Индуктивные предпочтения в глубоком обучении: Понимание представления признаков
Исследования в области машинного обучения направлены на изучение представлений, способствующих эффективной производительности последующих задач. Растущая подобласть стремится интерпретировать роли этих представлений в поведении модели или изменять их для улучшения соответствия, интерпретируемости или обобщения. Подобно этому, нейронаука изучает нейрональные представления и их поведенческие корреляции. Обе области сосредотачиваются на понимании или улучшении вычислительных систем, абстрактных паттернов поведения в задачах и их реализации. Взаимосвязь между представлением и вычислением сложна и требует более простого подхода.
Практические решения и ценность
Глубокие сети с высокой степенью параметризации часто обобщают хорошо, несмотря на их способность к запоминанию, что указывает на неявное индуктивное предпочтение к простоте в их архитектуре и динамике обучения на основе градиентов. Сети, склонные к более простым функциям, облегчают обучение более простым признакам, что может повлиять на внутренние представления даже для сложных признаков. Предпочтения в представлении благоприятствуют простым, общим признакам, под влиянием таких факторов, как распространенность признака и позиция вывода в трансформаторах. Исследования по быстрому обучению и разделенным представлениям подчеркивают, как эти предпочтения влияют на поведение сети и обобщение.
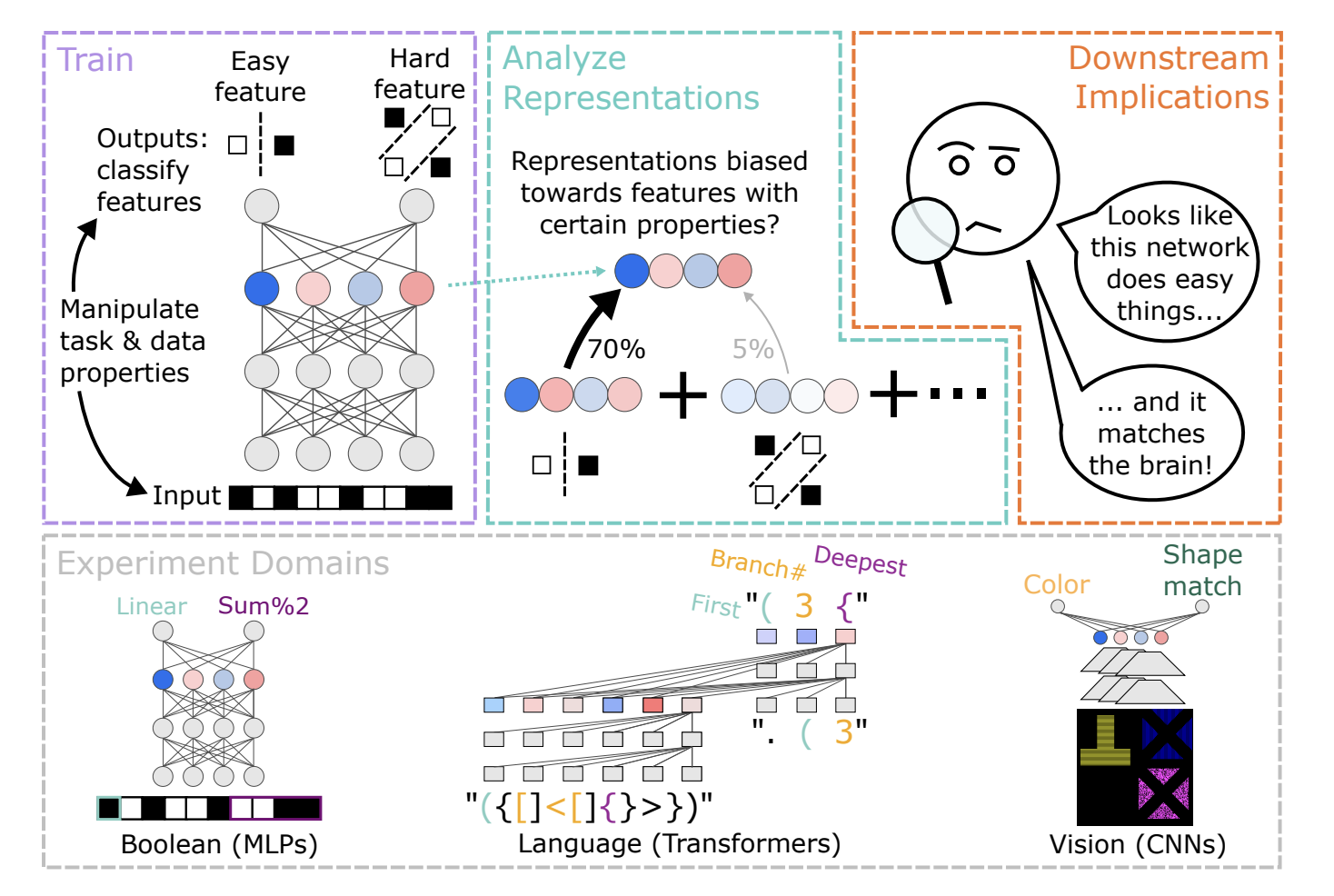
В данной работе исследователи DeepMind исследуют диссоциации между представлением и вычислением, создавая наборы данных, соответствующие вычислительным ролям признаков при манипулировании их свойствами. Различные архитектуры глубокого обучения обучаются вычислять несколько абстрактных признаков из входов. Результаты показывают систематические предпочтения в представлении признаков на основе свойств, таких как сложность признака, порядок обучения и распределение признаков. Проще или ранее выученные признаки представлены сильнее, чем сложные или позднее выученные. Эти предпочтения зависят от архитектур, оптимизаторов и режимов обучения, таких как трансформаторы, благоприятствующие признакам, декодированным ранее в последовательности вывода.
