Решение проблемы токсичности в мультиязычных моделях
Рост некачественных данных в интернете приводит к установке нежелательных, небезопасных или токсичных знаний в большие языковые модели (LLM). Когда эти модели используются в чат-ботах, они увеличивают риск выставления пользователей на вредные советы или агрессивное поведение. Существующие наборы данных для оценки токсичности, в основном сосредоточены на английском языке, не улавливают мультиязычную токсичность, что подрывает безопасность LLM. AI2 в сотрудничестве с CMU решает проблему ограничения токсичности в LLM на разных языках. Исследование обсуждает, как токсичность меняется в зависимости от языковых ресурсов и влияния дизайнерских решений, таких как размер модели и методы выравнивания.
Практические решения и ценность
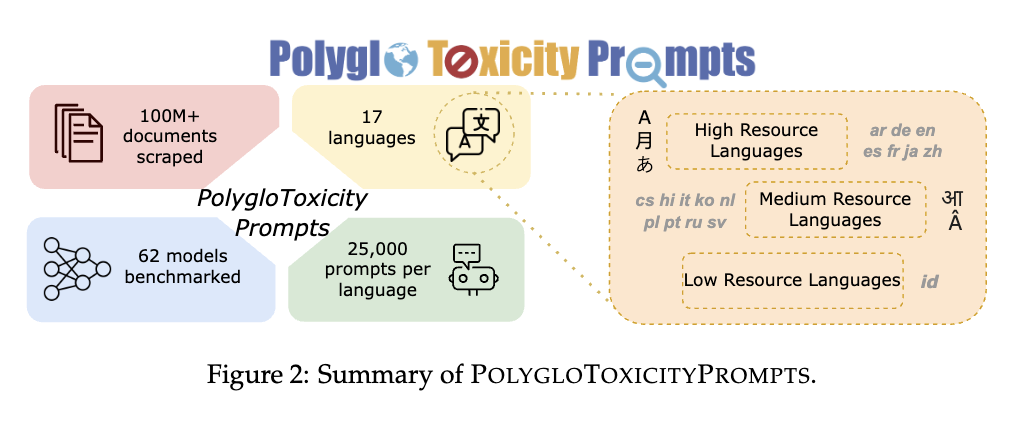
Текущие методы оценки токсичности в LLM недостаточны для улавливания мультиязычной токсичности. Исследователи AI2 и CMU представили PolygloToxicityPrompts, набор данных, состоящий из 425 000 естественно возникающих подсказок на 17 языках с различными уровнями токсичности. Этот набор данных направлен на более точное представление токсичности в LLM путем использования подсказок, извлеченных из веб-ресурсов, и сосредоточившись на коротких, потенциально токсичных отрывках текста. Набор данных продолжает предыдущую работу, такую как RealToxicityPrompts, но расширяет свой охват до мультиязычного контекста.
PolygloToxicityPrompts разработан для улавливания большего количества токсичности в LLM, сосредотачиваясь на коротких подсказках, а не на полных комментариях или разговорах. Это позволяет моделям идентифицировать токсичность на начальных этапах общения. Набор данных включает несколько языков, устраняя пробелы, оставленные преимущественно англоязычными наборами данных. Используя PerspectiveAPI для измерения токсичности подсказок и генераций, исследователи вычисляют среднюю токсичность модели по всем ее продолжениям. Исследователи обнаружили, что современные мультиязычные LLM проявляют наивысшие уровни токсичности в языках с меньшим количеством высококачественных данных, таких как хинди и чешский, и наименьшие – в языках, таких как русский и голландский.
Исследование использует влияние размера модели и методов выравнивания на токсичность. Для базовых LLM токсичность увеличивается с увеличением размера модели, что указывает на то, что большие модели склонны учиться большей токсичности из своих обучающих данных. Однако модели, настроенные на инструкции и предпочтения, менее токсичны, чем базовые модели. Исследование сравнивает PerspectiveAPI, детектор токсичности, с Llama Guard, детектором безопасности, и приходит к выводу, что, хотя они связаны, токсичность и безопасность – это различные концепции, требующие своих решений.
В заключение, PolygloToxicityPrompts предлагает ценный инструмент для оценки и смягчения токсичности в LLM на разных языках. Статья содержит идеи, которые подчеркивают важность языка подсказок, размера модели и методов выравнивания при решении проблемы токсичности. Набор данных помогает создавать более надежные модели для проактивной модерации и фильтрации мультиязычного контента, способствуя созданию безопасной онлайн-среды.









