«`html
Оценка качества разговорных помощников на базе ИИ: практические решения и ценность
Оценка разговорных помощников на базе ИИ, таких как GitHub Copilot Chat, представляет сложность из-за использования моделей языка и чат-интерфейсов. Существующие метрики качества разговора требуют пересмотра для доменно-специфических диалогов, что затрудняет оценку эффективности этих инструментов разработки программного обеспечения. Техники, такие как SPUR, используют большие языковые модели для анализа удовлетворенности пользователей, но могут упускать доменно-специфические нюансы. Исследование фокусируется на автоматическое создание высококачественных, задачно-ориентированных рубрик для оценки разговорных помощников на базе ИИ, подчеркивая важность контекста и прогресса задач для повышения точности оценки.
Техника RUBICON для оценки доменно-специфических разговоров человек-ИИ
Исследователи из Microsoft представляют RUBICON, технику для оценки доменно-специфических разговоров человек-ИИ с использованием больших языковых моделей. RUBICON генерирует кандидатов-рубрик для оценки качества разговора и выбирает лучшие из них. Он улучшает SPUR, интегрируя доменно-специфические сигналы и принципы Грайса, создавая пул рубрик, оцениваемых итеративно. RUBICON был протестирован на 100 разговорах между разработчиками и чат-помощником для отладки C#, используя GPT-4 для генерации и оценки рубрик. Он превзошел альтернативные наборы рубрик, достигнув высокой точности в прогнозировании качества разговора и продемонстрировав эффективность своих компонентов через исследования абляции.
Оценка качества разговора и роль ИИ
Естественные разговоры на естественном языке являются ключевыми для современных приложений ИИ, но традиционные метрики NLP, такие как BLEU и Perplexity, недостаточны для оценки длинных разговоров, особенно в LLMs. В то время как удовлетворенность пользователя была ключевой метрикой, ручной анализ требует больших ресурсов и нарушает приватность. Недавние подходы используют языковые модели для оценки качества разговора через утверждения на естественном языке, захватывая темы вовлеченности и пользовательского опыта. Техники, такие как SPUR, генерируют рубрики для разговоров в открытой области, но нуждаются в более доменно-специфических контекстах. Это исследование подчеркивает целостный подход, интегрируя ожидания пользователей и прогресс взаимодействия, и исследует оптимальный выбор подсказок с использованием бандитских методов для улучшения точности оценки.