Их подход включает обучение сетей классифицировать несколько признаков либо через отдельные выходные блоки (например, MLP), либо как последовательность (например, трансформатор). Наборы данных созданы для обеспечения статистической независимости между признаками, с моделями, достигающими высокой точности (>95%) на тестовых наборах, подтверждая правильное вычисление признаков. Исследуется, как свойства, такие как сложность признака, распространенность и позиция в последовательности вывода, влияют на представление признака. Создаются семейства обучающих наборов данных для систематического манипулирования этими свойствами, с соответствующими проверочными и тестовыми наборами данных, обеспечивающими ожидаемое обобщение.
Обучение различных архитектур глубокого обучения для вычисления нескольких абстрактных признаков показывает систематические предпочтения в представлении признаков. Эти предпочтения зависят от внешних свойств, таких как сложность признака, порядок обучения и распределение признаков. Проще или ранее выученные признаки представлены сильнее, чем сложные или позднее выученные, даже если все они выучены одинаково хорошо. Архитектуры, оптимизаторы и режимы обучения, такие как трансформаторы, также влияют на эти предпочтения. Эти результаты характеризуют индуктивные предпочтения градиентного представления и подчеркивают проблемы в разделении внешних предпочтений от вычислительно важных аспектов для интерпретации и сравнения с представлениями мозга.
В данной работе исследователи обучали модели глубокого обучения вычислять несколько входных признаков, выявляя существенные предпочтения в их представлениях. Эти предпочтения зависят от свойств признаков, таких как сложность, порядок обучения, распространенность в наборе данных и позиция в последовательности вывода. Предпочтения в представлении могут быть связаны с неявными индуктивными предпочтениями в глубоком обучении. Практически эти предпочтения создают вызовы для интерпретации выученных представлений и их сравнения между различными системами в машинном обучении, когнитивной науке и нейронауке.
Практические решения
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Inductive Biases in Deep Learning: Understanding Feature Representation.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram.
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























