“`html
Использование Aquila2: передовые двуязычные языковые модели с параметрами от 7 до 70 миллиардов
Большие языковые модели (LLM) привлекли значительное внимание благодаря своим выдающимся результатам в различных задачах, революционизируя исследовательские парадигмы. Однако процесс обучения этих моделей сталкивается с несколькими вызовами. LLM зависят от статических наборов данных и проходят длительные периоды обучения, требующие большого количества вычислительных ресурсов. Например, обучение модели LLaMA 65B заняло 21 день с использованием 2048 A100 GPU с 80 ГБ оперативной памяти. Этот метод ограничивает способность моделей адаптироваться к изменениям в составе данных или включать новую информацию. Поэтому важно разработать более эффективные и гибкие методики обучения для LLM с целью улучшения их адаптивности и снижения вычислительных затрат.
Практические решения и ценность
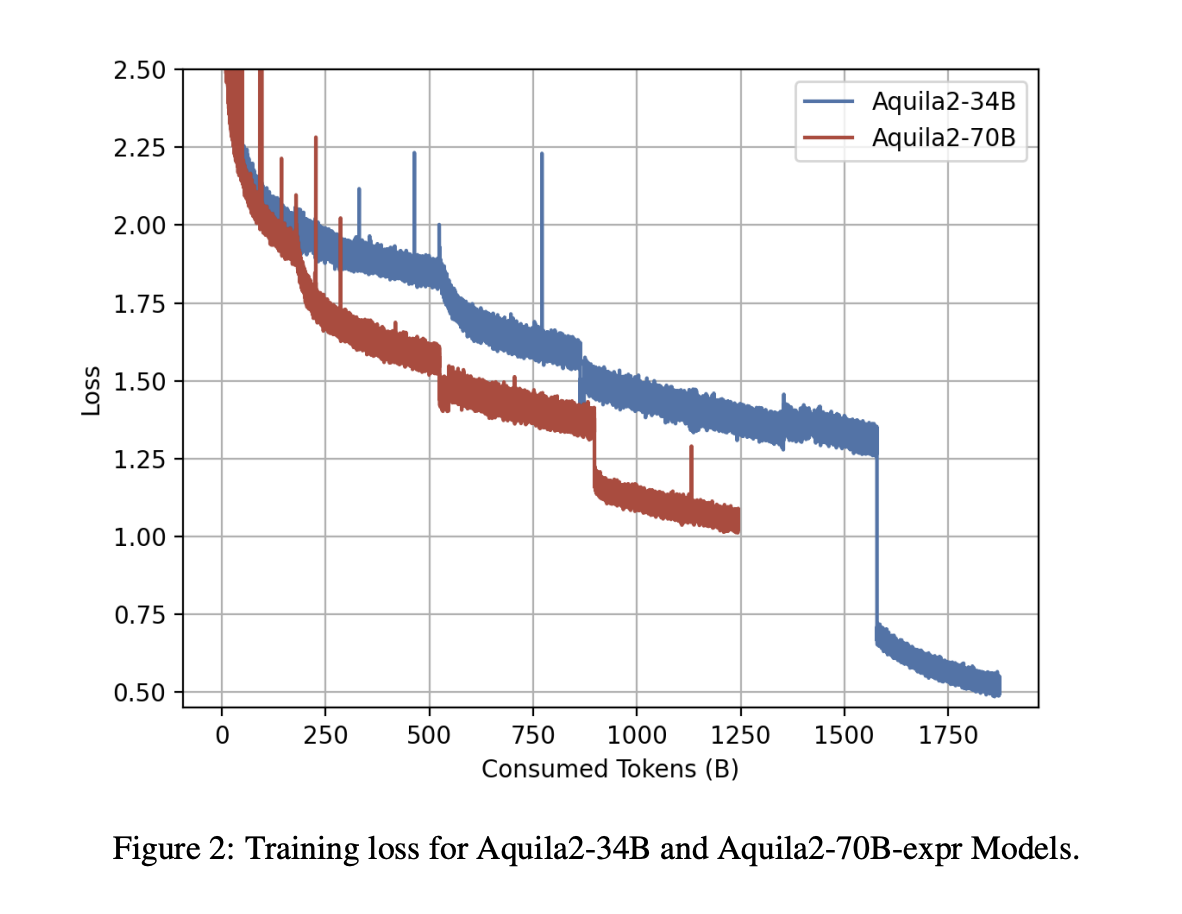
Исследователи из команды языковой модели и программного обеспечения в BAAI предложили серию Aquila2, ряд моделей искусственного интеллекта с размерами параметров от 7 до 70 миллиардов. Эти модели обучаются с использованием фреймворка HeuriMentor (HM), который содержит три основных компонента: (a) Адаптивный обучающий движок (ATE), (b) Монитор состояния обучения (TSM) и (c) Управляющий блок данных (DMU). Эта система улучшает мониторинг процесса обучения модели и позволяет эффективно корректировать распределение данных, делая обучение более эффективным. Фреймворк HM разработан для преодоления вызовов адаптации к изменениям в данных и включения новой информации, обеспечивая более гибкий и эффективный способ обучения LLM.
