«`html
Table-Augmented Generation (TAG): Решение для сложных запросов на естественном языке к базам данных
Искусственный интеллект (ИИ) и системы управления базами данных все чаще объединяются, что имеет значительный потенциал для улучшения взаимодействия пользователей с большими наборами данных. Недавние достижения направлены на то, чтобы позволить пользователям задавать вопросы на естественном языке непосредственно базам данных и получать подробные, сложные ответы. Однако текущие инструменты ограничены в решении реальных задач. Традиционные модели ИИ, такие как языковые модели (LM), обладают мощными способностями рассуждения, в то время как базы данных обеспечивают высокую точность вычислений в масштабе. Основной вызов заключается в объединении этих двух возможностей для расширения области и точности ответов, которые пользователи могут получать от запросов, основанных на базах данных.
Проблемы существующих методов
Одной из насущных проблем в этой области является недостаточность существующих методов, таких как Text2SQL и Retrieval-Augmented Generation (RAG). Text2SQL фокусируется на простых переводах запросов на естественном языке в SQL, что ограничивает его способность отвечать на более сложные запросы, требующие семантического рассуждения. Например, бизнес-пользователи часто нуждаются в ответах на вопросы вроде «Почему у нас снизились продажи за последний квартал?» или «Какие отзывы клиентов о продукте X являются положительными?» Text2SQL не может адекватно ответить на такие вопросы, так как они требуют понимания естественного языка за пределами простых реляционных данных. Аналогично, системы RAG выполняют базовые поисковые запросы в базах данных, но они неэффективны в обработке более широких многоэтапных запросов, требующих взаимодействия с несколькими строками данных или агрегации результатов из нескольких таблиц. Этот недостаток сложности в текущих моделях затрудняет их применение в реальном мире, особенно в бизнес-контекстах, где анализ и интерпретация данных выходят за рамки простого извлечения данных.
Решение: Table-Augmented Generation (TAG)
Исследователи из Университета Калифорнии в Беркли и Стэнфордского университета предложили новый метод под названием Table-Augmented Generation (TAG). TAG разработан для объединения семантических способностей языковых моделей с масштабируемой вычислительной мощностью баз данных, тем самым обеспечивая более сложное взаимодействие между ними. Этот метод признал, что реальные пользователи часто задают вопросы, которые выходят за возможности Text2SQL и RAG. TAG сначала преобразует запрос пользователя на естественном языке в исполнимый запрос базы данных, который затем обрабатывается базой данных для извлечения соответствующих данных. Полученные данные объединяются с исходным запросом, и языковая модель генерирует подробный ответ. Этот процесс позволяет TAG обрабатывать запросы, требующие мирового знания, логического рассуждения и точных вычислений над большими наборами данных.
Преимущества TAG
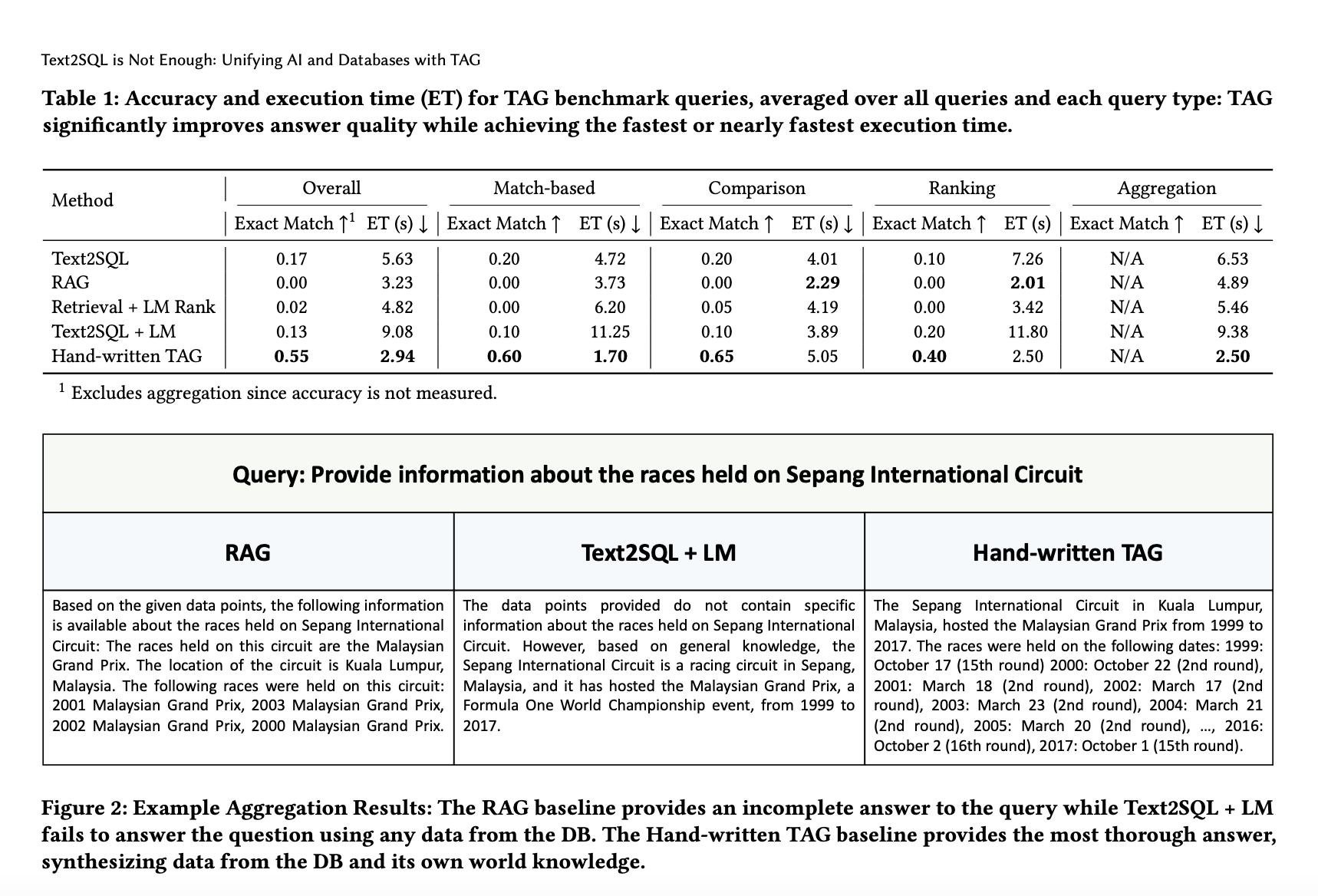
