«`html
FocusLLM: масштабируемая ИИ-платформа для эффективной обработки длинных контекстов в языковых моделях
Для многих приложений важно, чтобы LLM могли эффективно обрабатывать длинные контексты, но для этого требуются значительные ресурсы. Длинные контексты улучшают задачи, такие как суммирование документов и ответы на вопросы. Однако существуют несколько проблем: квадратичная сложность трансформеров увеличивает затраты на обучение, LLM нуждаются в помощи с более длинными последовательностями даже после настройки, и получение высококачественных длинных текстовых наборов данных затруднено. Для решения этих проблем были исследованы методы, такие как модификация механизмов внимания или сжатие токенов, но они часто приводят к потере информации, затрудняя точные задачи, такие как верификация и ответы на вопросы.
Решение FocusLLM
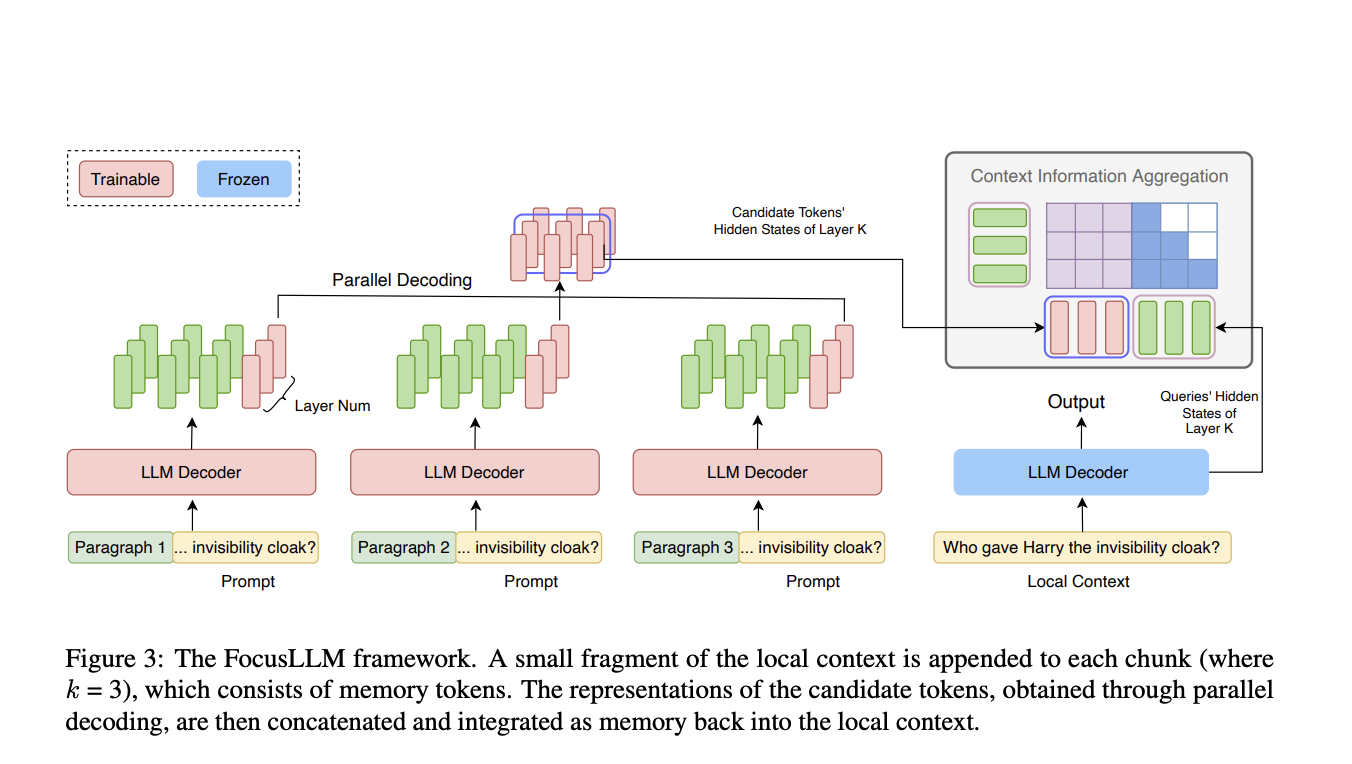
Исследователи из университетов Цинхуа и Сямэнь представили FocusLLM, фреймворк, разработанный для расширения длины контекста только декодирующих LLM. FocusLLM делит длинный текст на части и использует параллельный механизм декодирования для извлечения и интеграции соответствующей информации. Этот подход улучшает эффективность обучения и универсальность, позволяя LLM обрабатывать тексты до 400 тыс. токенов с минимальными затратами на обучение. FocusLLM превосходит другие методы в задачах, таких как ответы на вопросы и понимание длинных текстов, демонстрируя превосходную производительность на бенчмарках Longbench и ∞-Bench, сохраняя при этом низкую перплексию на обширных последовательностях.
Преимущества FocusLLM
FocusLLM обеспечивает значительное улучшение производительности в моделировании языка и в задачах на практике с длинными контекстами. Обученный эффективно на 8×A100 GPU, FocusLLM превосходит LLaMA-2-7B и другие методы без дополнительной настройки, поддерживая стабильную перплексию даже с расширенными последовательностями. На задачах с использованием наборов данных Longbench и ∞-Bench он превзошел модели, такие как StreamingLLM и Activation Beacon. Дизайн FocusLLM, оснащенный параллельным декодированием и эффективной обработкой частей, позволяет ему эффективно обрабатывать длинные последовательности без вычислительной нагрузки других моделей, что делает его высокоэффективным решением для задач с длинным контекстом.
Заключение
FocusLLM представляет собой фреймворк, значительно расширяющий длину контекста LLM с использованием параллельной стратегии декодирования. Этот подход делит длинные тексты на управляемые части, извлекая из каждой необходимую информацию и интегрируя ее в контекст. FocusLLM продемонстрировал превосходную производительность на практических задачах, сохраняя низкую перплексию даже с последовательностями до 400 тыс. токенов. Его дизайн обеспечивает значительную эффективность обучения, позволяя обрабатывать длинные контексты с минимальными вычислительными и памятными затратами. Этот фреймворк предлагает масштабируемое решение для улучшения LLM, делая его ценным инструментом для приложений с длинным контекстом.
«`

























