“`html
Квантованные собственные векторные матрицы для 4-битной вторичной оптимизации глубоких нейронных сетей
Глубокие нейронные сети (DNN) достигли замечательных успехов в различных областях, включая компьютерное зрение, обработку естественного языка и распознавание речи. Однако эффективное обучение крупных моделей сталкивается с вызовами. Вторичные оптимизаторы, такие как K-FAC, Shampoo, AdaBK и Sophia, обладают превосходными свойствами сходимости, но часто вызывают значительные вычислительные и памятные затраты, затрудняя их широкое применение для обучения крупных моделей в рамках ограниченных бюджетов памяти.
Практические решения и ценность:
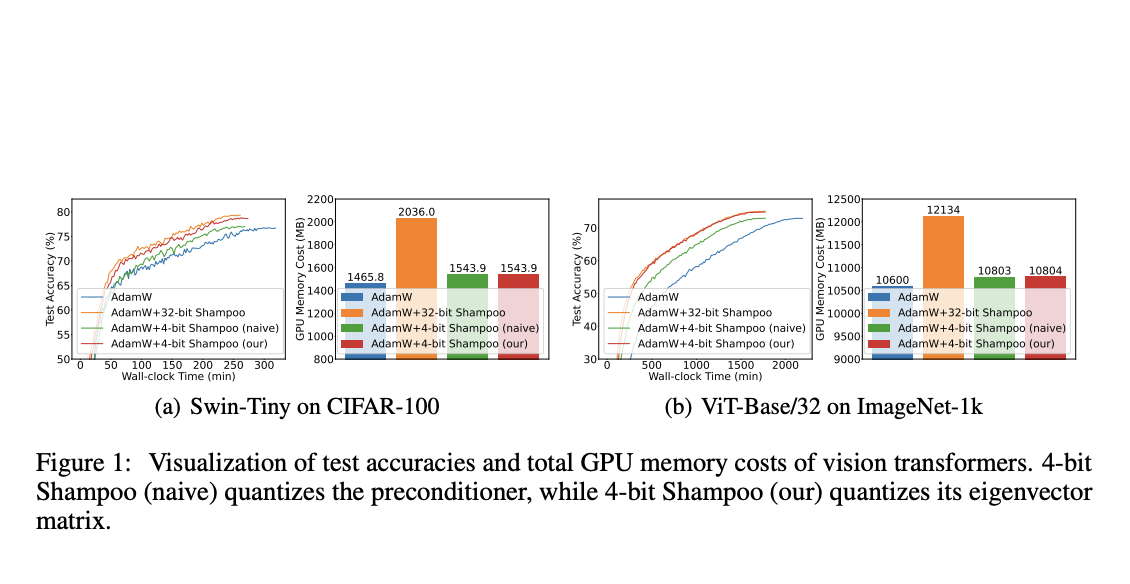
Исследователи из Pекийского Нормального Университета и Сингапурского Университета Менеджмента представляют первый 4-битный вторичный оптимизатор, взяв Shampoo в качестве примера, сохраняя при этом производительность, сравнимую с его 32-битным аналогом. Ключевой вклад заключается в квантовании матрицы собственных векторов предобуславливателя в 4-битном Shampoo вместо прямого квантования самого предобуславливателя. Этот подход сохраняет малые сингулярные значения предобуславливателя, которые критически важны для точного вычисления обратного четвертого корня, тем самым избегая ухудшения производительности.
Дополнительно предложены две техники для улучшения производительности: ортогонализация Бьёрка для исправления ортогональности квантованной матрицы собственных векторов, и линейное квадратичное квантование, превосходящее динамическое дерево квантование для состояний вторичных оптимизаторов.
Проведя тщательные эксперименты, исследователи демонстрируют превосходство предложенного 4-битного Shampoo над оптимизаторами первого порядка, такими как AdamW. В отличие от первообразных методов, требующих 1,2-1,5 раз больше эпох и, следовательно, более длительное время на обучение, 4-битный Shampoo достигает сравнимых результатов тестовой точности с его 32-битным аналогом, обеспечивая при этом значительные экономии памяти.
Данное исследование представляет 4-битный Shampoo, разработанный для эффективного обучения DNN. Квантование матрицы собственных векторов предобуславливателя, вместо самого предобуславливателя, имеет решающее значение для минимизации ошибок квантования в вычислении его обратного четвертого корня с точностью 4 бита. Это связано с чувствительностью малых сингулярных значений, которые сохраняются благодаря квантованию только собственных векторов. Для дальнейшего улучшения производительности введены методы ортогональной ректификации и линейного квадратичного квантования. На различных задачах классификации изображений с использованием различных архитектур DNN 4-битный Shampoo достигает производительности на уровне своего 32-битного аналога, предлагая значительные экономии памяти.
“`









