«`html
Параметр-эффективное донастройка (PEFT) и его роль в развитии техник тонкой настройки
Техники параметр-эффективной донастройки (PEFT) позволяют адаптировать большие языковые модели (LLM) к конкретным задачам, модифицируя небольшой поднабор параметров, в отличие от полной донастройки (FFT), которая обновляет все параметры. PEFT, в частности метод низкоранговой адаптации (LoRA), значительно снижает требования к памяти, обновляя менее 1% параметров и достигая схожей производительности с FFT. LoRA использует низкоранговые матрицы для улучшения производительности без дополнительных вычислительных затрат во время вывода. Объединение этих матриц с исходными параметрами модели позволяет избежать дополнительных затрат на вывод. Множество методов направлено на улучшение LoRA для LLM, в основном подтверждая эффективность через GLUE, достигая лучшей производительности или требуя меньше обучаемых параметров.
Улучшения в LoRA
Улучшения в LoRA включают подход декомпозиции DoRA, дифференциальные скорости обучения в LoRA+ и интеграцию ReLoRA во время обучения. Тонкая настройка LLM включает настройку инструкций, сложные задачи рассуждения и непрерывное предварительное обучение. Большинство вариантов LoRA используют настройку инструкций или задачи GLUE, которые могут не полностью отражать эффективность. Недавние работы тестируют задачи рассуждения, но часто требуют больше обучающих данных, что ограничивает точную оценку.
MoRA: новый метод
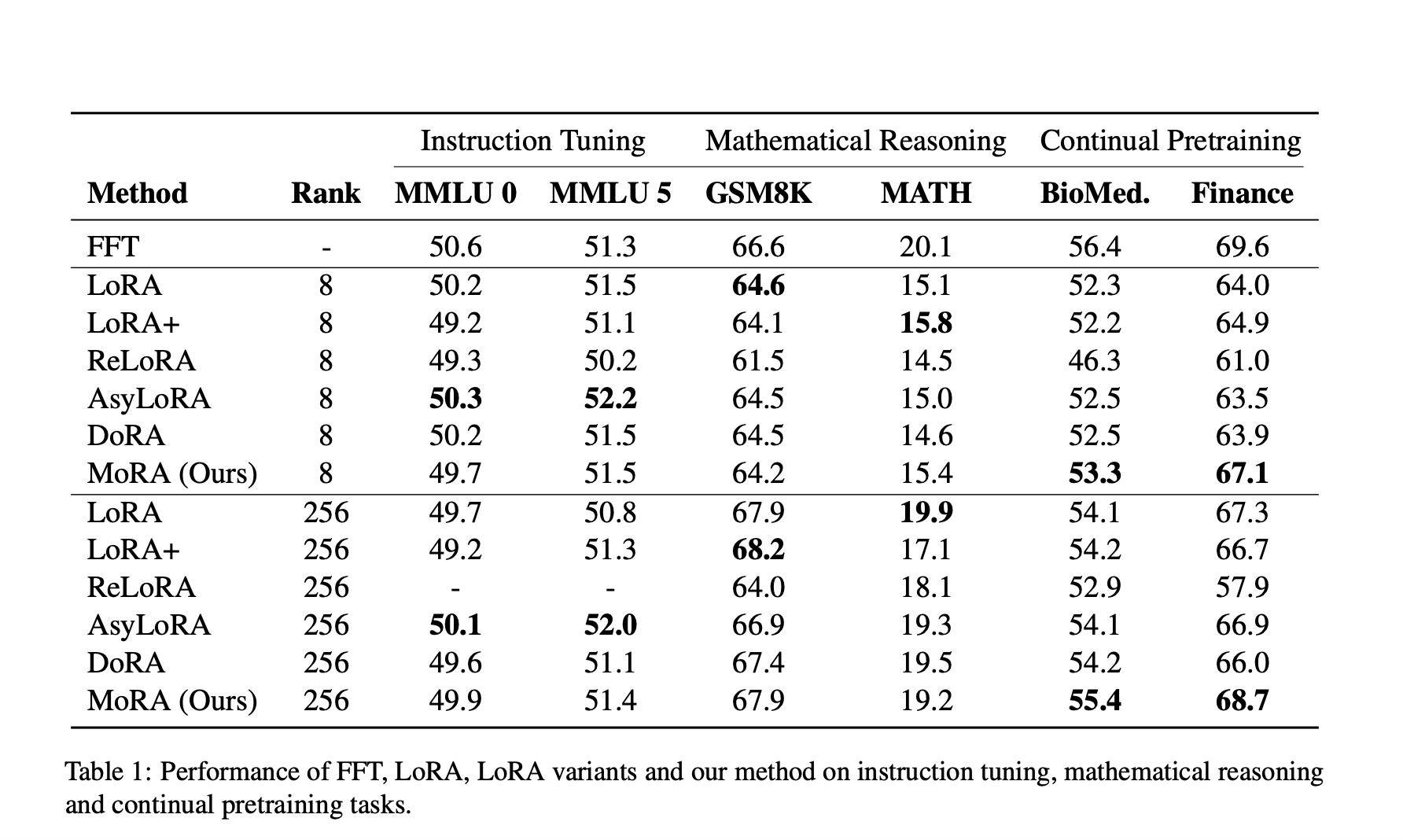
Исследователи из университета Бейханг и корпорации Microsoft представили MoRA. Этот метод использует квадратную матрицу вместо низкоранговых матриц в LoRA для достижения высокорангового обновления с тем же количеством обучаемых параметров. MoRA использует четыре непараметрических оператора для настройки входных и выходных размерностей, обеспечивая возможность объединения весов обратно в LLM. Комплексная оценка по пяти задачам — настройка инструкций, математическое рассуждение, непрерывное предварительное обучение, память и предварительное обучение — демонстрирует эффективность MoRA.
Сравнение MoRA и LoRA
MoRA показывает сходную производительность с LoRA в настройке инструкций и математическом рассуждении, но превосходит LoRA в биомедицинских и финансовых областях благодаря высокоранговому обновлению. Различные варианты LoRA обычно демонстрируют схожую производительность с LoRA, с AsyLoRA выделяющимся в настройке инструкций, но испытывающим трудности в математическом рассуждении. Производительность ReLoRA страдает при более высоких рангах, например, 256, из-за объединения низкоранговых матриц во время обучения. Каждая задача демонстрирует различные требования к тонкой настройке, где ранг 8 достаточен для настройки инструкций, но не подходит для математического рассуждения, требуя увеличения ранга до 256 для сравнения с FFT. В непрерывном предварительном обучении LoRA с рангом 256 все еще отстает от FFT.
Исследование MoRA
В данном исследовании анализируются ограничения низкорангового обновления в LoRA для память-интенсивных задач и предлагается MoRA в качестве решения. MoRA использует непараметризованные операторы для высокорангового обновления и исследует различные методы декомпрессии и компрессии. Сравнение производительности показывает, что MoRA соответствует LoRA в настройке инструкций и математическом рассуждении, превосходя его в непрерывном предварительном обучении и задачах памяти. Эксперименты с предварительным обучением дополнительно подтверждают эффективность высокорангового обновления, демонстрируя превосходные результаты по сравнению с ReLoRA.
Подробнее ознакомиться с исследованием можно в статье.
Все права на это исследование принадлежат его авторам. Также не забудьте подписаться на наш Twitter.
Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится и наша рассылка.
Не забудьте присоединиться к нашему сообществу в Reddit с более чем 42 тысячами подписчиков.
«`

























