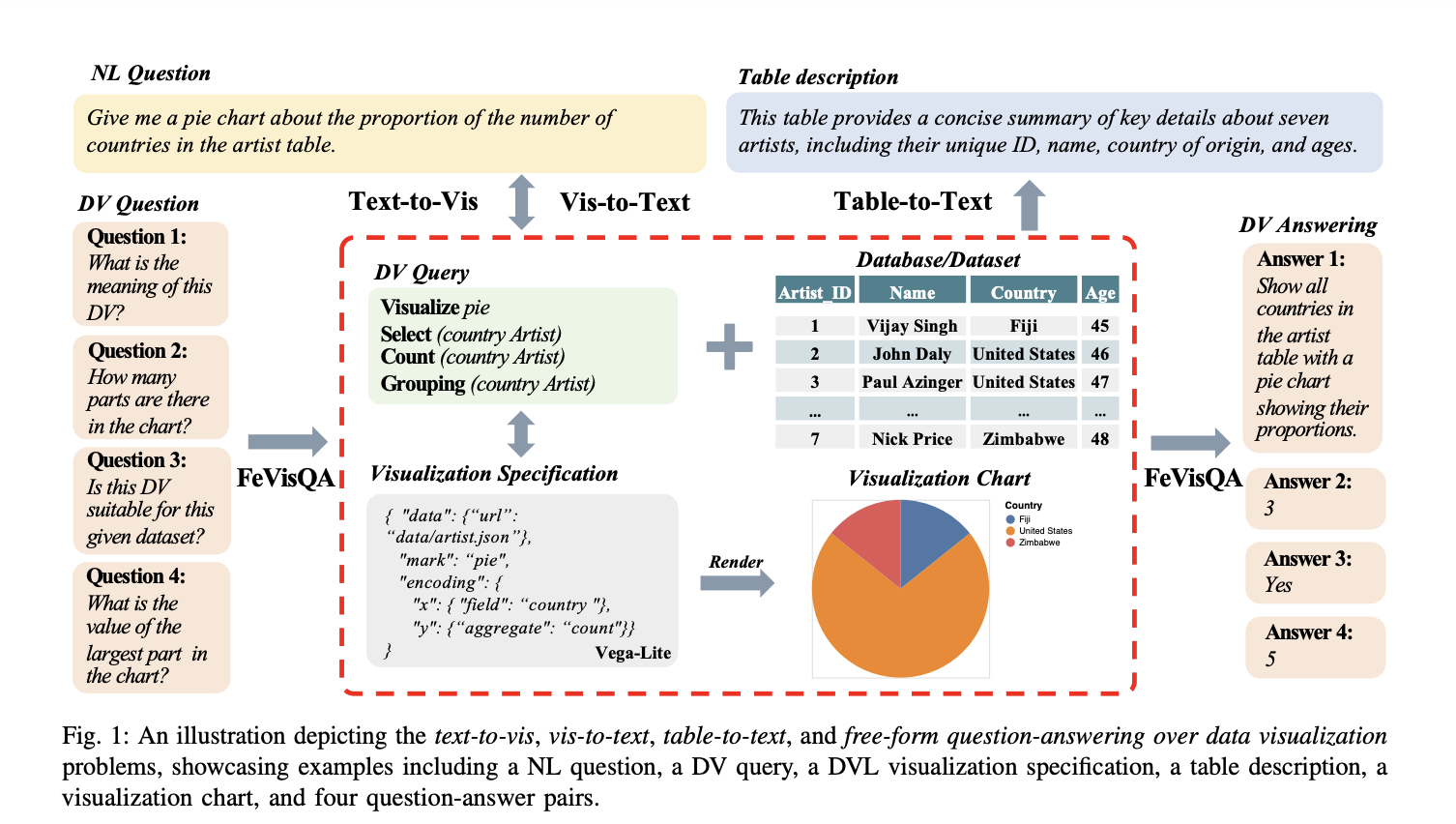
Исследование DataVisT5: мощная предварительно обученная языковая модель для задач безупречной визуализации данных
В современной эре больших данных визуализация данных (DVs) стала обычной практикой, используемой различными приложениями и учреждениями для передачи инсайтов из массивных исходных данных. Однако создание подходящих DVs остается сложной задачей, даже для экспертов, поскольку требует навыков визуального анализа и знания предметной области. Чтобы снизить барьеры в создании DVs и разблокировать их потенциал для широкой публики, исследователи предложили различные задачи, связанные с DV, которые привлекли значительное внимание как из индустрии, так и из академии.
Основные результаты исследования:
- Исследователи представили и выпустили DataVisT5: первую PLM, разработанную для совместного понимания текста и DV.
- Улучшена текстоцентричная архитектура T5 для обработки кросс-модальной информации. Гибридные цели предварительного обучения предназначены для раскрытия сложного взаимодействия между DV и текстовыми данными, способствуя глубокой интеграции кросс-модальных идей.
- Обширные эксперименты на общедоступных наборах данных для различных задач DV, включая текст-к-DV, DV-к-тексту, FeVisQA и таблица-к-тексту, показывают, что DataVisT5 (предложенный метод) превосходит в многозадачных сценариях, последовательно превосходя сильные базовые уровни и устанавливая новые рекорды в производительности.
Предлагаемый метод DataVisT5 следует комплексному пайплайну, включающему пять основных этапов: фильтрация схемы базы данных, кодирование знаний DV, стандартизированное кодирование, предварительное обучение модели и многозадачная донастройка модели. Техника фильтрации схемы базы данных сопоставляет n-граммы между естественным языковым вопросом и таблицами базы данных, выявляя соответствующие элементы схемы и извлекая подсхему для минимизации потерь информации при интеграции визуализации данных и текстовых модальностей.
Исследователи предлагают унифицированный формат представления знаний DV, позволяющий моделям использовать обширное предварительное обучение на более маленьких наборах данных и смягчая снижение производительности из-за гетерогенности данных во время многозадачного обучения.
DataVisT5 демонстрирует значительные улучшения по сравнению с существующими техниками, такими как Seq2Vis, Transformer, RGVisNet, ncNet и GPT-4. В обширных экспериментах этот подход достиг значительного увеличения метрики EM на наборах данных без операций объединения по сравнению с предыдущей передовой моделью RGVisNet. Также DataVisT5 превзошел подход в контекстном обучении с использованием GPT-4 в сценариях, включающих операции объединения. В этих сложных сценариях DataVisT5 достиг впечатляющего значения метрики EM. Результаты подчеркивают эффективность предложенного подхода, подчеркивая превосходство DataVisT5 в синтаксисе и семантике запросов DV.
Это исследование представляет собой значительное продвижение в области и открывает новые перспективы для дальнейшего исследования и инноваций.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте DataVisT5: A Powerful Pre-Trained Language Model for Seamless Data Visualization Tasks.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