Модель TAG разбивает процесс вопросно-ответной системы на три ключевых этапа: синтез запроса, выполнение и генерация ответа. Сначала система интерпретирует запрос на естественном языке и переводит его в запрос базы данных. Затем этот запрос выполняется на базе данных, извлекая соответствующие строки данных. Наконец, языковая модель обрабатывает эти извлеченные данные, генерируя подробный и контекстно соответствующий ответ для пользователя. Этот трехэтапный процесс позволяет TAG обрабатывать широкий спектр вопросов, которые были бы слишком сложны для существующих методов. Исследователи продемонстрировали способность системы через бенчмарк-тесты, показав, что модель TAG может правильно ответить на до 65% сложных запросов, что значительно превышает 20% уровень успешности лучших существующих моделей.
Применение TAG
В дополнение к превосходству над Text2SQL и RAG, TAG универсален в типах запросов, которые он может обрабатывать. Исследователи тестировали систему в различных областях, включая бизнес-аналитику, анализ настроений клиентов и анализ финансовых тенденций. Например, один запрос сводился к обобщению отзывов о самом прибыльном романтическом фильме, считающемся классикой. TAG синтезировал соответствующие данные, включая название фильма, доход и отзывы, и предоставил подробный ответ, что традиционные системы не смогли сделать. Система была протестирована на 80 запросах, охватывающих области, такие как Формула 1, использование дебетовых карт и образование. В большинстве случаев производительность TAG превзошла производительность существующих моделей, подтверждая его более широкие возможности применения.
Результаты и преимущества TAG
Результаты бенчмарка показали, что TAG достиг средней точности точного совпадения 55% для различных типов запросов, с определенными типами, такими как сравнительные запросы, достигающими 65% точности. В сравнении с этим Text2SQL в большинстве случаев не превышал 20%, а RAG во многих случаях не мог предоставить ни одного правильного ответа. Ручная система TAG, построенная на основе среды выполнения LOTUS, также продемонстрировала преимущество во времени выполнения, завершая большинство задач в среднем за 2,94 секунды, в 3,1 раза быстрее, чем традиционные методы. Эта эффективность, в сочетании с улучшенной точностью, делает TAG высоко перспективным инструментом для будущего управления базами данных на основе ИИ.
Заключение
Путем объединения языковых моделей с базами данных TAG открывает новые возможности для ответов на сложные запросы на естественном языке, требующие детального рассуждения и точных вычислений. Этот подход решает ключевое ограничение текущих моделей, позволяя им обрабатывать более широкий спектр запросов более точно и эффективно. Возможность TAG обрабатывать вопросы, требующие мирового знания, логики и семантического рассуждения, демонстрирует его потенциал для трансформации принятия решений на основе данных в различных областях, включая бизнес-аналитику, анализ отзывов клиентов и прогнозирование тенденций. Через этот инновационный подход исследователи решили давнюю проблему интеграции ИИ и баз данных и подготовили почву для дальнейших достижений в области взаимодействия пользователей с данными в масштабе.
«`

























