Nearest Neighbor Speculative Decoding (NEST): метод ревизии на этапе вывода для улучшения фактичности и атрибуции языковых моделей с использованием спекулятивного декодирования ближайших соседей
Большие языковые модели (LLM) доказали свой потенциал в обработке нескольких задач и успешном выполнении различных приложений. Однако для LLM сложно генерировать точную информацию, особенно когда знания в их обучающих данных представлены менее полно. Для преодоления этой проблемы используется метод ретриевального усиления, который объединяет информационный поиск и поиск ближайших соседей из непараметрического хранилища данных, улучшая доказательственное и ситуативное рассуждение с LLM. Это приводит к снижению тенденции в полупараметрических LLM при генерации неподдерживаемого контента.
Практические решения и ценность
Множество работ было проведено для преодоления этих недостатков. Один из существующих методов – Retrieval Augmentation (RA), который использует внешние источники знаний для улучшения производительности LLM в задачах, требующих глубокого понимания. Улучшения в ретриевальном усилении, такие как REALM, RAG и Atlas, интегрируют компонент ретриевала в предварительное обучение и донастройку для этих последующих задач. Другим обсуждаемым методом является спекулятивное декодирование, которое использует небольшую модель для генерации черновиков для большой модели. Самым связанным методом является REST, который берет несколько черновиков из хранилища данных и использует префиксное дерево три для поиска распределения предложений.
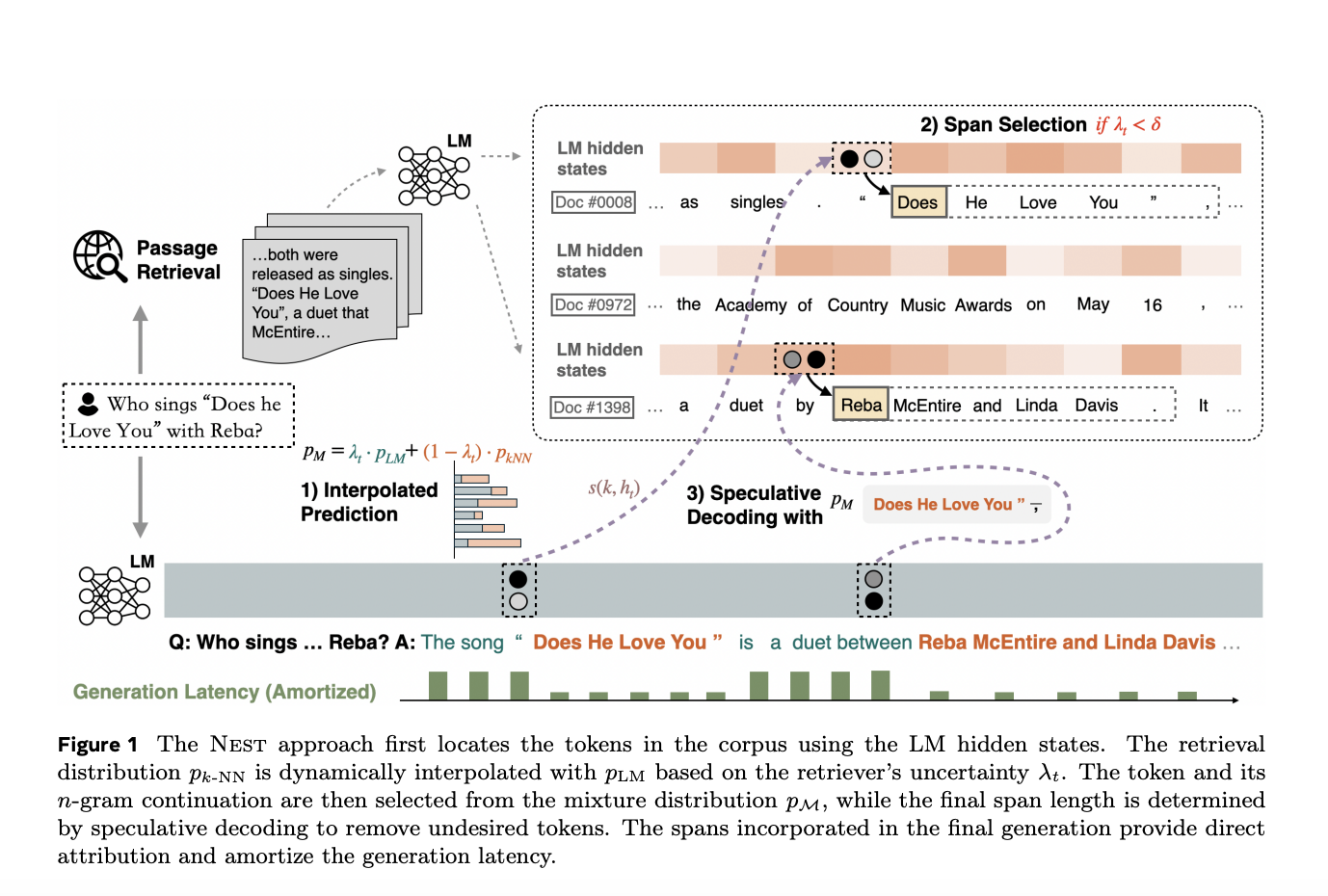
Исследователи из FAIR в Meta, Университета Ватерлоо, Университета Карнеги-Меллона и Университета Чикаго предложили метод ближайшего соседа спекулятивного декодирования (NEST). NEST – новый полупараметрический метод языкового моделирования, который может интегрировать текстовые отрезки реального мира любой длины в генерацию существующей LM, улучшая как качество, так и задержку. NEST расширяет стандартный метод kNN-LM путем интерполяции распределения вывода LM с распределением потенциальных следующих токенов, полученных из корпуса. Изначально он включает дополнительный этап поиска отрывков, что уменьшает необходимость хранения и поиска всех токенов в корпусе, создавая баланс между точностью поиска и эффективностью.
