Оптимизация сравнения предложений большого масштаба: как SBERT (Sentence-BERT) сокращает вычислительное время, сохраняя высокую точность в задачах семантической текстовой схожести
Исследователи сосредоточились на разработке и построении моделей для эффективной обработки и сравнения человеческого языка в области обработки естественного языка. Одной из ключевых областей исследований являются векторные представления предложений, которые преобразуют предложения в математические векторы для сравнения их семантических значений. Эта технология критически важна для семантического поиска, кластеризации и задач вывода естественного языка. Модели, обрабатывающие такие задачи, могут значительно улучшить системы вопрос-ответ, разговорные агенты и классификацию текста. Однако, несмотря на прогресс в этой области, масштабируемость остается основным вызовом, особенно при работе с большими наборами данных или приложениями в реальном времени.
Проблема и решение
Проблема в обработке текста возникает из-за вычислительной сложности сравнения предложений. Традиционные модели, такие как BERT и RoBERTa, устанавливают новые стандарты для сравнения пар предложений, но они сами по себе медленны для задач, требующих обработки больших наборов данных. Например, поиск наиболее похожей пары предложений в коллекции из 10 000 предложений с использованием BERT требует около 50 миллионов вычислительных операций, что может занять до 65 часов на современных графических процессорах. Неэффективность этих моделей создает значительные препятствия для масштабирования анализа текста, делая их непрактичными для многих крупномасштабных приложений, таких как веб-поиск или автоматизация поддержки клиентов.
Предыдущие попытки решить эти проблемы использовали различные стратегии, но большинство из них идут на компромисс в производительности ради эффективности. Например, некоторые методы включают отображение предложений в векторное пространство, где семантически похожие предложения размещаются ближе друг к другу. Хотя это помогает снизить вычислительные затраты, качество получаемых векторных представлений предложений часто страдает. Широко используемый подход усреднения выходных векторов BERT или использование токена [CLS] плохо справляется с этими задачами, давая результаты, иногда хуже, чем у старых, более простых моделей, таких как векторные представления GloVe. Таким образом, поиск решения, которое балансирует вычислительную эффективность с высокой производительностью, продолжается.
Решение SBERT
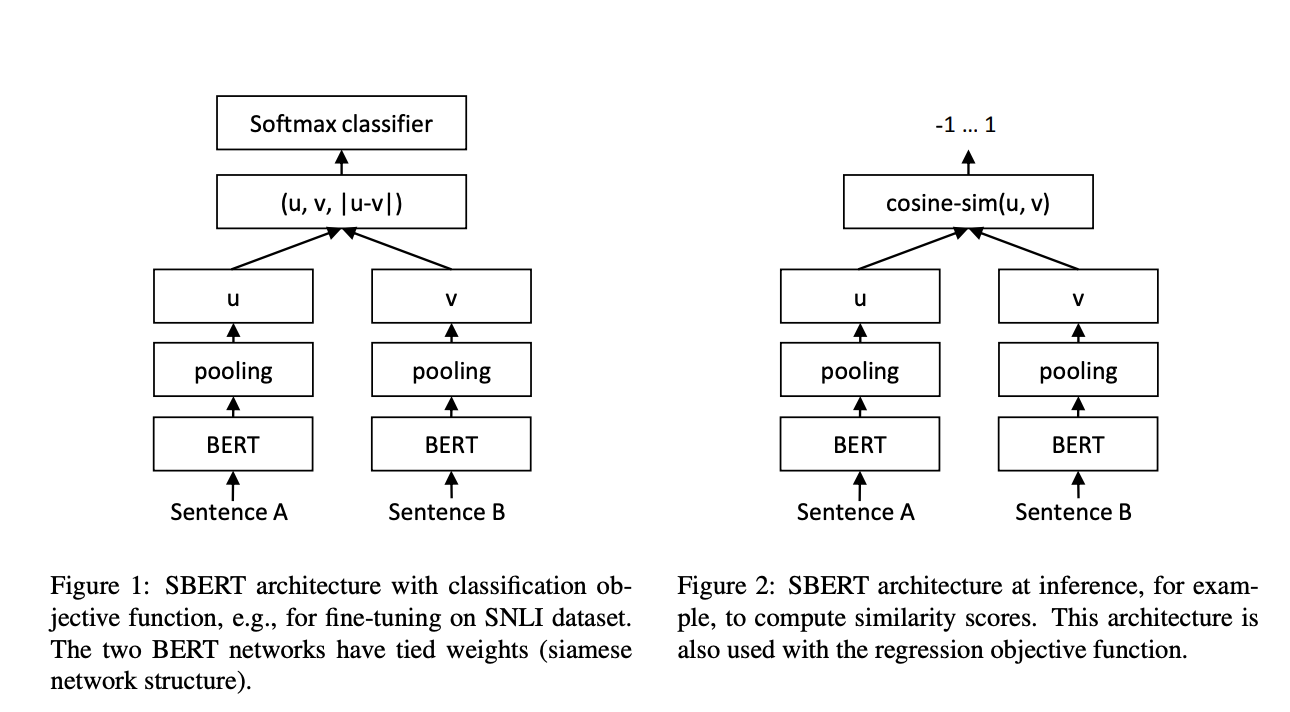
Исследователи из Ubiquitous Knowledge Processing Lab (UKP-TUDA) при Департаменте компьютерных наук Технического университета Дармштадта представили SBERT, модификацию модели BERT, разработанную для обработки векторных представлений предложений более вычислительно эффективным способом. Модель SBERT использует архитектуру сети Сиамских близнецов, которая позволяет сравнивать векторные представления предложений с использованием эффективных мер сходства, таких как косинусное сходство. Исследовательская группа оптимизировала SBERT для сокращения времени вычислений при сравнении предложений в большом масштабе, снизив время обработки с 65 часов до всего 5 секунд для набора из 10 000 предложений. SBERT достигает этой замечательной эффективности, сохраняя уровни точности BERT, доказывая, что скорость и точность могут быть сбалансированы в задачах сравнения пар предложений.
