«`html
Как масштаб влияет на предсказание возможностей фронтовых моделей искусственного интеллекта: понимание ускользающего
Предсказание поведения масштабируемых систем искусственного интеллекта, таких как GPT-4, Claude и Gemini, является ключевым для понимания их потенциала и принятия решений о их развитии и использовании. Однако сложно предсказать, как эти системы будут работать на конкретных задачах при увеличении масштаба, несмотря на установленную связь между параметрами, данными, вычислениями и потерями при предварительном обучении, определенную законами масштабирования. Например, производительность на стандартных бенчмарках по обработке естественного языка иногда может показывать непредсказуемые изменения с увеличением масштаба. Некоторые исследования предполагают, что эти непредсказуемые изменения могут быть вызваны выбором метрик и недостатком разрешения.
Направления исследования
Эта статья содержит два основных направления. Первое — «За пределами бенчмарков с множественным выбором», где исследование фокусируется на бенчмарках, оцениваемых с использованием форматов множественного выбора на основе логарифма вероятности. Хотя этот фокус ценен из-за полезности и распространенности таких задач, он ограничивает более широкое применение результатов. Второе направление — «Предсказание производительности бенчмарков A Priori», которое объясняет, почему сложно предсказать производительность бенчмарков с множественным выбором, используя метрики, такие как точность и оценка Бриера. Однако анализы предполагают доступ к оценкам целых семейств моделей на различных порядках величины предварительного обучения и не используют обратное тестирование.
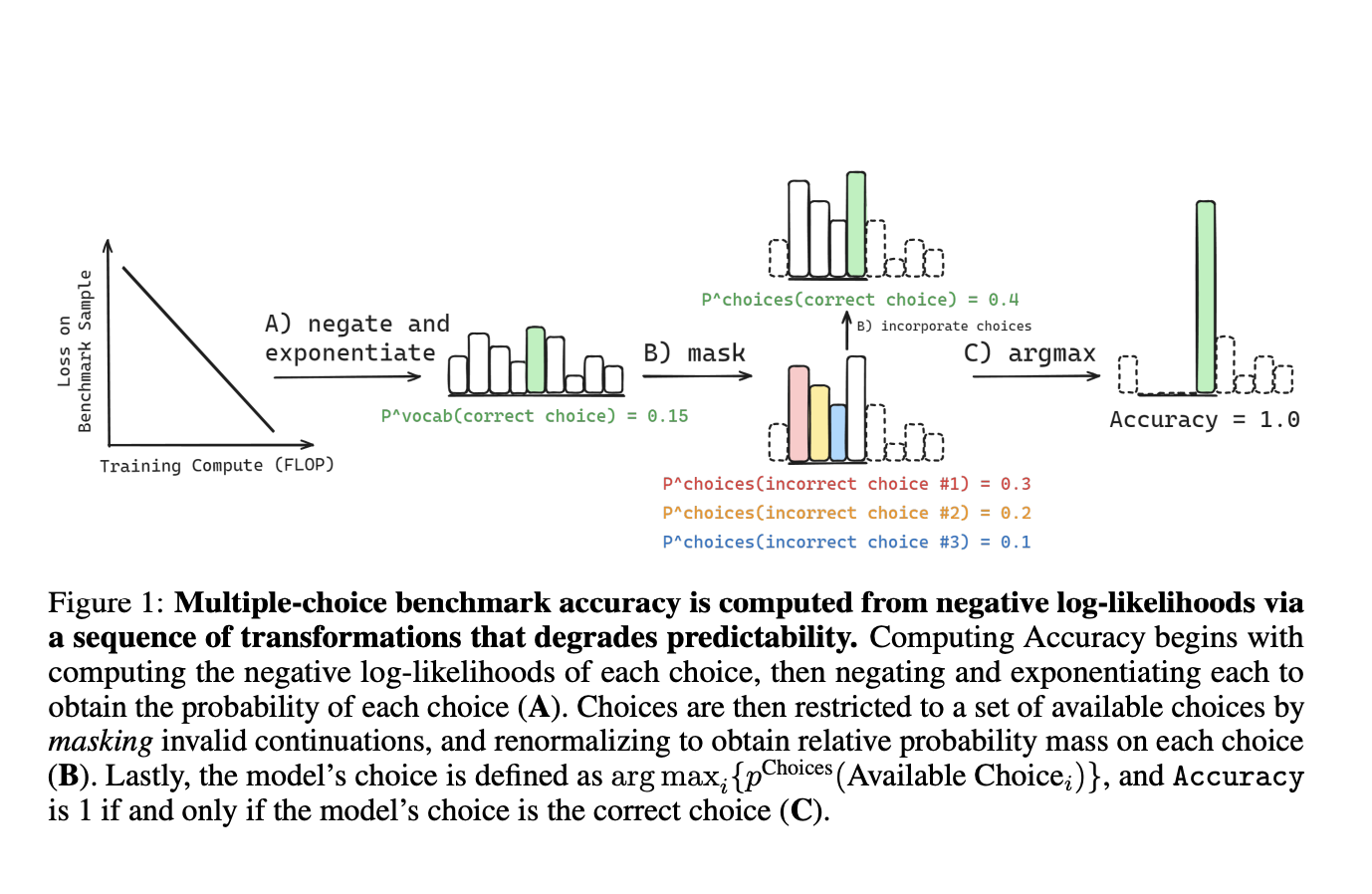
Исследователи из Университета Кембриджа, Stanford CS, EleutherAI и MILA показали, что общие множественные метрики выбора, такие как точность, оценка Бриера и правильность вероятности, могут быть оценены на основе необработанных выходов модели. Это достигается через последовательность преобразований, которые постепенно разрушают статистическую связь между этими метриками и параметрами масштабирования. Основная причина заключается в том, что эти метрики зависят от прямого сравнения между правильным выводом и ограниченным набором конкретных неправильных выводов. Поэтому для точного предсказания производительности на следующем этапе необходимо моделировать, как вероятностная масса колеблется среди конкретных неправильных альтернатив.
