«`html
Эффективные большие языковые модели (LLM) с помощью устранения умножения матриц для масштабируемой производительности
Большинство топологий нейронных сетей тесно связаны с умножением матриц (MatMul), в основном потому, что это необходимо для многих базовых процессов. Векторно-матричное умножение (VMM) обычно используется в плотных слоях нейронных сетей, а матрично-матричное умножение (MMM) используется в механизмах самовнимания. Тяжелая зависимость от MatMul в значительной степени обусловлена оптимизацией GPU для таких задач. Использование библиотек линейной алгебры, таких как cuBLAS и архитектура единого устройства вычислений (CUDA), позволяет эффективно параллелизировать и ускорить операции MatMul, что значительно улучшает производительность.
Практические решения и ценность
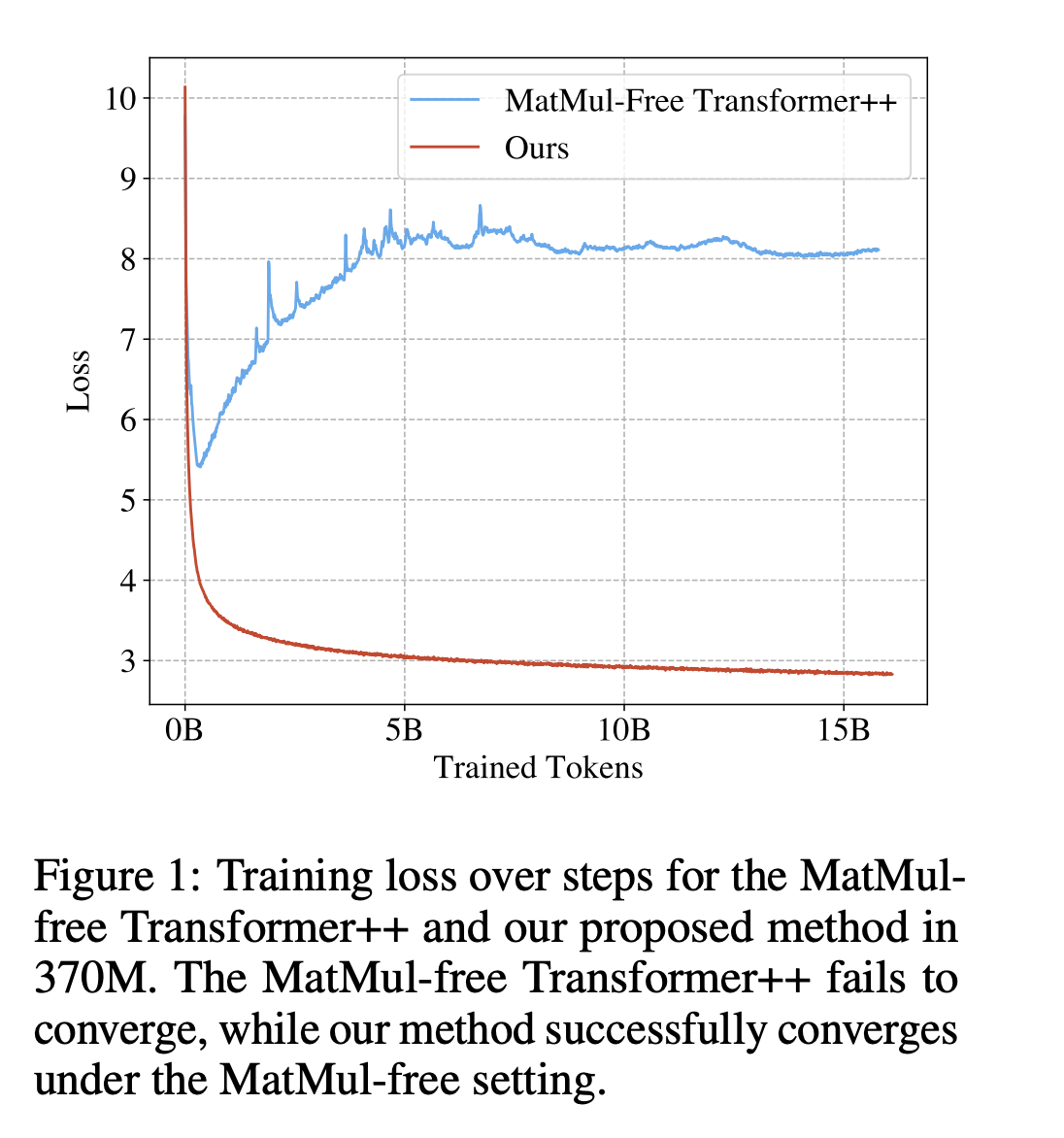
Большие языковые модели (LLM) часто требуют, чтобы большая часть их вычислительной работы выполнялась с помощью умножения матриц. При увеличении размеров вложенных измерений и длины контекста эта нагрузка становится еще более значительной. Даже на масштабах миллиарда параметров возможно полностью устранить процессы MatMul из LLM без ущерба для надежной производительности.
Команда исследователей из Университета Калифорнии в Санта-Круз, Университета Сучжоу, Университета Калифорнии в Дэвисе и LuxiTech обнаружила, что для моделей размером до по крайней мере 2,7 миллиарда параметров модели без MatMul могут достичь производительности, близкой к уровню передовых трансформеров, которые обычно используют существенно больше памяти для вывода. После обширного тестирования команда обнаружила, что разница в производительности между моделями без MatMul и обычными трансформерами полной точности уменьшается по мере увеличения размера модели. Это говорит о том, что большим моделям не нужно полагаться на операции MatMul, чтобы оставаться успешными и эффективными.
Команда создала эффективную версию для GPU, которая снижает использование памяти на 61% во время обучения по сравнению с неоптимизированным базовым уровнем, чтобы решить практические проблемы реализации этих моделей. Они использовали оптимизированное ядро для вывода, которое снижает потребление памяти в десять раз по сравнению с неоптимизированными моделями. Эти модели стали более доступными для широкого спектра приложений и более эффективными благодаря значительному снижению использования памяти.
Команда также разработала уникальное аппаратное решение на программируемом вентильном поле (FPGA), чтобы полностью использовать легковесную природу этих моделей. Эта технология обрабатывает модели масштаба миллиарда параметров при 13 ваттах, используя легковесные операции, которые выходят за рамки возможностей текущих GPU. Эта эффективность приближает LLM к энергоэффективности, приближаясь к энергопотреблению человеческого мозга.
Исследование показало, что значительное снижение сложности LLM возможно без ущерба для их способности хорошо функционировать. Оно также иллюстрирует виды операций, на которые следует сосредоточиться следующему поколению аппаратных ускорителей, чтобы обрабатывать легковесные LLM. Этот прогресс позволил создать более эффективные, масштабируемые и полезные реализации больших языковых моделей.
Проверьте статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на нас в Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 43k+ ML SubReddit. Также ознакомьтесь с нашей платформой AI Events.