«`html
Strategic Chain-of-Thought (SCoT): Уникальный метод ИИ, разработанный для улучшения производительности и рассуждений крупных языковых моделей (LLM) через выявление стратегии
Один из важных методов улучшения способности больших языковых моделей к рассуждению — это парадигма Chain-of-Thought (CoT). Путем поощрения моделей делить задачи на промежуточные этапы, подобно тому, как люди методично подходят к сложным проблемам, CoT улучшает процесс решения проблем. Этот метод доказал свою крайнюю эффективность во многих областях, что привело к его ключевому положению в обществе обработки естественного языка (NLP).
Решение
Недостатком CoT является то, что он не всегда создает пути рассуждения высокого качества. Производительность рассуждений может страдать из-за неоптимальных путей, создаваемых LLM с применением CoT. Это происходит потому, что LLM не всегда генерируют промежуточные шаги с использованием логической или эффективной техники рассуждения, что приводит к изменчивости в конечных результатах. Нет гарантии точности результата, даже если был создан допустимый путь, из-за возможности ошибок или неэффективного рассуждения.
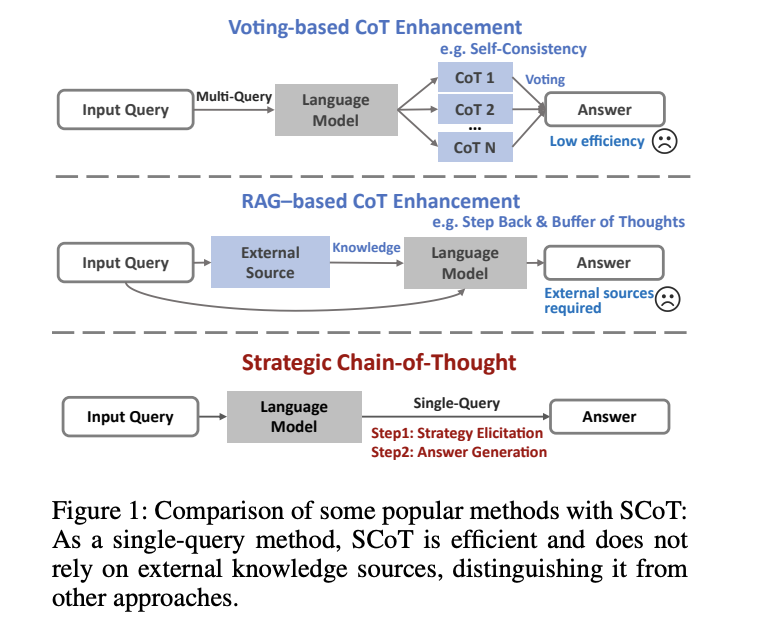
Недавно была разработана стратегическая техника Chain-of-Thought (SCoT) как средство решения этой проблемы путем повышения качества и последовательности рассуждений в LLM. Добавляя стратегические знания перед созданием путей рассуждения, SCoT вводит организованный метод рассуждения. Это стратегическое обучение помогает обеспечить, что промежуточные фазы модели имеют смысл и соответствуют более эффективному способу решения проблем.
Операция SCoT включает два этапа в одной команде. Она начинается с определения того, какая техника решения проблем наиболее подходит для текущей задачи. Этот первый этап заложил основу для создания более точного и отточенного пути рассуждения. После того как стратегия была выбрана, LLM следует ей, чтобы создать окончательные ответы и пути CoT высшего качества. С акцентом на организованный подход к решению проблем, SCoT стремится устранить значительную часть изменчивости, которая часто мешает обычным техникам CoT.
Были проведены эксперименты на восьми сложных наборах данных для оценки эффективности SCoT. Результаты показали большое обещание и значительный прирост производительности. На наборе данных GSM8K, который подчеркивает математическое рассуждение, модель показала улучшение точности на 21,05%. На наборе данных Tracking Objects, который включает пространственное рассуждение, модель достигла увеличения на 24,13%. Для наблюдения за этими улучшениями использовалась модель Llama3-8b, демонстрируя адаптивность SCoT во многих сценариях рассуждения.
Для дальнейшего улучшения производительности модели SCoT был расширен для включения техники обучения с малым количеством обучающих примеров в дополнение к его обычной структуре. В этом случае модель может черпать из предыдущих примеров, наилучшим образом подходящих для текущей задачи, автоматически выбирая подходящие примеры для задач с малым количеством обучающих примеров на основе стратегических знаний. Еще более хорошие результаты от этого расширения показали, насколько гибким и адаптивным является SCoT в управлении различными задачами рассуждения с меньшим количеством данных.
Команда суммировала свои основные вклады следующим образом.
- Был предложен новый метод, включающий стратегическую информацию в процесс рассуждения. Этот двухэтапный процесс находит эффективный подход к решению проблем и затем направляет создание улучшенных путей Chain-of-Thought (CoT). Лучшие результаты гарантированы, потому что окончательные ответы генерируются с использованием этих пересмотренных процессов рассуждения.
- Был создан уникальный подход к использованию стратегической информации для выбора и соответствия соответствующих демонстраций. При использовании этой техники можно точно соотнести примеры CoT высокого качества, что повышает производительность модели в задачах, требующих рассуждения на основе примеров.
- Были проведены обширные исследования в различных областях мышления, подтвердившие эффективность парадигмы Strategic Chain-of-Thought (SCoT). Результаты показали значительный прирост качества и точности рассуждений, подтверждая жизнеспособность подхода в качестве средства улучшения способностей LLM к рассуждению в различных областях.
В заключение, SCoT является значительным достижением в рассуждении LLM. Он преодолевает основные недостатки обычных техник Chain-of-Thought путем включения стратегической информации и улучшения процедуры. Этот методический подход не только увеличивает точность и надежность рассуждений, но также имеет потенциал изменить способ, которым LLM решают сложные задачи рассуждения в различных областях.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта.
Не забудьте подписаться на наш канал в Twitter и присоединиться к нашей группе в Telegram и LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу 50k+ ML SubReddit.
FREE AI WEBINAR: ‘SAM 2 for Video: How to Fine-tune On Your Data’ (Wed, Sep 25, 4:00 AM – 4:45 AM EST)