«`html
Применение модели AiM: Авторегрессивная модель генерации изображений на основе архитектуры Mamba
Большие языковые модели (LLMs), основанные на авторегрессивных архитектурах декодера трансформера, продвинули обработку естественного языка с выдающимися показателями производительности и масштабируемости. Недавно модели диффузии привлекли внимание визуальных задач генерации, затмевая авторегрессивные модели (AMs). Однако AMs обладают лучшей масштабируемостью для крупномасштабных приложений и работают более эффективно с языковыми моделями, что делает их более подходящими для объединения языковых и визуальных задач.
Недавние достижения в авторегрессивной визуальной генерации (AVG) показали многообещающие результаты, сопоставимые или превосходящие модели диффузии по качеству. Тем не менее, по-прежнему существуют значительные проблемы, особенно в вычислительной эффективности из-за высокой сложности визуальных данных и квадратичных вычислительных требований трансформеров.
Основные решения и практическая ценность
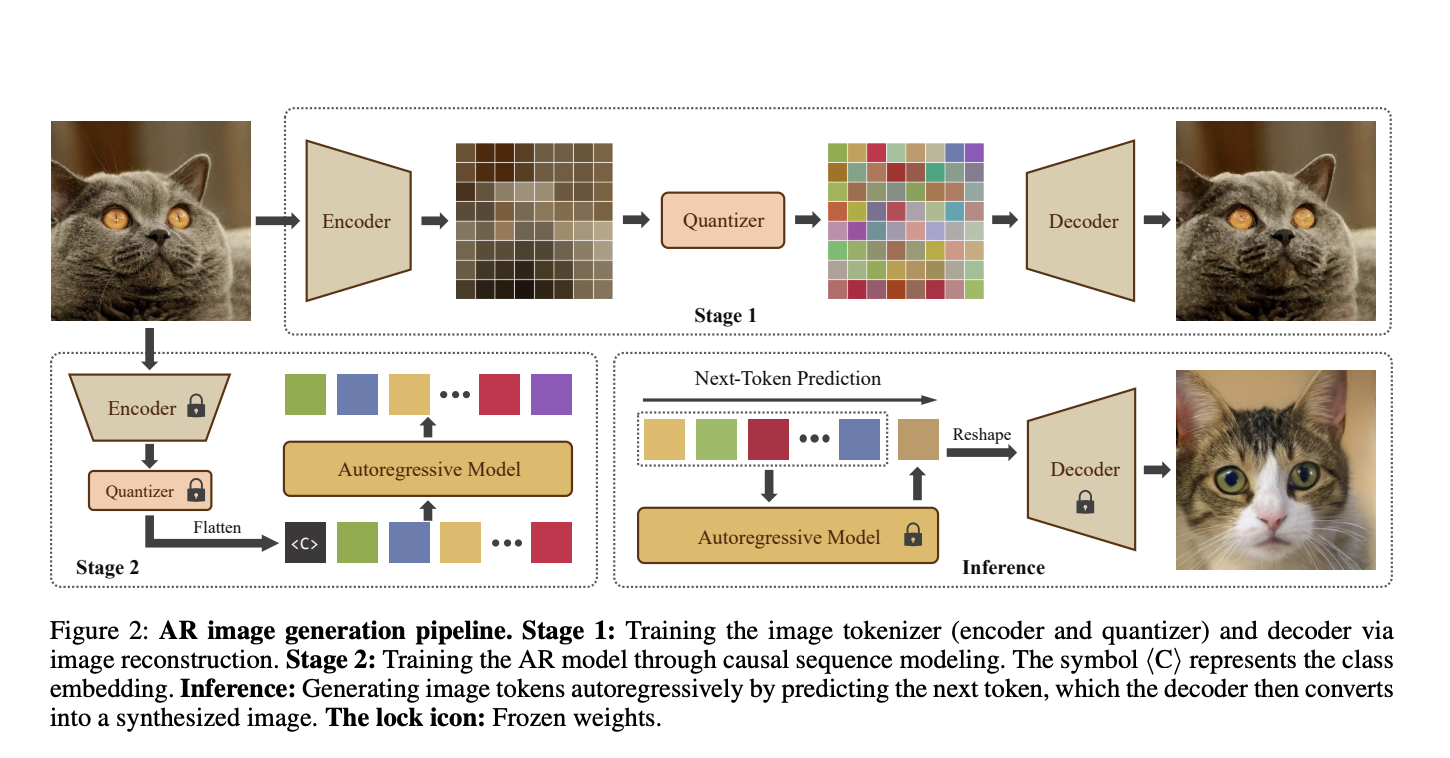
Существующие методы включают модели на основе векторного квантования (VQ) и модели пространства состояний (SSMs) для решения проблем в AVG. VQ-основанные подходы, такие как VQ-VAE, DALL-E и VQGAN, сжимают изображения в дискретные коды и используют AMs для прогнозирования этих кодов. SSMs, особенно семейство Mamba, показали потенциал в управлении длинными последовательностями с линейной вычислительной сложностью.
Исследователи из нескольких университетов предложили AiM, новую авторегрессивную модель генерации изображений на основе фреймворка Mamba. Она разработана для высококачественной и эффективной генерации изображений с учетом класса, что делает ее первой моделью такого рода. AiM использует позиционное кодирование, предлагая новый и более обобщенный метод нормализации слоев под названием adaLN-Group, который оптимизирует баланс между производительностью и количеством параметров.
AiM была разработана в четырех масштабах и оценена на базе ImageNet1K для оценки архитектурного дизайна, производительности, масштабируемости и эффективности вывода. Она использует токенизатор изображений с коэффициентом снижения 16, инициализированный предварительно обученными весами от LlamaGen. Каждое изображение размером 256×256 токенизируется на 256 токенов.
AiM показала значительный прирост производительности с увеличением размера модели и длительности обучения, а также явное преимущество в скорости вывода по сравнению с другими моделями, что делает ее выдающимся решением для авторегрессивного визуального моделирования.
В заключение, исследователи представили AiM, новую модель авторегрессивной генерации изображений на основе фреймворка Mamba. Ее эффективность и эффективность подчеркивают ее масштабируемость и широкие возможности применения в авторегрессивном визуальном моделировании.
«`

























