LLaVA-Critic: Первая большая мультимодальная модель с открытым исходным кодом, разработанная для оценки производительности моделей в различных мультимодальных задачах
Способность к обучению оценивать все более играет ключевую роль в развитии современных больших мультимодальных моделей (LMMs). Переход к пост-обучению с использованием синтетических данных, улучшенных с помощью ИИ, подчеркивает растущее значение обучения оценивать в современных LMMs. Надежная оценка ИИ важна для человеческого труда при оценке сложных задач, генерации эффективных сигналов вознаграждения в обучении с подкреплением и руководства поисковым запросом во время вывода. Несмотря на прогресс в сценариях одиночного изображения, многократного изображения и видео, разработка открытых LMMs, способных оценивать производительность других мультимодальных моделей, представляет собой пробел в отрасли.
Практические решения и ценность:
Существующие попытки решить проблему оценки ИИ в основном сосредоточены на использовании собственных LMMs, таких как GPT-4V, в качестве общих оценщиков для задач зрения и языка. Эти модели использовались в оценочных бенчмарках для сложных сценариев, таких как визуальный чат и детальное описание. Более того, появились альтернативы с открытым исходным кодом, такие как Prometheus-Vision, как оценщики для конкретных критериев оценки, созданных пользователями. В предпочтительном обучении для LMMs применяются методики, такие как обучение с подкреплением по обратной связи от человека (RLHF) и прямая оптимизация предпочтений (DPO) для выравнивания моделей с человеческими намерениями. Недавние исследования расширили эти концепции на мультимодальное пространство, изучая различные стратегии для улучшения способностей визуального чата и сокращения галлюцинаций в мультимодальных моделях зрения и языка.
Исследователи из ByteDance и Университета Мэриленда, Колледж-Парк, предложили LLaVA-Critic, первую LMM, специально разработанную для оценочных задач. Этот подход сосредоточен на подготовке данных для следования инструкциям, разработанных специально для оценочных целей. Он решает два основных сценария: служит в качестве LMM-как-судья и облегчает обучение предпочтениям. Он стремится предоставить надежные оценочные баллы, сравнимые с собственными моделями, такими как GPT-4V, предлагая бесплатную альтернативу для различных оценочных бенчмарков в первом сценарии. Он представляет масштабируемое решение для генерации эффективных сигналов вознаграждения, сокращая зависимость от дорогостоящего сбора обратной связи от людей во втором сценарии. LLaVA-Critic показывает высокую корреляцию с коммерческими моделями GPT в оценочных задачах и превосходную производительность в обучении предпочтениям.
LLaVA-Critic разработан путем донастройки предварительно обученной LMM, способной следовать разнообразным инструкциям. Этот подход обеспечивает возможность модели выполнять различные задачи высокого качества в области зрения. Процесс обучения включает использование оценочного запроса, который объединяет мультимодальный ввод инструкций, ответ(ов) модели и опциональный справочный ответ. LLaVA-Critic обучается предсказывать количественные баллы по критериям и обеспечивать подробные обоснования своих решений. Модель использует стандартную потерю перекрестной энтропии для оценок и обоснований. Исследователи начинают с предварительно обученной контрольной точки LLaVA-OneVision(OV) 7B/72B и донастраивают ее на набор данных LLaVA-Critic-113k для одной эпохи.
