«`html
Раскрытие сокращений: влияние генерации с извлечением на поведение языковой модели и использование памяти
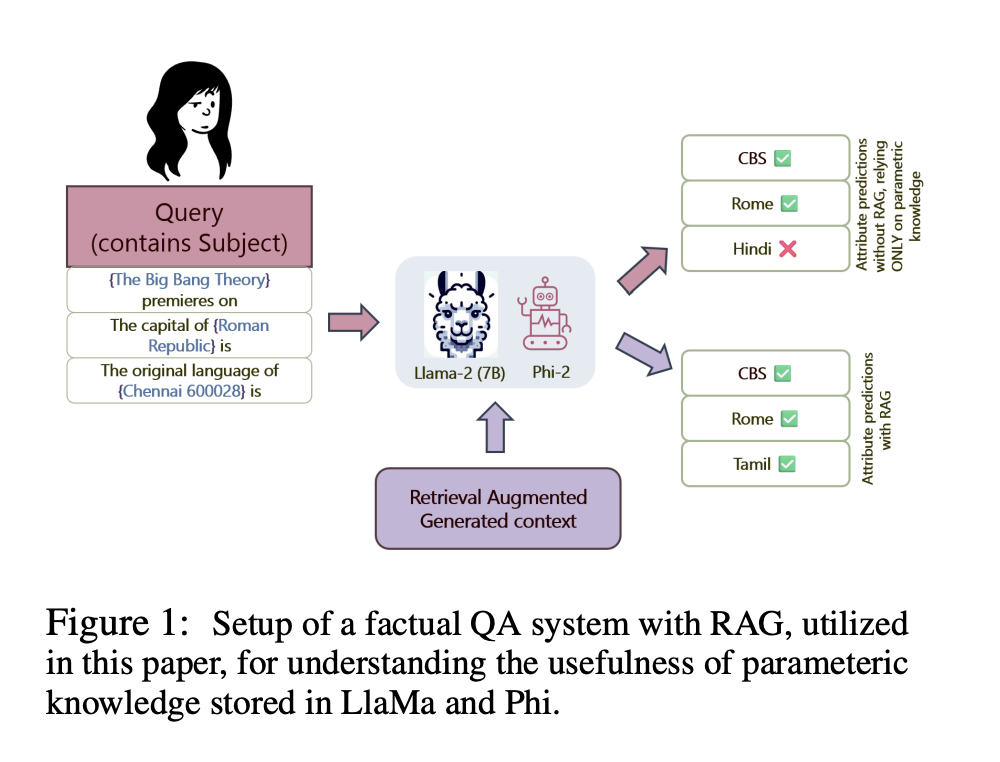
Исследователи из Microsoft, Университета Массачусетса в Амхерсте и Университета Мэриленда в Колледж-Парке рассматривают проблему понимания того, как генерация с извлечением (RAG) влияет на рассуждения и фактическую точность языковых моделей (LMs). Исследование сосредотачивается на том, зависят ли LMs больше от внешнего контекста, предоставленного RAG, чем от их параметрической памяти при генерации ответов на фактические запросы.
Практические решения и ценность
Текущие методы улучшения фактической точности LMs часто включают либо улучшение внутренних параметров моделей, либо использование внешних систем извлечения для предоставления дополнительного контекста во время вывода. Техники, такие как ROME и MEMIT, фокусируются на редактировании внутренних параметров модели для обновления знаний. Однако было ограниченное исследование в том, как эти модели балансируют использование внутреннего (параметрического) знания и внешнего (непараметрического) контекста в RAG.
Исследователи предлагают механистическое исследование конвейеров RAG для определения того, насколько LMs зависят от внешнего контекста по сравнению с их внутренней памятью при ответе на фактические запросы. Они используют две передовые LMs, LLaMa-2 и Phi-2, для проведения своего анализа, используя методы, такие как анализ причинно-следственных связей, вклад внимания и блокировка внимания.
Исследователи использовали три ключевые техники для управления внутренними процессами LMs в рамках RAG:
- Причинный анализ идентифицирует скрытые состояния в модели, которые критически важны для фактических предсказаний.
- Вклад внимания рассматривает веса внимания между токеном-субъектом и последним токеном в выводе.
- Блокировка внимания включает установку критически важных весов внимания на отрицательную бесконечность для блокирования потока информации между конкретными токенами.
Результаты показали, что в присутствии контекста RAG обе модели LLaMa-2 и Phi-2 показали значительное снижение зависимости от своей внутренней параметрической памяти. Средний косвенный эффект токенов-субъектов в запросе был заметно ниже при наличии контекста RAG. Внимание и блокировка внимания также подтвердили, что модели придавали большее значение внешнему контексту для фактических предсказаний. Однако точная природа того, как это происходит, пока не ясна.
В заключение, предложенный метод демонстрирует, что языковые модели проявляют «сокращенное» поведение, сильно полагаясь на внешний контекст, предоставленный RAG, перед своей внутренней параметрической памятью для фактических запросов. Путем механистического анализа того, как LMs обрабатывают и приоритизируют информацию, исследователи предоставляют ценные идеи о взаимодействии параметрического и непараметрического знания в генерации с извлечением. Исследование подчеркивает необходимость понимания этих динамик для улучшения производительности модели и ее надежности в практических приложениях.
«`

























