Технология голосового взаимодействия и искусственный интеллект
Технология голосового взаимодействия значительно продвинулась благодаря развитию искусственного интеллекта (ИИ). Основной фокус — улучшение естественного общения между людьми и машинами с целью сделать взаимодействие более интуитивным и похожим на человеческое. Недавние достижения позволили достичь высокой точности распознавания речи, определения эмоций и естественной речи. Исследователи создают модели, способные работать с несколькими языками и понимать эмоции, что делает взаимодействие более плавным и похожим на человеческое.
Основные вызовы и решения
Основной вызов — улучшение естественного голосового взаимодействия с большими языковыми моделями. Текущие системы часто нуждаются в помощи в снижении задержки, поддержке нескольких языков и возможности генерации эмоционально насыщенной и контекстно соответствующей речи. Эти ограничения препятствуют плавному и человекоподобному взаимодействию. Улучшение возможностей этих систем для точного понимания и развития речи на разных языках и в эмоциональных контекстах критично для развития взаимодействия человека с машиной.
Практические решения и преимущества
Существующие методы для голосового взаимодействия включают различные модели распознавания и генерации речи. Инструменты, такие как Whisper для распознавания речи и традиционные модели для определения эмоций и классификации аудио-событий, заложили основу. Однако эти методы часто не обеспечивают низкую задержку, высокую точность и эмоционально насыщенное взаимодействие на нескольких языках. Очевидна необходимость более надежного и универсального решения для эффективного выполнения этих задач.
Пример практического применения
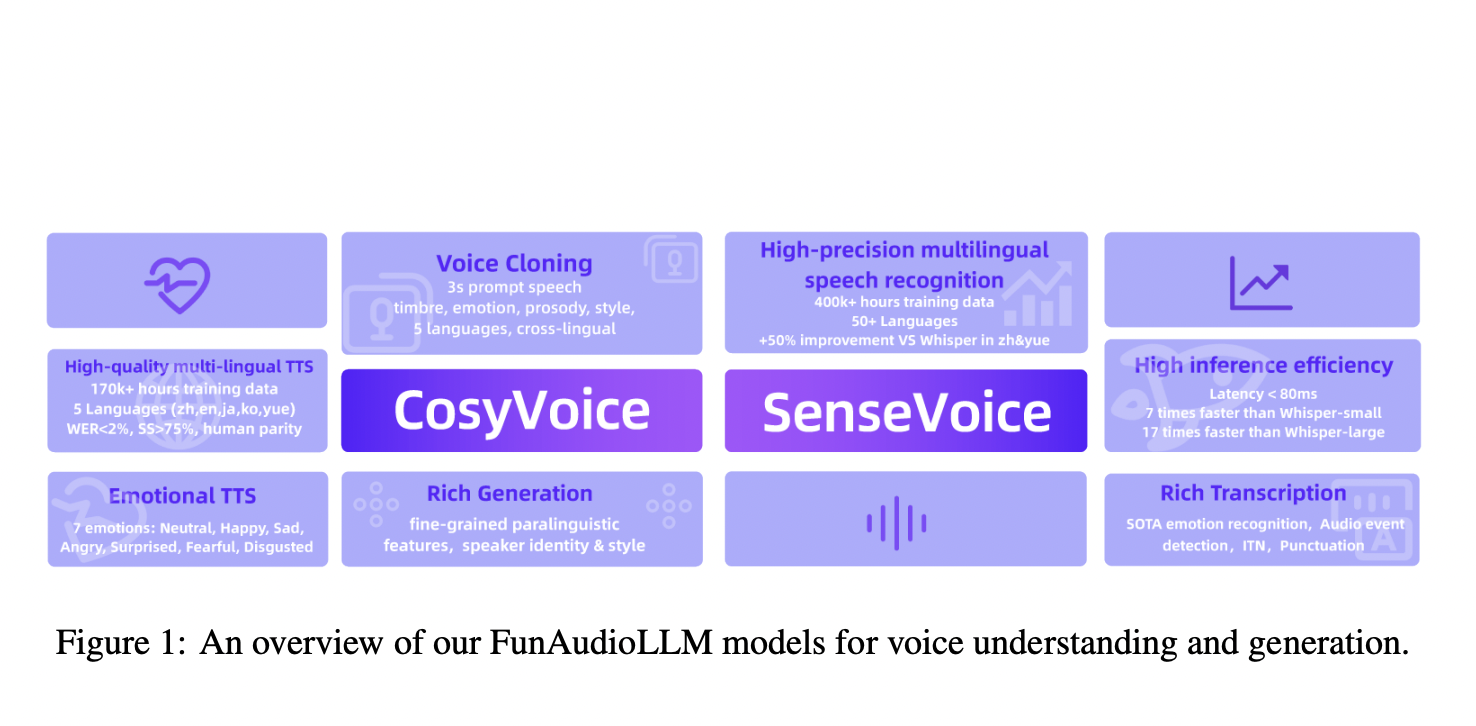
Исследователи из группы Alibaba представили FunAudioLLM, включающий две основные модели: SenseVoice и CosyVoice. SenseVoice отличается многоязычным распознаванием речи, распознаванием эмоций и обнаружением аудио-событий, поддерживая более 50 языков. CosyVoice фокусируется на естественной генерации речи, позволяя контролировать язык, тембр, стиль речи и идентификацию спикера. Совмещая эти модели, исследовательская группа стремилась расширить границы технологии голосового взаимодействия.

