NEST генерирует контент с тремя подэтапами на каждом этапе вывода. Эти шаги:
- Интерполяция на основе уверенности: Оценка относительной уверенности ретриевера токенов используется в качестве коэффициента интерполяции для смеси вероятностей вывода.
- Динамический выбор отрезка: NEST выбирает лучший токен, предсказанный смесью вероятностей, и расширяется, чтобы включить отрезок от этого токена, когда уверенность в поиске токенов превышает порог.
- Расслабленное спекулятивное декодирование: Когда выбран отрезок из нескольких токенов, он оценивается на основе смеси вероятностей, и принимается только префикс, который высокопроблемен согласно смеси вероятностей.
В заключение, исследователи представили NEST, метод ревизии на этапе вывода для LLM, улучшающий их фактичность и атрибуцию с помощью спекулятивного декодирования ближайших соседей. NEST улучшает как проверочную перплексию, так и качество свободной генерации на 9 различных задачах. Однако некоторые ограничения предложенного метода:
- Результаты NEST могут содержать фактические ошибки в зависимости от точности поиска отрывков на первом этапе и поиска токенов на втором этапе.
- Результаты могут быть лучше при донастройке на соответствующие задачи, поскольку интегрированная система без донастройки может быть неоптимальной.
Подробнее ознакомиться с исследованием. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, Discord и группе в LinkedIn.
Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 43k+ ML SubReddit. Также ознакомьтесь с нашей платформой AI Events.
Исходный пост: MarkTechPost
Применение ИИ в бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Nearest Neighbor Speculative Decoding (NEST): метод ревизии на этапе вывода для улучшения фактичности и атрибуции языковых моделей с использованием спекулятивного декодирования ближайших соседей.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram.
Попробуйте ИИ ассистент в продажах здесь. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.
























