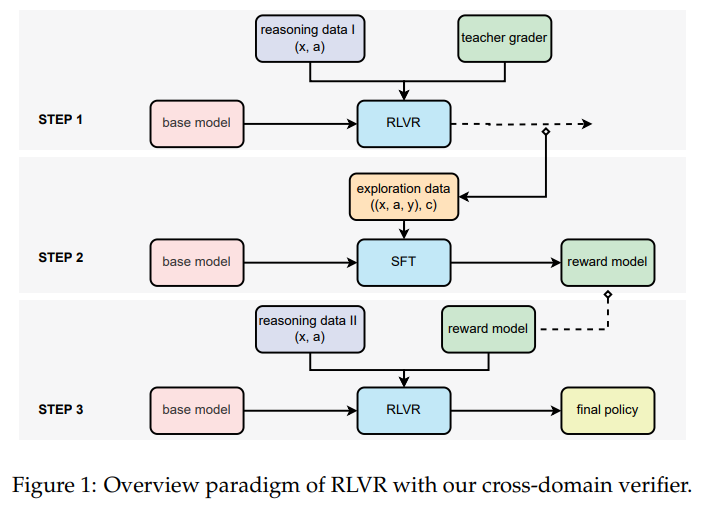
Практические бизнес-решения на основе RLVR
Использование обучения с подкреплением с проверяемыми наградами (RLVR) открывает новые возможности для бизнеса. Давайте рассмотрим, как это может улучшить бизнес и реальную жизнь, а также шаги для внедрения.
Преимущества применения RLVR
- Улучшение точности и эффективности работы AI-систем.
- Расширение возможностей AI в сложных и неструктурированных задачах.
- Снижение затрат на обучение моделей за счет использования компактных моделей.
Рекомендации по внедрению
Шаг 1: Используйте экспертные аннотации
Привлеките экспертов для создания справочных ответов, которые помогут в оценке результатов обучения с подкреплением.
Шаг 2: Обучайте компактные модели
Используйте модели с меньшим количеством параметров (например, 7B), чтобы повысить эффективность без потери производительности.
Шаг 3: Нормализуйте награды
Внедрите нормализацию z-score для обеспечения стабильного обучения и улучшения динамики обучения.
Шаг 4: Проведите пилотные проекты
Начните с небольших проектов, чтобы собрать данные о их эффективности, прежде чем масштабировать решения на основе AI.
Результаты тестирования
Тестирование на больших наборах данных показало, что компактная модель наград (RM-7B) превзошла традиционные методы, особенно в задачах рассуждения. Это подтверждает, что меньшие модели могут приносить значительную пользу.
Заключение
Эволюция RLVR через генеративное моделирование наград предоставляет бизнесу уникальные возможности для улучшения AI-приложений в различных областях. Применяя подходы, основанные на экспертах, и используя компактные модели, организации могут добиться масштабируемых и адаптируемых решений.
Контактная информация
Для получения дополнительной информации о внедрении AI в бизнес-процессы, свяжитесь с нами по адресу hello@itinai.ru.
Дополнительные ресурсы
Подпишитесь на наш Telegram, чтобы быть в курсе последних новостей AI: Telegram.