“`html
Генерация синтетических данных для обучения больших языковых моделей
Генерация синтетических данных стала ключевым элементом обучения больших языковых моделей (LLM). Это направление фокусируется на создании искусственных наборов данных, имитирующих реальные данные, что позволяет исследователям эффективно обучать и оценивать модели машинного обучения без ущерба для конфиденциальности или необходимости обширного сбора данных. Методология создания синтетических данных направлена на предоставление разнообразных и масштабируемых наборов данных для улучшения устойчивости и производительности LLM в различных приложениях.
Основные вызовы и решения
Основной вызов в генерации синтетических данных заключается в создании разнообразных данных в масштабе. Традиционные методы часто испытывают трудности в поддержании как разнообразия, так и масштабируемости. Методы, основанные на экземплярах, ограничены разнообразием исходного набора данных. Методы, основанные на ключевых точках, пытаются диверсифицировать синтетические данные, используя отобранный список ключевых точек, но этот процесс сложно масштабировать на различные области из-за необходимости исчерпывающей курирования. В результате эти методы часто не могут создать наборы данных, охватывающие широкий спектр сценариев и применений.
Новый подход к созданию синтетических данных
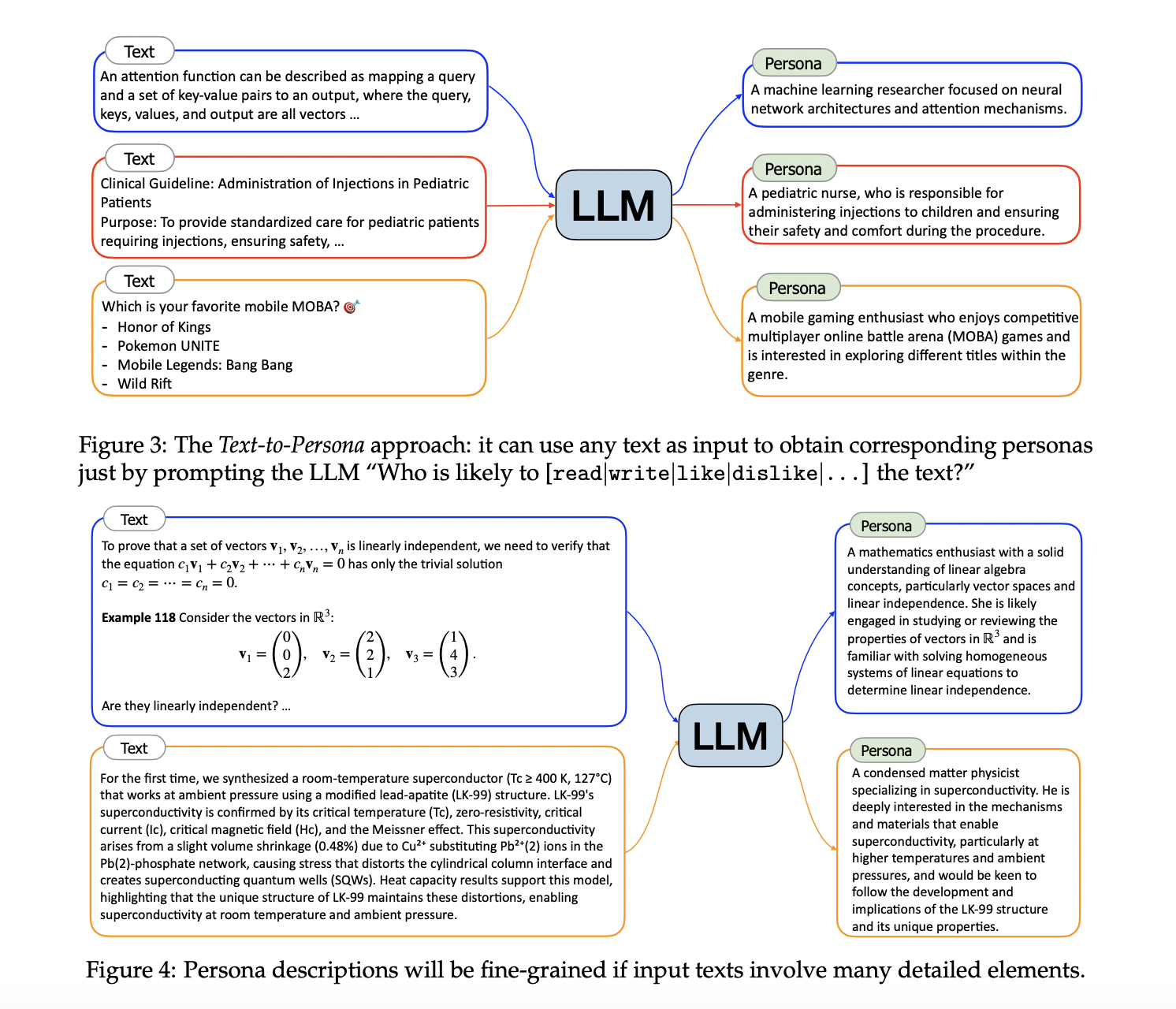
Исследователи из Tencent AI Lab представили Persona Hub – новую методологию синтеза данных, основанную на персонах. Этот подход использует коллекцию из одного миллиарда разнообразных персон, автоматически собранных из веб-данных, для генерации синтетических данных. Persona Hub позволяет LLM создавать данные с различных точек зрения, улучшая разнообразие и масштабируемость. Ассоциируя синтетические данные с конкретными персонами, этот метод может направлять LLM на создание разнообразных и контекстно насыщенных наборов данных, преодолевая ограничения предыдущих методов.
Квантифицированные результаты и перспективы
Персона-ориентированный подход показал впечатляющие количественные результаты. Исследователи создали 50 000 математических задач, 50 000 задач на логическое мышление, 50 000 инструкций, 10 000 текстов с обширными знаниями, 10 000 игровых персонажей и 5 000 инструментов. В рамках оценки модель, настроенная на 1,07 миллиона синтетических математических задач, достигла точности 79,4% на тестовом наборе из 11 600 экземпляров, превзойдя все протестированные LLM с открытым исходным кодом. На MATH бенчмарке модель достигла точности 64,9%, сравнимой с производительностью gpt-4-turbo-preview, демонстрируя значительные улучшения в возможностях LLM через персона-ориентированный синтез данных.
Заключение
Исследователи подчеркнули значительные улучшения в производительности LLM и глубокое влияние персона-ориентированного синтеза данных на обучение и развитие LLM. Путем использования 1 миллиарда персон в Persona Hub исследователи смогли создать разнообразные синтетические наборы данных, значительно улучшающие возможности LLM. Этот метод оказался эффективным в различных сценариях синтеза данных, показывая потенциал стать стандартной практикой в генерации синтетических данных.
“`









