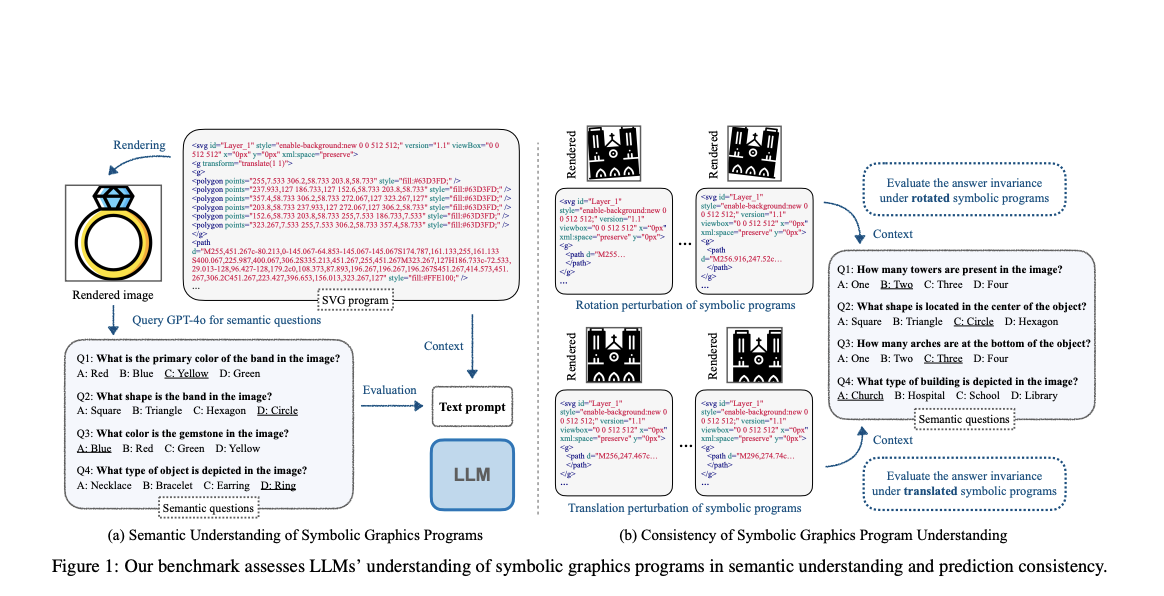
Оценка понимания символьных программ в области искусственного интеллекта
Большие языковые модели (LLM) продемонстрировали способность генерировать общие компьютерные программы, что дает понимание структуры программы. Однако сложно определить их истинные возможности, особенно в поиске задач, которые они не видели во время обучения. Критически важно определить, могут ли LLM действительно «понимать» символьные графические программы, которые генерируют визуальное содержимое при выполнении. Они определяют это понимание как способность понимать семантическое содержимое отображенного изображения только на основе исходного текстового ввода программы. Этот метод включает в себя ответы на вопросы о содержании изображения без его непосредственного просмотра, что легко делается с визуальным вводом, но намного сложнее, когда полагаешься только на текст программы.
Практические решения и ценность
Исследователи предложили новый подход к оценке и улучшению понимания LLM символьных графических программ. Введен бенчмарк под названием SGP-Bench для семантического понимания LLM и согласованности интерпретации программ SVG (2D векторная графика) и CAD (2D/3D объекты). Кроме того, разработан новый метод тонкой настройки на основе собранного набора инструкций под названием Symbolic Instruction Tuning для улучшения производительности. Также созданный исследователями символьный набор данных MNIST показывает существенные различия между пониманием символьных графических программ LLM и человеком.
Процесс создания бенчмарка для оценки понимания LLM символьных графических программ использует масштабируемую и эффективную платформу. Оценка понимания LLM символьных графических программ производится на наборе данных SGP-MNIST, который состоит из 1000 программ SVG, рендерящих изображения цифр MNIST, по 100 программ на цифру (0-9). В результате выявлено значительное различие между производительностью машин и человека в понимании символьных представлений визуальной информации.
Заключение и перспективы
Исследователи представили новый способ оценки LLM путем оценки их способности понимать изображения непосредственно из их символьных графических программ без визуального ввода. Они создали бенчмарк SGP-Bench, эффективно измеряющий производительность LLM в этой задаче. Также была представлена тонкая настройка символьных инструкций (SIT) для улучшения способности LLM интерпретировать графические программы. Это исследование помогает предоставить более ясное представление о возможностях LLM и способствует созданию разнообразных задач для оценки. Будущие исследования включают изучение того, как LLM понимают семантику в этой области и работу над разработкой продвинутых методов для улучшения их производительности в этих задачах.

























