“`html
Понимание уровня галлюцинаций в языковых моделях: Инсайты из обучения на графах знаний и вызовы их обнаружения
Языковые модели (LM) проявляют улучшенную производительность с увеличением размера и обучающих данных, однако связь между масштабом модели и галлюцинациями остается неизученной. Определение галлюцинаций в LM представляет вызовы из-за их разнообразных проявлений. Новое исследование от Google Deepmind фокусируется на галлюцинациях, когда правильные ответы появляются дословно в обучающих данных. Достижение низких уровней галлюцинаций требует более крупных моделей и больших вычислительных ресурсов, чем ранее предполагалось. Обнаружение галлюцинаций становится все более сложным с увеличением размера LM. Графы знаний (KG) предлагают многообещающий подход к предоставлению структурированных фактических обучающих данных для LM, потенциально смягчая галлюцинации.
Практические решения и ценность
Исследование рассматривает связь масштаба языковой модели (LM) и галлюцинаций, сосредотачиваясь на случаях, когда правильные ответы присутствуют в обучающих данных. Используя набор данных на основе графа знаний (KG), исследователи обучают все более крупные LM для эффективного контроля содержания обучения. Находки показывают, что более крупные, долго обученные LM галлюцинируют меньше, но достижение низких уровней галлюцинаций требует значительно больше ресурсов, чем ранее предполагалось. Исследование также показывает обратную связь между масштабом LM и обнаружимостью галлюцинаций.
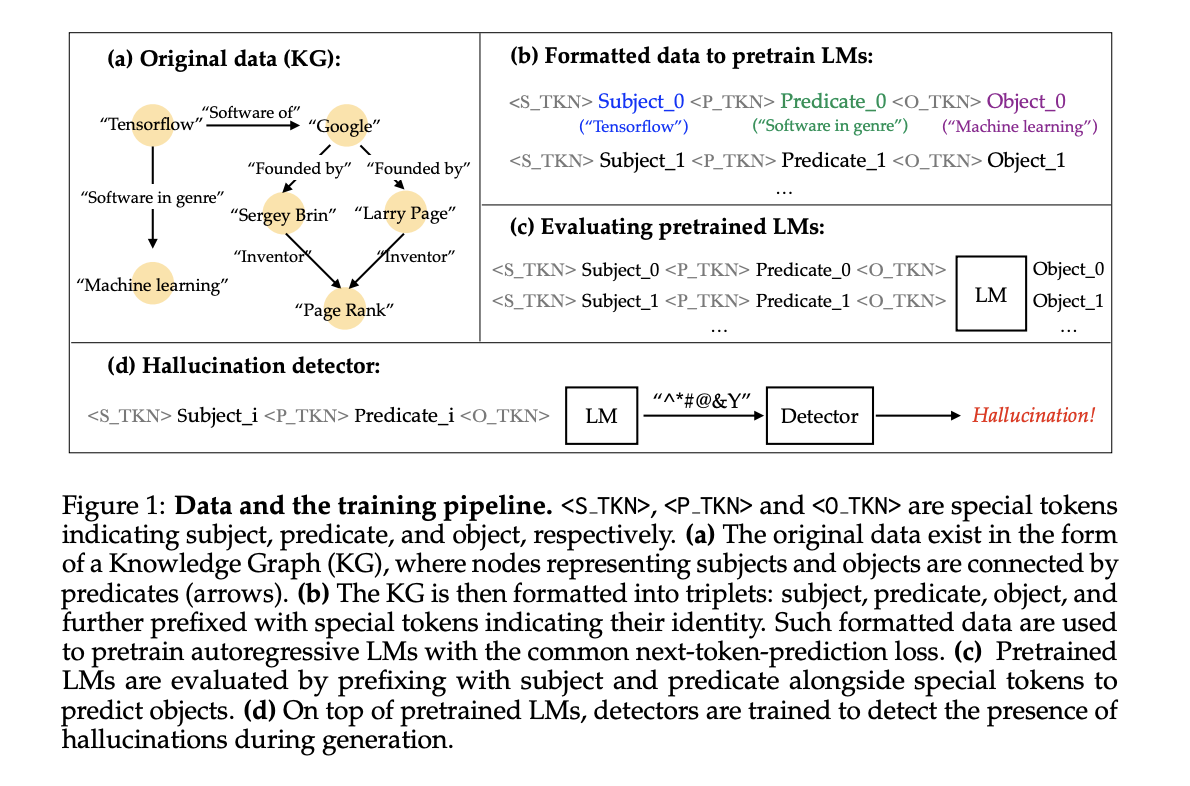
Традиционные языковые модели (LM), обученные на данных естественного языка, часто производят галлюцинации и повторяющуюся информацию из-за семантической неоднозначности. Исследование использует подход на основе графа знаний (KG), используя структурированные тройки информации для более ясного понимания того, как LM искажают обучающие данные. Этот метод позволяет более точно оценить галлюцинации и их связь с масштабом модели.
Исследование создает набор данных с использованием троек графа знаний (субъект, предикат, объект), обеспечивая точный контроль обучающих данных и количественное измерение галлюцинаций. Языковые модели (LM) обучаются с нуля на этом наборе данных, оптимизируя авторегрессионную логарифмическую вероятность. Оценка включает подачу моделям субъекта и предиката, а также оценку точности завершения объекта по сравнению с графом знаний. Задачи с токенами и детекторы головы оценивают производительность обнаружения галлюцинаций. Методология сосредотачивается на галлюцинациях, когда правильные ответы появляются дословно в обучающем наборе, изучая связь масштаба LM и частоты галлюцинаций.
Исследование обучает все более крупные LM для изучения эффектов масштаба на уровни галлюцинаций и их обнаружимость. Анализ показывает, что более крупные, долго обученные LM галлюцинируют меньше, хотя более крупные наборы данных могут увеличить уровни галлюцинаций. Авторы признают ограничения обобщения на все типы галлюцинаций и использование моделей меньшего размера, чем современные. Этот всесторонний подход предоставляет понимание галлюцинаций LM и их обнаружимость, внося вклад в область обработки естественного языка.
В заключение, исследование показывает, что более крупные и долго обученные языковые модели снижают уровни галлюцинаций на фиксированных наборах данных, в то время как увеличение размера набора данных повышает уровни галлюцинаций. Детекторы галлюцинаций показывают высокую точность, улучшаясь с увеличением размера модели. Общий уровень обнаружения токенов, как правило, превосходит другие методы. Существует компромисс между запоминанием фактов и способностью обобщения, при этом продленное обучение минимизирует галлюцинации на видимых данных, но рискует переобучением на невидимых данных. AUC-PR служит надежной мерой производительности детектора. Эти результаты подчеркивают сложную связь между масштабом модели, размером набора данных и уровнями галлюцинаций, подчеркивая важность балансирования размера модели и продолжительности обучения для смягчения галлюцинаций, а также решения вызовов, которые возникают из-за более крупных наборов данных.
Практическое применение исследования
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте исследование “Понимание уровня галлюцинаций в языковых моделях: Инсайты из обучения на графах знаний и вызовы их обнаружения”.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram.
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.
“`