Исследователи изучали, как вероятностная масса на неправильных выборах колеблется с увеличением вычислений. Это помогает понять, почему индивидуальные метрики на следующем этапе могут быть непредсказуемы, в то время как законы масштабирования потерь при предварительном обучении более последовательны, поскольку они не зависят от конкретных неправильных выборов. Для разработки оценок, которые эффективно отслеживают прогресс передовых возможностей искусственного интеллекта, важно понимать, что влияет на производительность на следующем этапе. Более того, для того чтобы увидеть, как возможности на следующем этапе по конкретным задачам изменяются с масштабом для различных семейств моделей, генерируются оценки на образец из различных семейств моделей и множественных бенчмарков по обработке естественного языка.
Для точного предсказания производительности на тестах с множественным выбором важно понимать, как меняется вероятность выбора правильного ответа с увеличением масштаба, а также как меняется вероятность выбора неправильного ответа с увеличением масштаба. Для метрик, таких как точность, эти предсказания должны быть сделаны для каждого вопроса, потому что знание средней вероятности выбора неправильных ответов на множестве вопросов не определяет вероятность выбора конкретного неправильного ответа для конкретного вопроса. Особенно важно рассмотреть, как вероятности выбора правильных и неправильных ответов изменяются вместе с увеличением вычислительной мощности.
В заключение, исследователи обнаружили фактор, вызывающий непредсказуемость в тестах с множественным выбором для моделей фронтового искусственного интеллекта. Этим фактором является вероятность выбора неправильных ответов. Результаты могут повлиять на разработку будущих оценок для моделей фронтового искусственного интеллекта, которые можно надежно предсказать при масштабировании. Будущая работа сосредоточена на создании более предсказуемых оценок для систем искусственного интеллекта, особенно для сложных и важных возможностей. Исследователи предложили несколько направлений для расширения работы и применения своей структуры для дальнейшего улучшения предсказуемости масштабирования.
Проверьте статью. Вся заслуга за этот исследовательский проект принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 44k+ ML SubReddit
Оригинал статьи опубликован на сайте MarkTechPost.
Как масштаб влияет на предсказание возможностей фронтовых моделей искусственного интеллекта: понимание ускользающего
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте How Scale Impacts Predicting Downstream Capabilities of Frontier AI Models: Understanding the Elusiveness.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram.
Попробуйте ИИ ассистент в продажах здесь. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
«`

























