«`html
Улучшение фактической точности моделей языка с помощью стратегического подхода к составлению набора данных для вопросно-ответных систем
Большие языковые модели (LLM) привлекли значительное внимание благодаря их способности хранить огромные объемы фактических знаний в своих весах во время предварительного обучения. Эта способность привела к многообещающим результатам в задачах, связанных с фактическими вопросами и ответами. Однако существует серьезное препятствие: LLM часто генерируют правдоподобные, но неверные ответы на запросы, подрывая их надежность. Эта несогласованность в фактической точности представляет собой значительное препятствие для широкого принятия и доверия к LLM в приложениях, основанных на знаниях. Исследователи борются с проблемой улучшения фактической точности выводов LLM, сохраняя при этом их универсальность и генеративные возможности. Проблема дополнительно осложняется наблюдением того, что даже когда LLM обладают правильной информацией, они все равно могут производить неточные ответы, что указывает на основные проблемы в извлечении и применении знаний.
Практические решения:
Исследователи предприняли различные подходы для улучшения фактической точности в LLM. Некоторые исследования сосредотачиваются на влиянии незнакомых примеров во время тонкой настройки, выявляя, что они могут потенциально ухудшить фактическую точность из-за переобучения. Другие подходы изучают надежность фактических знаний, показывая, что LLM часто плохо справляются с неизвестной информацией. Техники для улучшения фактической точности включают в себя манипулирование механизмами внимания, использование ненаблюдаемых внутренних зондов и разработку методов для того, чтобы LLM воздерживались от ответа на неопределенные вопросы. Некоторые исследователи предложили техники тонкой настройки, чтобы побудить LLM отказываться от вопросов за пределами их знаний. Также проводились исследования механизмов LLM и динамики обучения, изучая, как факты хранятся и извлекаются, и анализируя динамику предварительного обучения синтаксического усвоения и образцов внимания. Несмотря на эти усилия, остаются проблемы в достижении последовательной фактической точности.
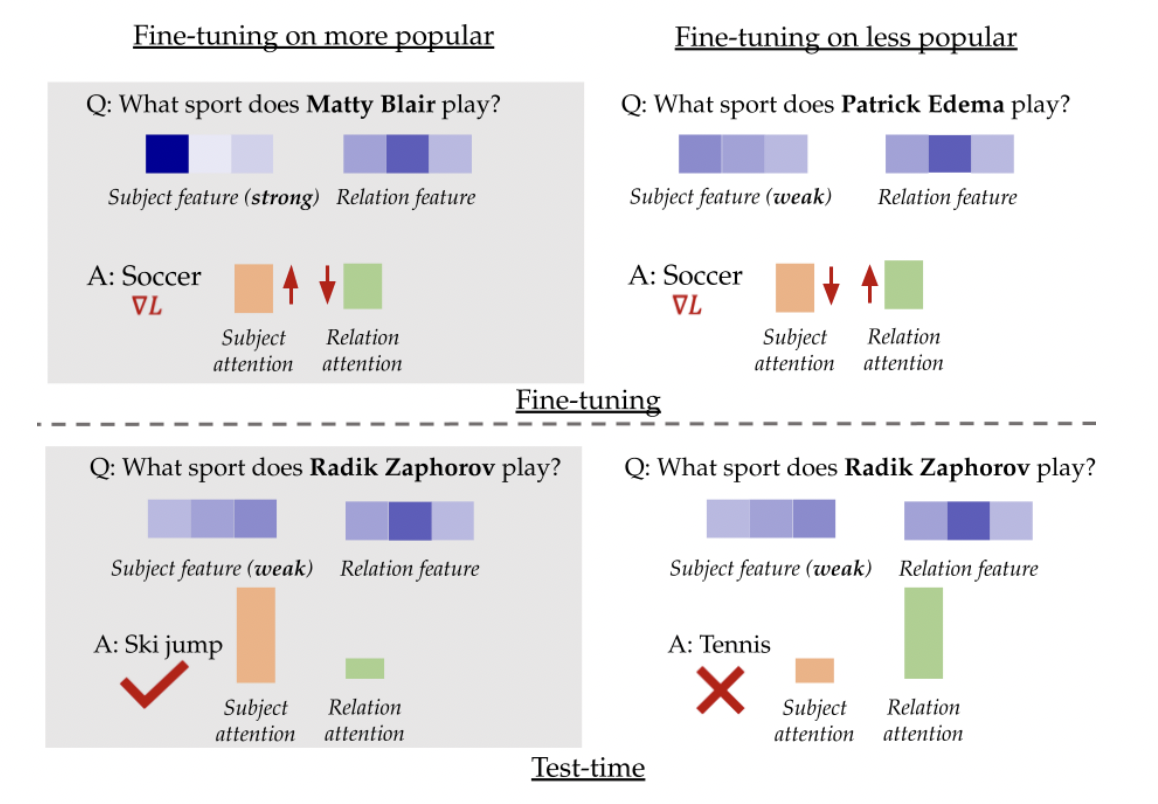
В данном исследовании исследователи из отдела машинного обучения Карнеги-Меллонского университета и отдела компьютерных наук Стэнфордского университета обнаружили, что влияние примеров тонкой настройки на LLM зависит критически от того, насколько хорошо факты закодированы в предварительно обученной модели. Тонкая настройка на хорошо закодированные факты значительно улучшает фактическую точность, в то время как использование менее хорошо закодированных фактов может нанести вред производительности. Это происходит потому, что LLM могут использовать запомненные знания или полагаться на общие «примочки» для ответов на вопросы. Состав тонкой настройки данных определяет, какой механизм усиливается. Хорошо известные факты укрепляют использование запомненных знаний, в то время как менее знакомые факты поощряют использование «примочек». Это открытие предоставляет новую перспективу на улучшение фактической точности LLM через стратегический выбор данных для тонкой настройки.
