Google AI представляет звуковые представления здоровья (HeAR): модель биоакустического фундамента, разработанная для помощи исследователям в создании моделей, способных слушать звуки человека и выявлять ранние признаки заболеваний
Звуковые данные, такие как кашель и дыхание, содержат ценную информацию о здоровье, которую необходимо более широко использовать в медицинском машинном обучении. Существующие модели глубокого обучения для этих звуков часто ориентированы на конкретные задачи, что ограничивает их обобщаемость. Несемантические атрибуты речи могут помочь в распознавании эмоций и выявлении заболеваний, таких как Паркинсон и болезнь Альцгеймера. Недавние достижения в области самообучения обещают обеспечить моделям возможность изучать надежные, общие представления на основе больших, не размеченных данных. В то время как самообучение прогрессирует в областях, таких как зрение и язык, его применение к звуковым данным о здоровье остается плохо изученным.
Практические решения и ценность
Исследователи из Google Research и Центра исследований инфекционных заболеваний в Замбии разработали HeAR, масштабную систему глубокого обучения, основанную на самообучении. HeAR использует маскированные автокодировщики, обученные на массивном наборе данных из 313 миллионов аудиофрагментов длительностью 2 секунды. Модель устанавливает себя как передовую в области встраивания звуковых данных о здоровье, превосходящую другие модели на 33 задачах звукового здоровья из 6 наборов данных. Низкоразмерные представления HeAR, полученные из самообучения, демонстрируют сильную переносимость и обобщение на данные вне распределения, превосходя существующие модели в функциях, таких как обнаружение звуковых событий здоровья, вывод кашля и спирометрия в различных наборах данных.
Самообучение стало ключевым подходом для разработки общих представлений на основе больших, не размеченных данных. Различные методы самообучения, такие как контрастные (SimCLR, BYOL) и генеративные (MAE), значительно продвинулись, особенно в обработке аудио. Недавние успехи в области самообучения аудиоэнкодеров, таких как Wav2vec 2.0 и AudioMAE, значительно улучшили обучение представлений речи. В то время как несемантическое самообучение речи, такое как TRILL и FRILL, получило некоторое развитие, несемантические звуковые данные о здоровье все еще нуждаются в изучении. Это исследование представляет генеративную систему самообучения (MAE), сфокусированную на несемантических звуковых данных о здоровье, с целью улучшения обобщения в задачах мониторинга здоровья и выявления заболеваний.
