Преимущества Jina-Embeddings-v3 для решения задач в NLP
Практические решения и ценность модели
Модели встраивания текста стали основополагающими в обработке естественного языка (NLP). Они преобразуют текст в высокоразмерные векторы, улавливающие семантические отношения, что позволяет выполнять такие задачи, как поиск документов, классификация, кластеризация и другие. Модели встраивания играют ключевую роль в продвинутых системах, таких как модели Retrieval-Augmented Generation (RAG), где векторы поддерживают поиск соответствующих документов. С увеличивающейся потребностью в моделях, способных обрабатывать несколько языков и длинные текстовые последовательности, модели на основе трансформеров революционизировали процесс создания встраиваний. Однако, несмотря на их продвинутые возможности, применение в реальных приложениях сталкивается с ограничениями, особенно в обработке обширных мультиязычных данных и длинных текстовых документов.
Ранее модели встраивания текста столкнулись с несколькими вызовами. Несмотря на то, что они рекламируются как универсальные, основная проблема заключается в том, что многие модели часто требуют настройки для успешного выполнения различных задач. Эти модели часто испытывают сложности в балансировании производительности между языками и обработке длинных текстов. В мультиязычных приложениях модели встраивания должны справляться с сложностью кодирования отношений между различными языками, каждый из которых имеет уникальные языковые структуры. Сложность возрастает с задачами, требующими обработки длинных текстов, что часто превышает возможности большинства текущих моделей. Более того, внедрение таких масштабных моделей, часто с миллиардами параметров, представляет существенные вычислительные затраты и проблемы масштабируемости, особенно когда маргинальные улучшения не оправдывают расход ресурсов.
Предыдущие попытки решить эти проблемы в основном полагались на крупные модели языка (LLMs), которые могут превышать 7 миллиардов параметров. Эти модели проявляют профессионализм в выполнении различных задач на разных языках, от классификации текста до поиска документов. Однако, несмотря на их огромный размер параметров, улучшения в производительности минимальны по сравнению с моделями, содержащими только кодировщики, такими как XLM-RoBERTa и mBERT. Сложность этих моделей также делает их непрактичными для многих реальных приложений, где ресурсы ограничены. Усилия по улучшению эффективности встраиваний включали инновации, такие как настройка инструкций и методы позиционного кодирования, такие как Rotary Position Embeddings (RoPE), которые помогают моделям обрабатывать более длинные текстовые последовательности. Тем не менее, даже с этими усовершенствованиями модели часто не удовлетворяют требованиям мультиязычных задач поиска с желаемой эффективностью.
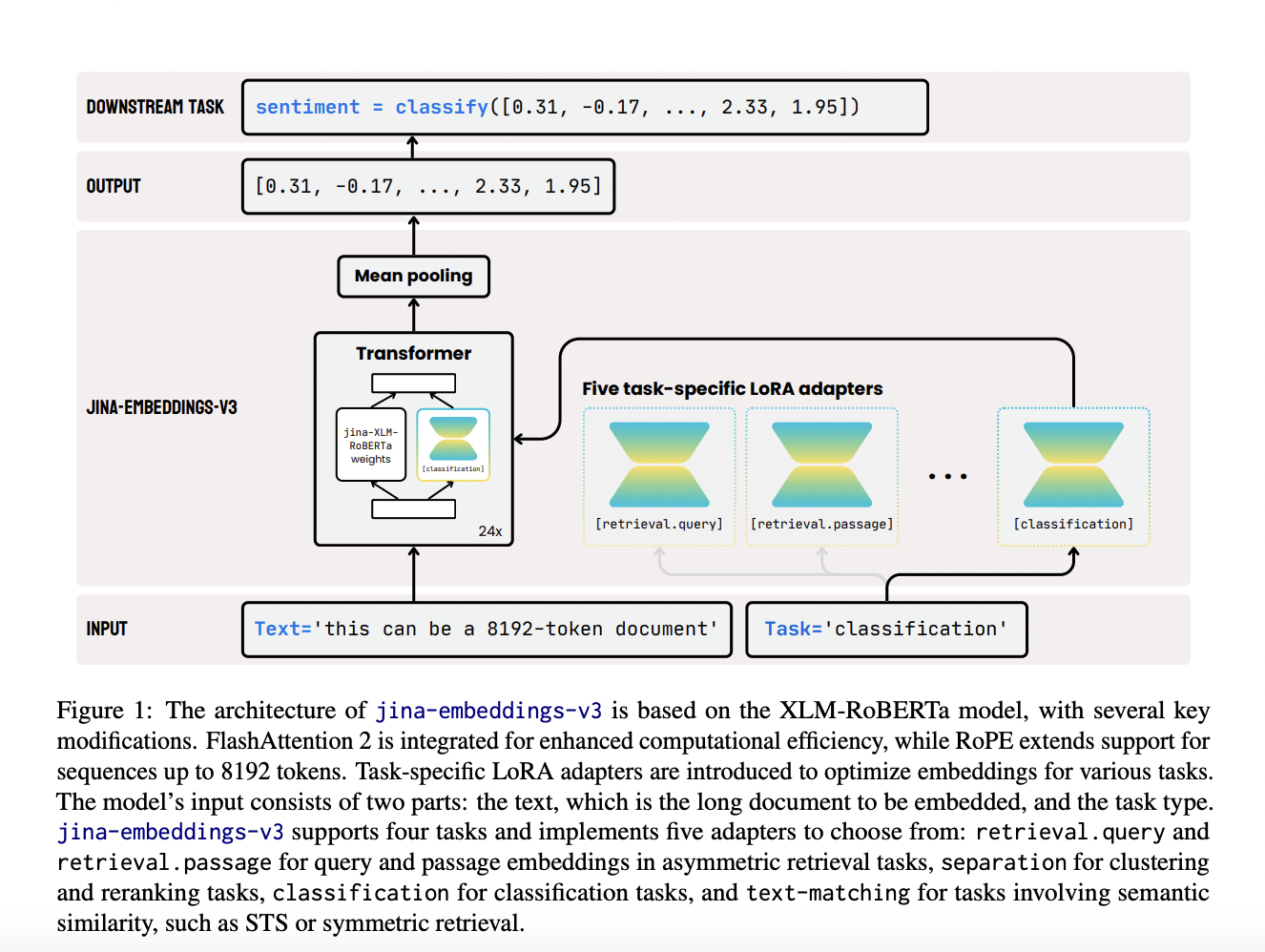
Исследователи из Jina AI GmbH представили новую модель, Jina-embeddings-v3, специально разработанную для устранения неэффективностей предыдущих моделей встраивания. Эта модель, включающая 570 миллионов параметров, обеспечивает оптимизированную производительность по многим задачам, поддерживая при этом длинные текстовые документы до 8192 токенов. Модель включает ключевое новшество: адаптеры задачно-специфичной низкоранговой адаптации (LoRA). Эти адаптеры позволяют модели эффективно генерировать высококачественные встраивания для различных задач, включая поиск документов по запросу, классификацию, кластеризацию и сопоставление текста. Возможность Jina-embeddings-v3 предоставлять специфические оптимизации для этих задач обеспечивает более эффективную обработку мультиязычных данных, длинных документов и сложных сценариев извлечения, обеспечивая баланс производительности и масштабируемости.

