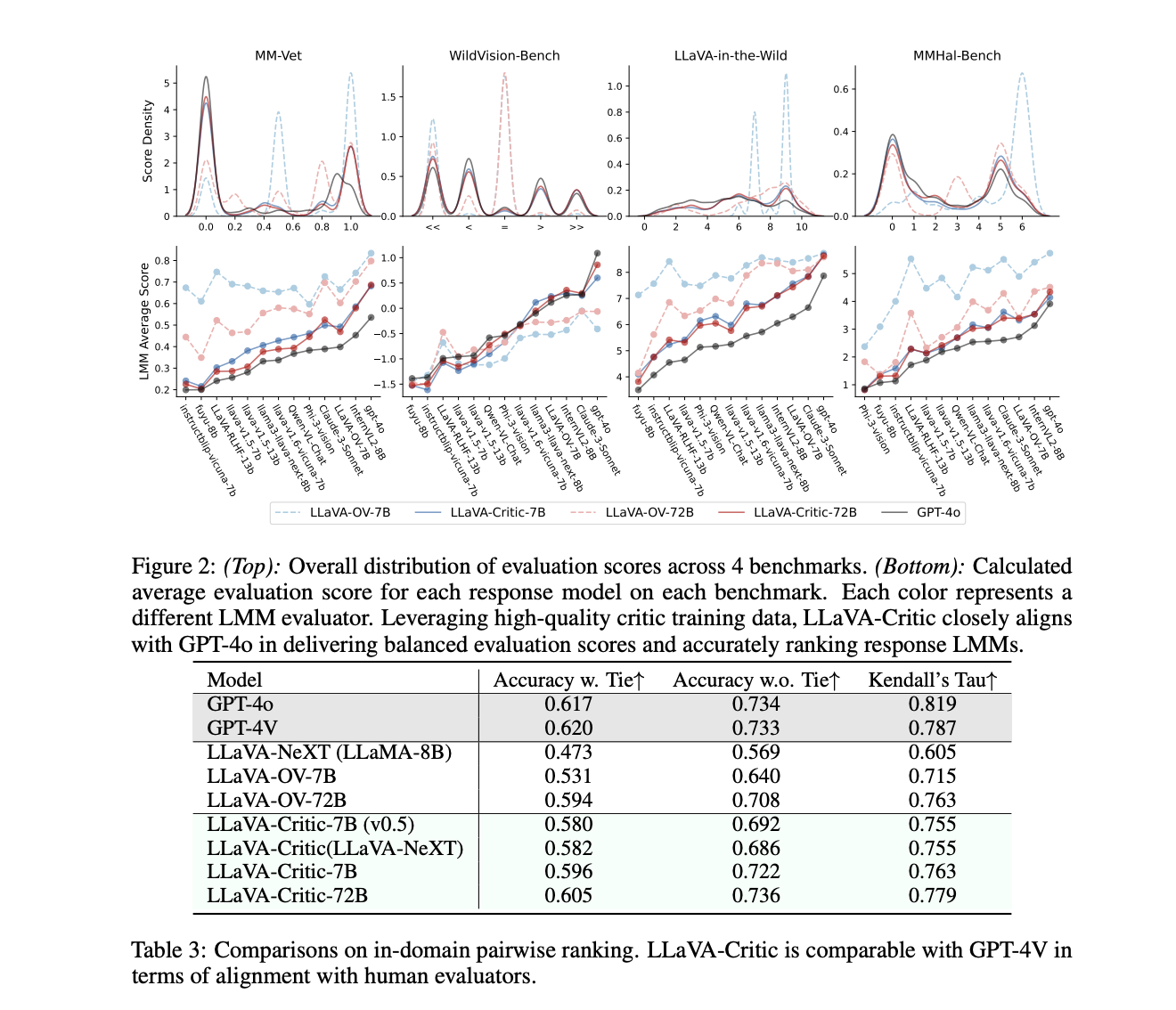
Результаты показывают значительное улучшение как в способностях к количественной оценке, так и в ранжировании по парам у LLaVA-Critic по сравнению с базовыми моделями. LLaVA-Critic-72B достигает наивысшего среднего коэффициента корреляции Пирсона (0,754) и Тау Кендалла (0,933) в количественной оценке, превосходя базовую модель LLaVA-OV-72B. В ранжировании по парам LLaVA-Critic-72B превосходит GPT-4o и GPT-4V в сравнениях без ничьих, достигая точности 73,6%. LLaVA-Critic-7B превосходит большинство базовых моделей по сравнению с коммерческими моделями и другими LMMs с открытым исходным кодом в сценарии LMM-как-судья. Эти результаты подчеркивают эффективность LLaVA-Critic в качестве открытой альтернативы для оценки мультимодальных моделей.
В заключение, исследователи предложили LLaVA-Critic, первую LMM, специально разработанную для оценочных задач. Исследователи использовали высококачественный разнообразный набор данных для следования инструкциям для разработки этой модели, которая выделяется в двух критических областях. Во-первых, как общий оценщик, LLaVA-Critic показывает замечательное согласование с предпочтениями человека и GPT-4o в различных оценочных задачах, предлагая жизнеспособную открытую альтернативу коммерческим моделям. Во-вторых, в сценариях обучения предпочтениям LLaVA-Critic функционирует как надежная модель вознаграждения, превосходя подходы, основанные на обратной связи от людей, в улучшении способностей визуального чата LMMs. Это исследование является важным шагом к созданию способностей самокритики в открытых LMMs, обеспечивая будущие прогрессивные обратные связи в области масштабируемого и сверхчеловеческого выравнивания ИИ.









