Кросс-языковое клонирование кода: практические решения и ценность
Кросс-языковое клонирование кода стало важной и сложной задачей из-за растущей сложности современной разработки программного обеспечения, где обычно используется множество языков программирования в рамках одного проекта.
Это описание процесса поиска идентичных или почти идентичных сегментов кода на разных языках программирования.
Практические решения
Недавние достижения в области искусственного интеллекта и машинного обучения сделали огромный прогресс в решении многих задач в области вычислений, особенно с появлением больших языковых моделей (LLM). Благодаря своим исключительным навыкам обработки естественного языка, LLM привлекли внимание своей возможной использования в задачах, связанных с кодом, таких как обнаружение клонов кода.
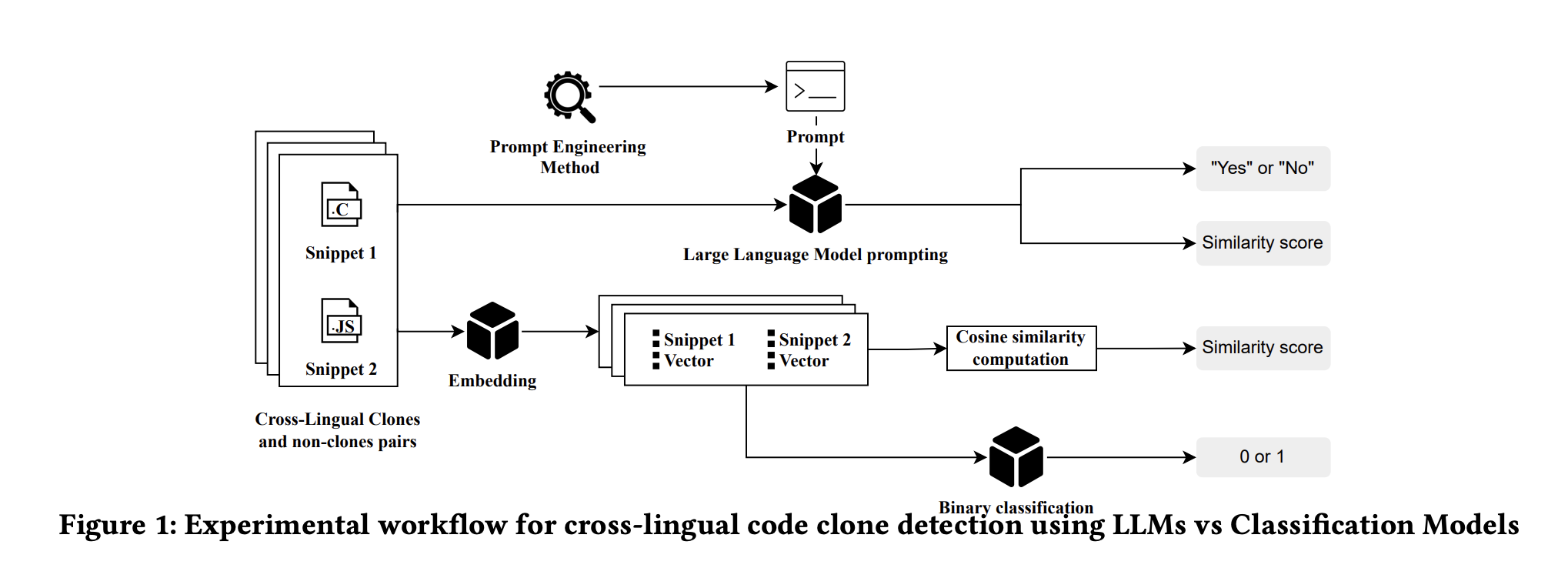
Исследование оценивает производительность четырех различных LLM в сочетании с восемью уникальными подсказками, предназначенными для поддержки обнаружения кросс-языковых клонов кода. Оно также оценивает полезность предварительно обученной модели эмбеддингов, которая создает векторные представления фрагментов кода.
Исследование сравнивает производительность LLM с традиционными методами машинного обучения, используя обученные представления кода в качестве основы. Оно также обсуждает обобщаемость и универсальную эффективность LLM в задачах обнаружения кросс-языковых клонов кода.
Ценность
Результаты исследования показывают, что LLM могут быть высокоэффективны, особенно при работе с простыми примерами кода. Однако они могут оказаться менее эффективными в обнаружении кросс-языковых клонов кода в более сложных ситуациях. В то же время, модели эмбеддингов более подходят для достижения передовой производительности в этой области, поскольку они обеспечивают последовательные и языконейтральные представления кода.
Заключение
Итак, хотя LLM обладают высокой способностью, особенно при работе с простым кодом, они могут оказаться не самым эффективным методом для обнаружения кросс-языковых клонов кода, особенно в более сложных ситуациях. Вместо этого модели эмбеддингов более подходят для достижения передовой производительности в этой области, поскольку они обеспечивают последовательные и языконейтральные представления кода.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Embeddings or LLMs: What’s Best for Detecting Code Clones Across Languages?
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/ Этот ИИ ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru

