Метод использует синтетическую настройку для изучения влияния данных тонкой настройки на фактическую точность LLM. Эта настройка имитирует упрощенное токенизированное пространство для субъектов, отношений и ответов с различным форматированием между предварительным обучением и последующими задачами. Предварительные образцы выбираются из распределения Ципфа для субъектов и равномерного распределения для отношений. Ключевые результаты показывают, что тонкая настройка популярных фактов значительно улучшает фактическую точность, с усиленным эффектом для менее популярных сущностей. Исследование изучает влияние параметра распределения Ципфа и предварительных шагов на это явление. Эти наблюдения приводят к концепции «фактической выразительности», представляющей, насколько хорошо модель знает факт, что влияет на поведение тонкой настройки и производительность последующих задач. Этот синтетический подход позволяет провести контролируемое исследование процессов предварительного обучения, которое было бы непрактично с реальными большими языковыми моделями.
Экспериментальные результаты на нескольких наборах данных (PopQA, Entity-Questions и MMLU) и моделях (Llama-7B и Mistral) последовательно показывают, что тонкая настройка на менее популярные или менее уверенные примеры работает хуже по сравнению с использованием популярных знаний. Эта разница в производительности увеличивается для менее популярных тестовых точек, подтверждая гипотезу о том, что менее популярные факты более чувствительны к выбору тонкой настройки. Удивительно, даже случайно выбранные подмножества превосходят тонкую настройку на наименее популярные знания, что указывает на то, что включение некоторых популярных фактов может смягчить негативное влияние менее популярных. Кроме того, обучение на более маленьком подмножестве самых популярных фактов часто работает сравнимо или лучше, чем использование всего набора данных. Эти результаты указывают на то, что тщательный выбор данных для тонкой настройки, с фокусом на хорошо известных фактах, может привести к улучшению фактической точности в LLM, потенциально позволяя более эффективным и эффективным процессам обучения.
Исследование предоставляет значительные инсайты в улучшение фактической точности языковых моделей через стратегическое составление набора данных для вопросно-ответных систем. Вопреки интуитивным предположениям, тонкая настройка на хорошо известные факты последовательно улучшает общую фактическую точность. Это открытие, наблюдаемое в различных условиях и подкрепленное концептуальной моделью, вызывает сомнения в традиционных подходах к проектированию набора данных для вопросно-ответных систем. Исследование открывает новые возможности для улучшения производительности языковых моделей, предлагая потенциальные преимущества в техниках регуляризации для преодоления дисбаланса внимания, стратегиях куррикулярного обучения и разработке синтетических данных для эффективного извлечения знаний. Эти результаты являются основой для будущей работы, направленной на улучшение фактической точности и надежности языковых моделей в различных приложениях.
Практические советы:
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Rethinking QA Dataset Design: How Popular Knowledge Enhances LLM Accuracy. Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI. Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ. Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI. На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram. Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.
«`

