Архитектура Aquila2 включает несколько важных особенностей для улучшения ее производительности и эффективности. Токенизатор использует словарь из 100 000 слов, выбранный на основе начальных экспериментов, и применяет кодирование байт-пар для извлечения этого словаря. Обучающие данные равномерно разделены между английским и китайским, используя наборы данных Pile и WudaoCorpus. Aquila2 использует механизм группового внимания к запросу (GQA), который повышает эффективность во время вывода по сравнению с традиционным многоголовым вниманием, сохраняя при этом схожее качество. Модель использует популярный метод LLM, называемый вращающимся позиционным встраиванием (RoPE), для позиционного встраивания. RoPE объединяет преимущества относительного и абсолютного кодирования позиций для эффективного захвата шаблонов в последовательных данных.
Производительность модели Aquila2 была тщательно оценена и сравнена с другими крупными двуязычными (китайско-английскими) моделями, выпущенными до декабря 2023 года. Модели, включенные для сравнения, – Baichuan2, Qwen, LLaMA2 и InternLM, каждая из которых имеет уникальные характеристики и размеры параметров. Baichuan2 предлагает версии 7B и 13B, обученные на 2,6 триллиона токенов. Qwen представляет полную серию моделей с оптимизированными для чата версиями. LLaMA2 имеет диапазон параметров от 7B до 70B с тонкой настройкой версий для чата. InternLM показывает огромную модель с 104B параметрами, обученную на 1,6 триллиона токенов, с версиями 7B и 20B. Эти сравнения по различным наборам данных предоставляют подробный анализ возможностей Aquila2.
Модель Aquila2-34B показывает высокую производительность в различных задачах обработки естественного языка, достигая самого высокого среднего балла 68,09 в сравнительных оценках. Она хорошо справляется с задачами на английском (средний балл 68,63) и китайском (средний балл 76,56) языках. Aquila2-34B превосходит LLaMA2-70B в понимании двуязычных текстов, достигая своего лучшего результата 81,18 в задаче BUSTM. Более того, Aquila2-34B лидирует в сложной задаче HumanEval со счетом 39,02, указывающим на сильное понимание, схожее с человеческим. Оценка показывает конкурентное поле среди различных моделей, с близкими соревнованиями в задачах, таких как TNEWS и C-Eval. Эти результаты показывают необходимость тщательной оценки в различных задачах для понимания возможностей модели и продвижения в области обработки естественного языка.
В заключение, исследователи из команды языковой модели и программного обеспечения в BAAI предложили серию Aquila2, ряд двуязычных моделей с размерами параметров от 7 до 70 миллиардов. Aquila2-34B показывает превосходную производительность на 21 различном наборе данных, превосходя LLaMA-2-70B-expr и другие эталоны, даже при использовании 4-битной квантизации. Более того, разработанный исследователями фреймворк HM позволяет динамически корректировать распределение данных во время обучения, что приводит к более быстрой сходимости и улучшению качества модели. Будущие исследования включают изучение смеси экспертов и улучшение качества данных. Однако включение тестовых данных GSM8K в предварительное обучение может повлиять на достоверность результатов Aquila2, требуя осторожности в будущих сравнениях.
Посмотрите статью и GitHub. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе LinkedIn. Если вам нравится наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 48k+ ML SubReddit
Найдите предстоящие вебинары по искусственному интеллекту здесь
Arcee AI представляет Arcee Swarm: революционная смесь агентов MoA, архитектура, вдохновленная кооперативным интеллектом, обнаруженным в самой природе
“`
