Технология SBERT включает использование различных стратегий пулинга для генерации векторов фиксированного размера из предложений. Стандартная стратегия усредняет выходные векторы (стратегия MEAN), в то время как другие варианты включают максимальный пулинг по времени и использование токена CLS. SBERT был донастроен с использованием большого набора данных из задач вывода естественного языка, таких как корпуса SNLI и MultiNLI. Это донастройка позволила SBERT превзойти предыдущие методы векторных представлений предложений, такие как InferSent и Universal Sentence Encoder, по нескольким бенчмаркам. На семи общих задачах семантической текстовой схожести (STS) SBERT улучшился на 11,7 пункта по сравнению с InferSent и на 5,5 пункта по сравнению с Universal Sentence Encoder.
Производительность SBERT не ограничивается только скоростью. Модель продемонстрировала превосходную точность на нескольких наборах данных. В частности, на бенчмарке STS SBERT достиг корреляции рангов Спирмена 79,23 для базовой версии и 85,64 для большой версии. В сравнении с этим InferSent набрал 68,03, а Universal Sentence Encoder — 74,92. SBERT также успешно справился с задачами обучения передачи с использованием набора инструментов SentEval, где он достиг более высоких результатов в задачах предсказания настроения, таких как классификация настроения отзывов о фильмах (84,88% точности) и классификация настроения отзывов о продуктах (90,07% точности). Возможность SBERT донастраивать свою производительность в широком диапазоне задач делает его очень универсальным для реальных приложений.
Преимущества SBERT
Основное преимущество SBERT заключается в его способности масштабировать задачи сравнения предложений, сохраняя высокую точность. Например, он может сократить время, необходимое для поиска наиболее похожего вопроса в большом наборе данных, таком как Quora, с более чем 50 часов с BERT до нескольких миллисекунд с SBERT. Эта эффективность достигается благодаря оптимизированным структурам сети и эффективным мерам сходства. SBERT превосходит другие модели в задачах кластеризации, что делает его идеальным для проектов анализа текста большого масштаба. В вычислительных бенчмарках SBERT обрабатывал до 2042 предложений в секунду на графических процессорах, что на 9% превышает InferSent и на 55% быстрее, чем Universal Sentence Encoder.
Вывод
SBERT значительно улучшает традиционные методы векторных представлений предложений, предлагая вычислительно эффективное и высокоточное решение. Сокращая время, необходимое для задач сравнения предложений с часов до секунд, SBERT решает критическую проблему масштабируемости в обработке естественного языка. Его превосходная производительность на нескольких бенчмарках, включая STS и задачи обучения передачи, делает его ценным инструментом для исследователей и практиков. Благодаря своей скорости и точности, SBERT обязательно станет важной моделью для анализа текста большого масштаба, обеспечивая более быстрый и надежный семантический поиск, кластеризацию и другие задачи обработки естественного языка.

























