Введение в новые модели вознаграждения процесса
Математическое рассуждение долгое время было сложной задачей для больших языковых моделей (LLM). Ошибки на промежуточных этапах могут снизить точность и надежность конечных результатов, что особенно критично для таких областей, как образование и научные вычисления. Традиционные методы оценки, такие как стратегия Best-of-N (BoN), часто не учитывают нюансы процесса рассуждения.
Что такое модели вознаграждения процесса (PRM)?
Модели вознаграждения процесса (PRM) были разработаны для более детальной оценки правильности промежуточных шагов. Однако создание эффективных PRM остается сложной задачей из-за трудностей с аннотацией данных и методами оценки.
Новые решения от команды Alibaba Qwen
Команда Alibaba Qwen представила модели PRM с 7B и 72B параметрами, которые решают значительные ограничения существующих моделей. Их подход включает:
Гибридная методология
Комбинация методов оценки Монте-Карло (MC) и механизма «LLM в роли судьи» позволяет улучшить качество аннотаций и выявление ошибок в математическом рассуждении.
Ключевые инновации:
- Фильтрация консенсуса: Данные сохраняются только при согласии обеих методик, что уменьшает шум в процессе обучения.
- Жесткая аннотация: Детерминированные метки, подтвержденные обеими методами, улучшают различение корректных и некорректных шагов.
- Эффективное использование данных: Комбинирование методов обеспечивает высококачественные данные даже при меньших объемах.
Результаты и преимущества
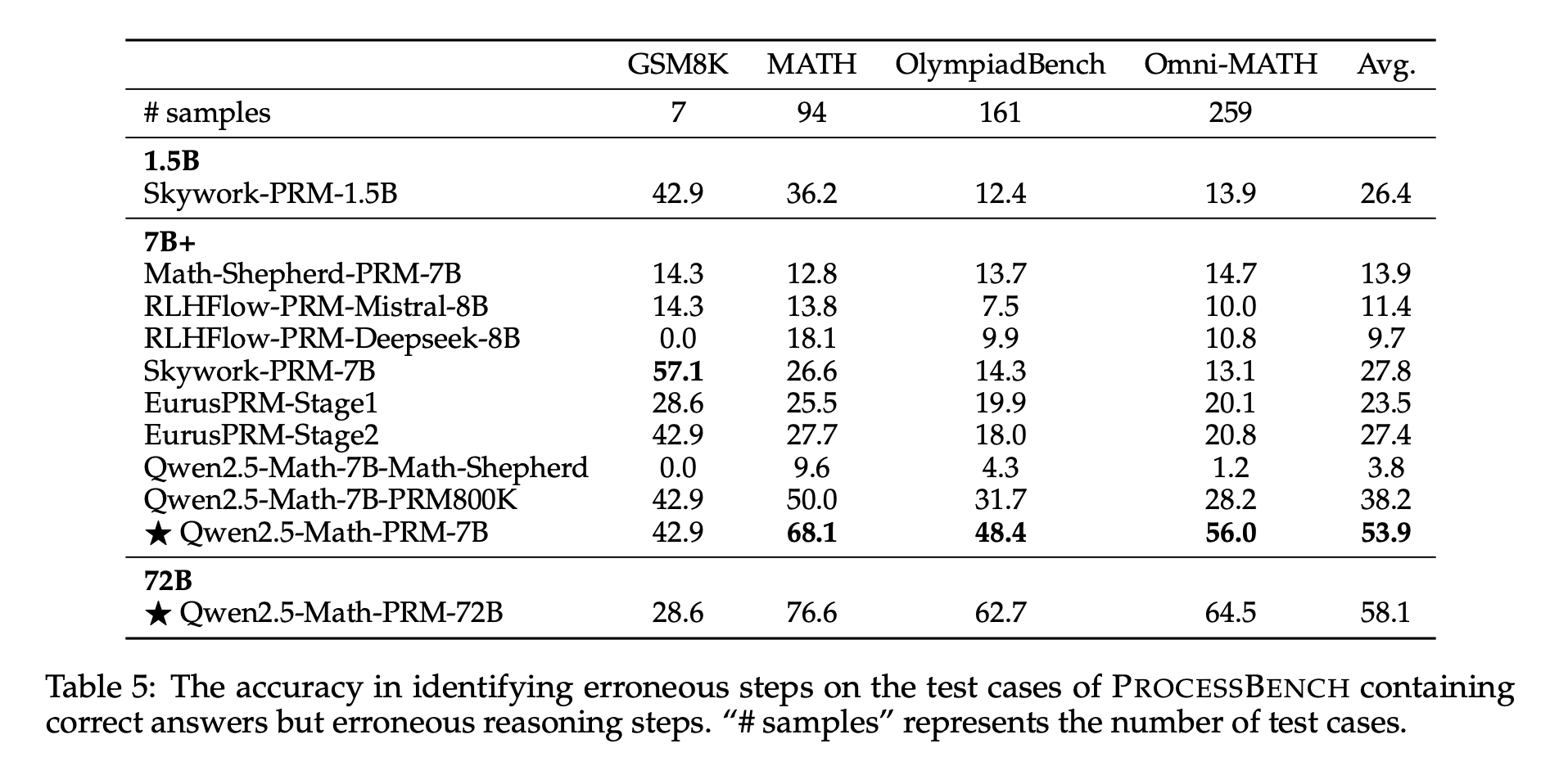
Модели Qwen2.5-Math-PRM показали отличные результаты на тестах, таких как PROCESSBENCH. Например, модель Qwen2.5-Math-PRM-72B достигла F1-оценки 78.3%, что превышает многие альтернативы с открытым исходным кодом.
Преимущества нового подхода:
Фильтрация консенсуса улучшила качество обучения, уменьшив шум данных на 60%. Это позволяет моделям лучше выявлять ошибки на промежуточных этапах.
Заключение
Модели Qwen2.5-Math-PRM представляют собой значительный шаг вперед в области математического рассуждения для LLM. Они предлагают практическую основу для повышения точности и надежности рассуждений. Эти модели не только превосходят существующие альтернативы, но и предоставляют ценные методологии для будущих исследований.
Как адаптировать ИИ для вашего бизнеса
Если вы хотите, чтобы ваша компания развивалась с помощью ИИ, вот несколько шагов:
- Анализируйте, как ИИ может изменить вашу работу.
- Определите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение, учитывая множество доступных ИИ.
- Внедряйте ИИ постепенно, начиная с небольшого проекта и анализируя результаты.
Получите помощь по внедрению ИИ
Если вам нужны советы, пишите нам. Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























