“`html
Модели плотного поиска (Dense Retrieval, DR)
Модели плотного поиска (Dense Retrieval, DR) представляют собой передовой метод в информационном поиске (IR), который использует техники глубокого обучения для отображения отрывков и запросов в пространство вложений. Модель может определять семантические отношения между ними, сравнивая вложения запроса и отрывков с использованием этого пространства вложений. Модели DR стремятся найти компромисс между двумя важными аспектами: эффективностью, т.е. точностью и применимостью извлеченной информации, и эффективностью, т.е. скоростью, с которой модель может обрабатывать и предоставлять соответствующие данные.
Преимущества моделей PLM и их недостатки
Предварительно обученные языковые модели (PLM), особенно те, которые построены на архитектуре Transformer, стали эффективными инструментами для кодирования запросов и отрывков в моделях глубокого обучения с подкреплением. PLM на основе Transformer хорошо справляются с захватом сложных семантических связей и зависимостей в длинных текстовых последовательностях благодаря своему механизму самовнимания.
Однако вычислительная сложность PLM на основе Transformer является значительным недостатком. Хотя они являются мощными, вычислительная стоимость механизма самовнимания растет квадратично с длиной текстовой последовательности. Это означает, что модель требует гораздо больше времени для вывода соответствующей информации по мере увеличения длины анализируемого текста. При работе с задачами поиска длинных текстов, где отрывки длинные и требуют значительной обработки, эта неэффективность становится очень проблематичной.
Решение проблемы эффективности
Недавние исследования создали PLM без трансформера, которые стремятся улучшить скорость обработки, предлагая при этом сопоставимую или даже более высокую эффективность для решения проблем эффективности. Архитектура Mamba является одной из таких. PLM на основе Mamba доказали, что они могут быть так же эффективны, как модели на основе Transformer, в задачах генерации текста на основе входных данных.
PLM на основе Mamba показывают линейное масштабирование времени относительно длины последовательности, в отличие от квадратичного масштабирования времени, наблюдаемого у моделей на основе Transformer. Это означает, что они значительно быстрее для задач поиска длинных текстов, поскольку время обработки растет значительно медленнее с увеличением длины текста. Возможность использования архитектуры Mamba в качестве кодировщика для моделей DR в задачах IR была изучена в исследовании.
Эффективность Mamba Retriever
Был создан Mamba Retriever с целью максимизации эффективности и эффективности в операциях информационного поиска (IR). Быстрые времена обработки и отличная точность извлечения сбалансированы в архитектуре этой модели.
Исследовалось, как эффективность Mamba Retriever меняется при различных размерах модели. Тесты на наборах данных BEIR и MS MARCO показали, что Mamba Retriever работает лучше или не хуже, чем модели на основе трансформера с точки зрения эффективности. Эффективность модели растет с увеличением размера модели, что свидетельствует о том, что более крупные модели Mamba способны захватывать более сложную семантическую информацию.
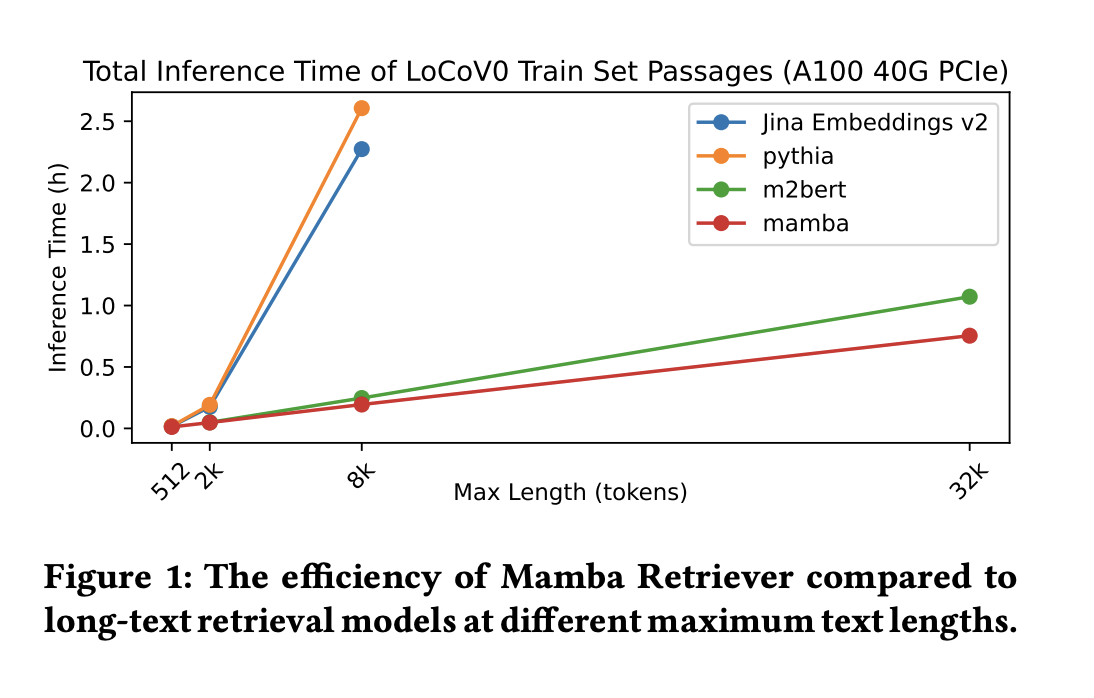
Эффективность Mamba Retriever была изучена, особенно в случае задач поиска длинных текстов. Используя набор данных LoCoV0, команда продемонстрировала, что с настройкой Mamba Retriever может обрабатывать текстовые последовательности длиннее своей предварительно обученной длины, достигая эффективности на уровне или лучше, чем у предыдущих моделей, созданных для поиска длинных текстов.
Команда изучила эффективность вывода Mamba Retriever при различной длительности отрывков. Согласно результатам, Mamba Retriever превосходит по скорости вывода и имеет преимущество линейного масштабирования времени, что делает его особенно подходящим для приложений поиска информации в длинных текстах.
Заключение
Модель Mamba Retriever для информационного поиска является эффективной и успешной, особенно в случае поиска длинных текстов. Благодаря быстрой скорости вывода и высокой эффективности она является жизнеспособным вариантом для различных задач вывода, что отличает ее от более традиционных моделей на основе трансформера.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе в LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему сообществу на Reddit.
Найдите предстоящие вебинары по ИИ здесь.
Статья Mamba Retriever: модель для извлечения информации с использованием Mamba для эффективного и эффективного плотного поиска впервые появилась на MarkTechPost.
Применение Mamba Retriever в вашем бизнесе
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте Mamba Retriever: модель для извлечения информации с использованием Mamba для эффективного и эффективного плотного поиска.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на Telegram.
Попробуйте ИИ ассистент в продажах здесь. Этот ИИ ассистент в продажах помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.
“`









