPLADE++ ED и BM25. Оценка фокусируется на двух типах индексов плотного поиска: HNSW, который строит графовые структуры для поиска ближайших соседей, и плоские индексы, которые полагаются на поиск методом перебора. Инвертированные индексы используются для разреженных моделей поиска. Оценки проводятся с использованием библиотеки поиска Lucene с конкретными конфигурациями, такими как M=16 для HNSW. Производительность оценивается с использованием ключевых метрик, таких как nDCG@10 и QPS, а производительность запросов оценивается в двух условиях: кэшированные запросы (предварительно вычисленное кодирование запроса) и кодирование запросов в реальном времени на основе ONNX.
Результаты показывают, что для небольших наборов данных (менее 100 тыс. документов) плоские и HNSW индексы демонстрируют сопоставимую производительность как по скорости запросов, так и по качеству поиска. Однако с увеличением размеров наборов данных HNSW индексы начинают значительно превосходить плоские индексы, особенно по скорости оценки запросов. Для больших наборов данных, превышающих 1 миллион документов, HNSW индексы обеспечивают значительно большее количество запросов в секунду (QPS), с незначительным снижением качества поиска (nDCG@10). При работе с наборами данных более 15 миллионов документов HNSW индексы демонстрируют существенное улучшение скорости при приемлемой точности поиска. Техники квантования дополнительно улучшают производительность, особенно для больших наборов данных, обеспечивая значительное увеличение скорости запросов без существенного снижения качества. В целом методы плотного поиска с использованием HNSW оказываются намного более эффективными и эффективными, чем разреженные модели поиска, особенно для приложений большого масштаба, требующих высокой производительности.
Практические рекомендации для практиков
Это исследование предлагает важные рекомендации для практиков в области плотного и разреженного поиска, предоставляя всестороннюю оценку компромиссов между индексами HNSW, плоскими и инвертированными индексами. Результаты показывают, что индексы HNSW отлично подходят для задач поиска большого масштаба благодаря их эффективности в обработке запросов, в то время как плоские индексы идеально подходят для небольших наборов данных и быстрого прототипирования из-за своей простоты и точности. Предоставляя эмпирически обоснованные рекомендации, это исследование значительно способствует пониманию и оптимизации современных систем поиска информации, помогая практикам принимать обоснованные решения для поисковых приложений на основе искусственного интеллекта.

























