«`html
LoRA-Guard: Инновационная система для безопасной генерации контента на основе моделей больших языков
Большие языковые модели (LLM) проявили выдающуюся профессиональную компетентность в задачах генерации языка. Однако их процесс обучения, который включает обучение без учителя на обширных наборах данных, за которым следует контролируемая настройка, представляет существенные трудности. Основная проблема заключается в источниках предварительного обучения, таких как Common Crawl, которые часто содержат нежелательный контент. Результатом этого является неумышленный приобретение LLM способности генерировать оскорбительный контент и потенциально вредные советы. Следовательно, эти модели могут производить связные ответы на пользовательские запросы без должной фильтрации контента.
Существующие подходы к обеспечению безопасности в LLM:
Существующие попытки преодолеть проблемы безопасности в LLM в основном сосредоточены на двух подходах: настройке безопасности и внедрении защитных систем. Настройка безопасности направлена на оптимизацию моделей для реагирования таким образом, чтобы быть согласованными с человеческими ценностями и безопасностью. Однако эти чат-модели остаются уязвимыми для атак «побега из тюрьмы», которые используют различные стратегии для обхода мер безопасности.
LoRA-Guard: Инновационная система для безопасной генерации контента
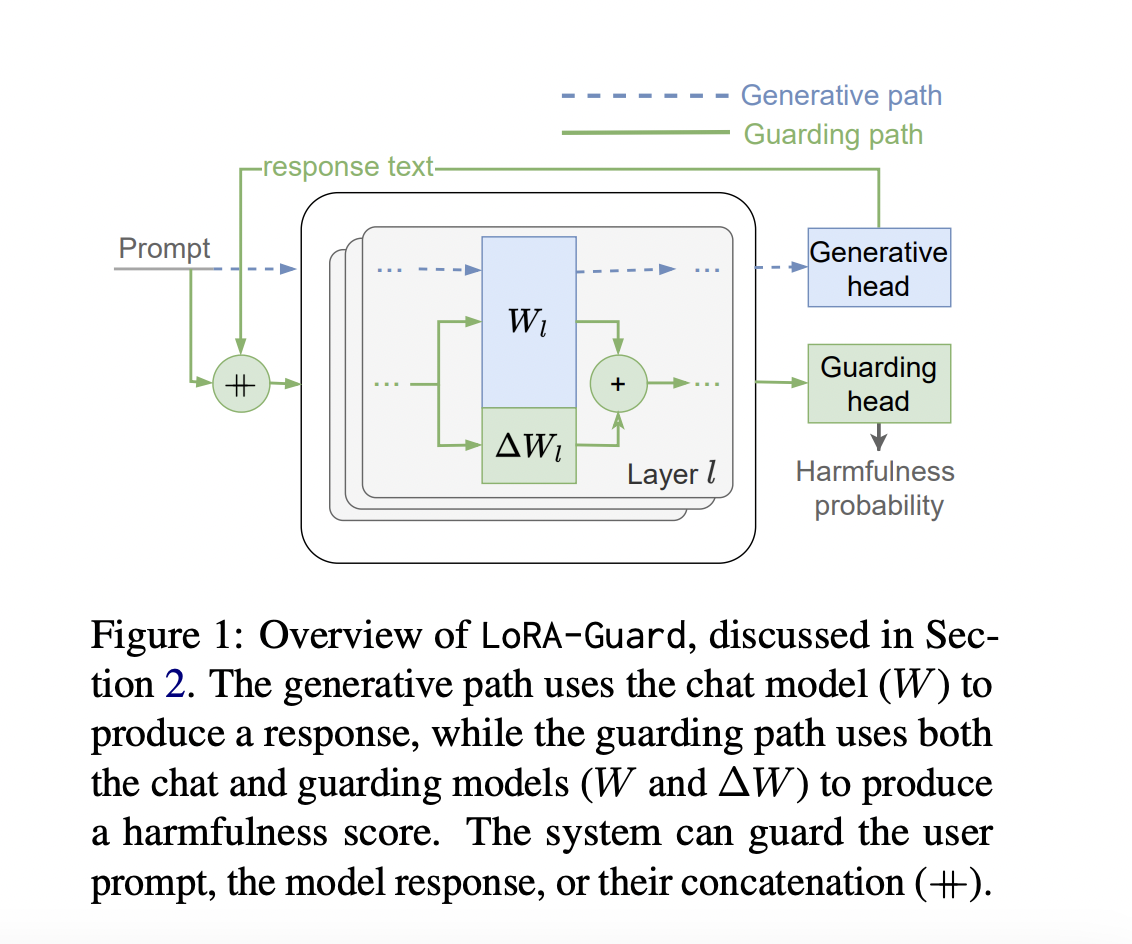
Исследователи Samsung R&D Institute представляют LoRA-Guard — инновационную систему, которая интегрирует чат-модели и защитные модели, решая проблемы эффективности безопасности в LLM.
Он использует адаптивную систему низкого ранга на основе трансформаторной основы чат-модели для обнаружения вредного контента. Система функционирует в двойном режиме: активируя параметры LoRA для защитных функций с помощью классификационной головы и деактивируя их для обычных чат-функций. Этот подход значительно снижает накладные расходы на параметры в 100-1000 раз по сравнению с предыдущими методами, что делает развертывание возможным в условиях ограниченных ресурсов.
Архитектура LoRA-Guard разработана для эффективной интеграции функций защиты в чат-модель. Она использует тот же метод вложения и токенизатор как для чат-модели C, так и для защитной модели G. Ключевая инновация заключается в том, что G использует иной вектор признаков f’, с адаптерами LoRA, прикрепленными к f, а также использует отдельную выходную голову hguard для классификации по категориям вредности.
LoRA-Guard обучается через контролируемую настройку f’ и hguard на размеченных наборах данных, сохраняя параметры чат-модели замороженными. Этот подход использует существующие знания чат-модели, одновременно обучаясь эффективно обнаруживать вредный контент.
LoRA-Guard продемонстрировал исключительную производительность на нескольких наборах данных. На ToxicChat он превосходит базовые показатели AUPRC, используя значительно меньше параметров — до 1500 раз меньше, чем у полностью настроенных моделей.
Если вам интересно наше изучение, вы полюбите нашу рассылку.
«`

