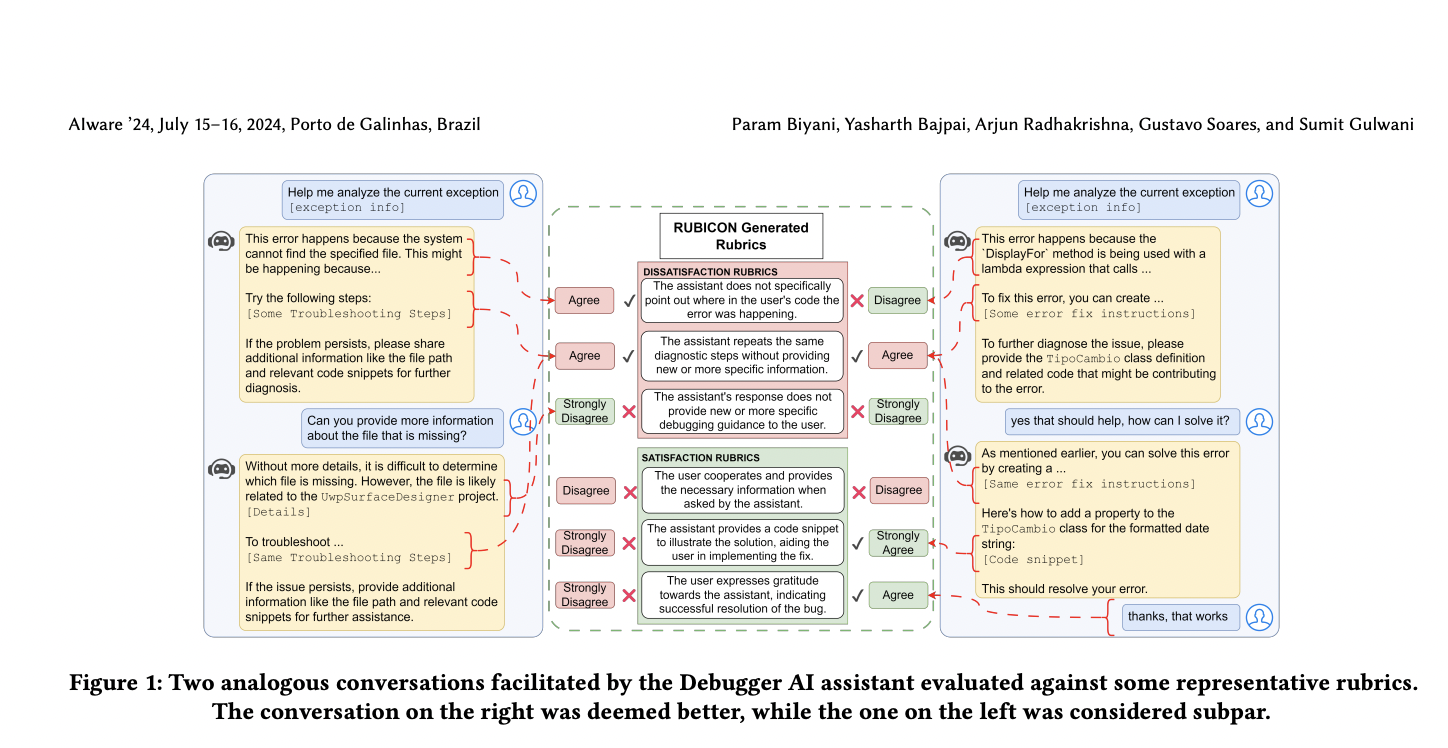
Оценка RUBICON и результаты
RUBICON оценивает качество разговоров для доменно-специфических помощников, изучая рубрики для удовлетворения (SAT) и неудовлетворения (DSAT) по маркированным разговорам. Он включает три этапа: генерацию разнообразных рубрик, выбор оптимального набора рубрик и оценку разговоров. Рубрики — это утверждения на естественном языке, отражающие атрибуты разговора. Разговоры оцениваются с использованием 5-балльной шкалы Ликерта, нормализованной в диапазон [0, 10]. Генерация рубрик включает наблюдаемое извлечение и резюмирование, а выбор оптимизирует рубрики по точности и охвату. Потери корректности и четкости направляют выбор оптимального подмножества рубрик, обеспечивая эффективную и точную оценку качества разговора.
Эффективность и перспективы
Оценка RUBICON включает три ключевых вопроса: его эффективность по сравнению с другими методами, влияние доменной сенсибилизации (DS) и принципов конструкции разговора (CDP), и производительность его политики выбора. Результаты показали, что RUBICON превосходит базовые варианты в разделении положительных и отрицательных разговоров и классификации разговоров с высокой точностью, подчеркивая важность DS и инструкций CDP.
Валидность и дальнейшая работа
Внутренняя валидность оказывается под угрозой из-за субъективного характера ручно присвоенных меток истинности, несмотря на высокое согласие между аннотаторами. Внешняя валидность ограничена отсутствием разнообразия в наборе данных, специфическом для задач отладки C# в компании по разработке программного обеспечения, что может повлиять на обобщение на другие области. Проблемы конструктной валидности включают зависимость от автоматизированной системы оценки и предположения, сделанные при преобразовании ответов на шкале Ликерта в диапазон [0, 10]. Дальнейшая работа будет направлена на различные методы расчета оценки NetSAT. RUBICON доказал свою способность улучшать качество рубрик и дифференцировать эффективность разговоров, что подтверждает его ценность в реальном мире.
Подробнее о статье и деталях. Вся заслуга за это исследование принадлежит его авторам. Также, не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в SubReddit.
Подробнее о статье и деталях. Вся заслуга за это исследование принадлежит его авторам. Также, не забудьте подписаться на нас в Twitter.
Присоединяйтесь к нашему каналу в Telegram и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу в SubReddit.