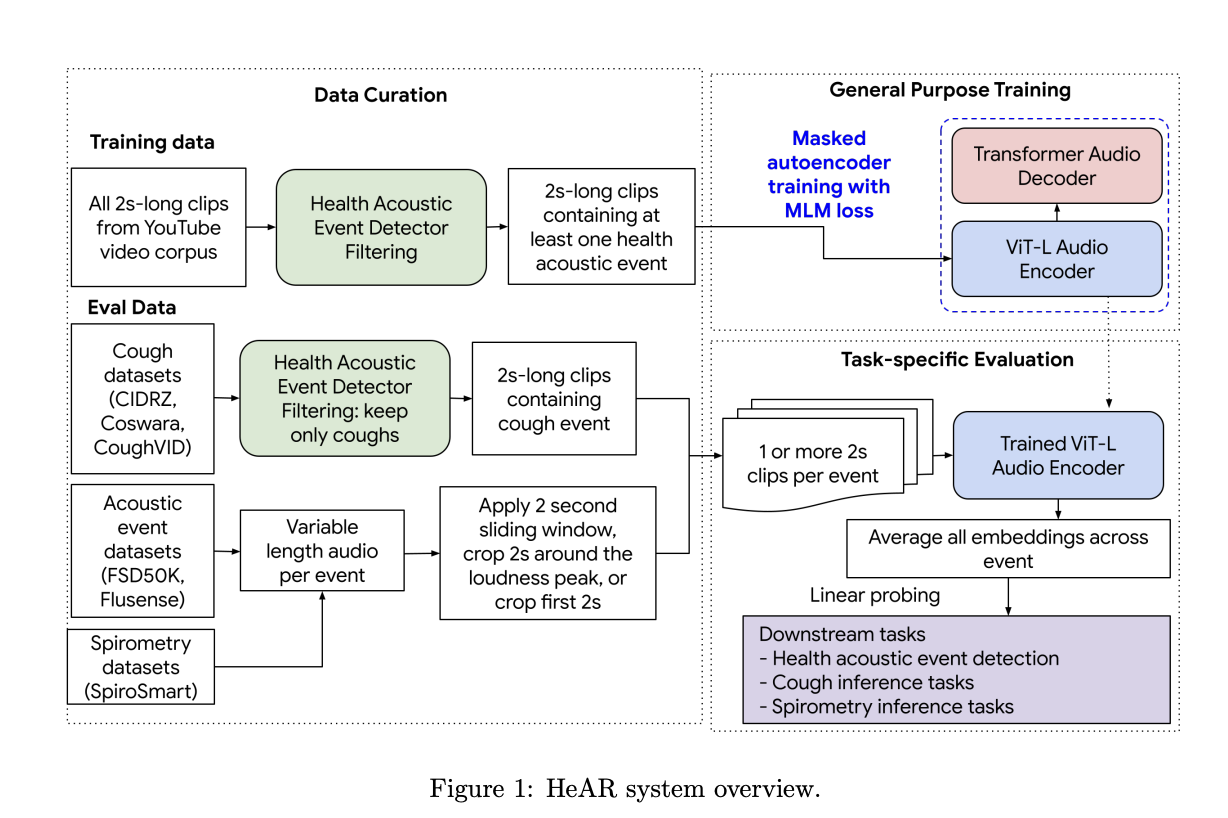
HeAR состоит из трех основных компонентов: курирование данных (включая детектор звуковых событий здоровья), обучение общего назначения для разработки аудиоэнкодера и оценка задачи с использованием обученных вложений. Система кодирует аудиофрагменты длительностью 2 секунды для генерации вложений для последующих задач. Детектор звуковых событий здоровья, сверточная нейронная сеть, идентифицирует шесть несемантических звуковых событий, таких как кашель и дыхание. HeAR обучен на большом наборе данных (YT-NS) из 313,3 миллионов аудиофрагментов с использованием маскированных автокодировщиков. Он прошел проверку на различных задачах звукового здоровья, демонстрируя превосходную производительность по сравнению с передовыми аудиоэнкодерами, такими как TRILL, FRILL и CLAP.
HeAR превзошел другие модели на 33 задачах из шести наборов данных, достигнув самого высокого среднего обратного ранга (0,708) и заняв первое место в 17 задачах. В то время как CLAP превзошел в обнаружении звукового здоровья (MRR=0,846), HeAR занял второе место (MRR=0,538), несмотря на то, что не использовал FSD50K для обучения. Производительность HeAR снизилась с увеличением длины последовательностей, вероятно из-за его фиксированных синусоидальных позиционных кодировок. HeAR последовательно превосходил базовые модели в нескольких категориях для вывода кашля и задач спирометрии, демонстрируя устойчивость и минимальное изменение производительности на различных устройствах записи, особенно в сложных наборах данных, таких как CIDRZ и SpiroSmart.
Исследование представило и оценило систему HeAR, которая объединяет детектор звуковых событий здоровья с обучением аудиоэнкодера на основе генеративного обучения на наборе данных YT-NS без кураторства экспертов. Система продемонстрировала высокую производительность в задачах звукового здоровья, таких как классификация туберкулеза по звукам кашля и мониторинг функции легких с помощью аудио смартфона. Модель самообучения HeAR оказалась эффективной, несмотря на ограниченные данные, показав устойчивость на различных устройствах записи. Однако требуется дальнейшая валидация, особенно учитывая предвзятость набора данных и пределы обобщения. Будущие исследования должны исследовать тонкую настройку модели, обработку на устройстве и устранение предвзятости.


























