Решение проблемы «churn» в глубоком обучении с подкреплением
Проблема:
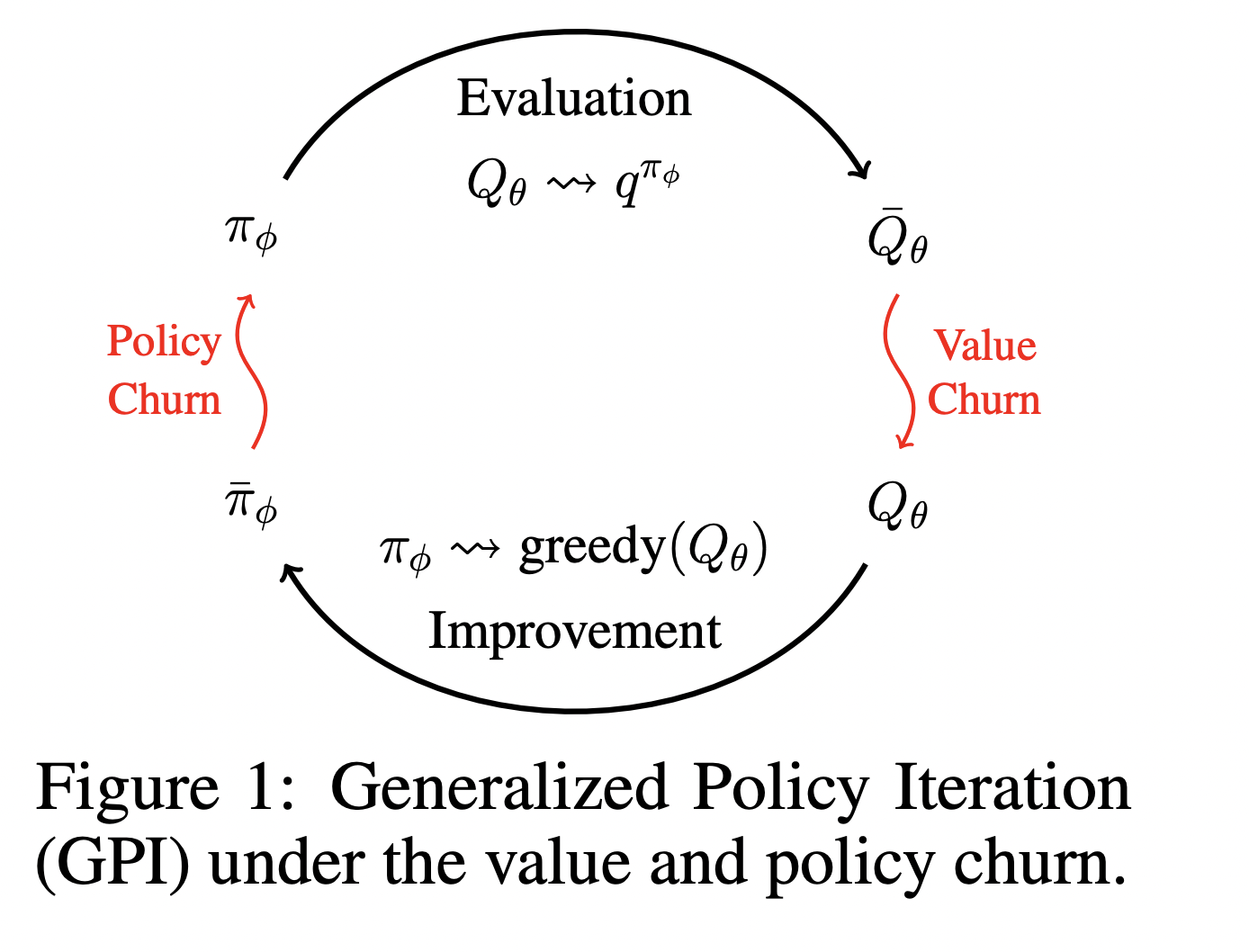
В глубоком обучении с подкреплением (DRL) «churn» вызывает нестабильность из-за непредсказуемых изменений в выходах нейронных сетей для состояний, которые не включены в обучающий набор. Это приводит к значительным неустойчивостям в обучении, вызывая неэффективные обновления как оценок значений, так и политик, что может привести к неэффективному обучению, субоптимальной производительности и даже катастрофическим сбоям.
Решение:
Метод CHAIN (Churn Approximated ReductIoN) целенаправленно снижает «churn» для значений и политик, вводя потери регуляризации во время обучения. CHAIN уменьшает нежелательные изменения в выходах сети для состояний, не включенных в текущий пакет данных, эффективно контролируя «churn» в различных средах DRL. Этот метод улучшает стабильность алгоритмов обучения как на основе значений, так и на основе политик.
Преимущества:
Применение CHAIN приводит к значительному улучшению эффективности обучения и стабильности в средах DRL. Интеграция CHAIN с алгоритмом DoubleDQN в задачах MinAtar’s Breakout и с PPO в средах MuJoCo’s Ant-v4 и HalfCheetah-v4 показала улучшение производительности и стабильности обучения по сравнению с базовыми методами.
CHAIN представляет собой практичное решение для улучшения надежности и эффективности обучения в различных сценариях обучения с подкреплением. Его простота интеграции и способность к контролю «churn» делают его важным инструментом для создания более надежных и масштабируемых систем ИИ.

























