“`html
Новое исследование по машинному обучению от UCLA раскрывает неожиданные нерегулярности и неоднородность в контекстных границах принятия решений LLMs
Недавние языковые модели, такие как GPT-3+, показали значительное улучшение производительности, просто предсказывая следующее слово в последовательности с использованием больших наборов данных для обучения и увеличенной емкости модели. Ключевая особенность этих моделей на основе трансформаторов заключается в контекстном обучении, которое позволяет модели учиться задачам, условно связывая серию примеров без явного обучения. Однако механизм работы контекстного обучения до сих пор частично понятен. Исследователи изучили факторы, влияющие на контекстное обучение, и выяснили, что точные примеры не всегда необходимы для эффективности, в то время как структура подсказок, размер модели и порядок примеров значительно влияют на результаты.
Практические решения и ценность
Это исследование исследует три существующих метода контекстного обучения в трансформаторах и больших языковых моделях (LLMs), проводя серию бинарных классификационных задач (BCTs) в различных условиях. Первый метод фокусируется на теоретическом понимании контекстного обучения, стремясь связать его с градиентным спуском (GD). Второй метод – это практическое понимание, которое рассматривает, как контекстное обучение работает в LLMs, учитывая факторы, такие как пространство меток, распределение входного текста и общий формат последовательности. Финальный метод – обучение контекстному обучению. Для активации контекстного обучения используется MetaICL, которая является мета-обучающей структурой для донастройки предварительно обученных LLMs на большой и разнообразной коллекции задач.
Исследователи из Департамента компьютерных наук Университета Калифорнии в Лос-Анджелесе (UCLA) представили новую перспективу, рассматривая контекстное обучение в LLMs как уникальный алгоритм машинного обучения. Эта концептуальная рамка позволяет традиционным инструментам машинного обучения анализировать границы принятия решений в бинарных классификационных задачах. Множество ценных идей было получено для производительности и поведения контекстного обучения путем визуализации этих границ принятия решений в линейных и нелинейных условиях. Этот подход исследует обобщающие способности LLMs, предоставляя отдельную перспективу на силу их производительности контекстного обучения.
Эксперименты, проведенные исследователями, в основном сосредоточены на решении следующих вопросов:
- Как существующие предварительно обученные LLMs проявляют себя в BCTs?
- Как различные факторы влияют на границы принятия решений этих моделей?
- Как можно улучшить плавность границ принятия решений?
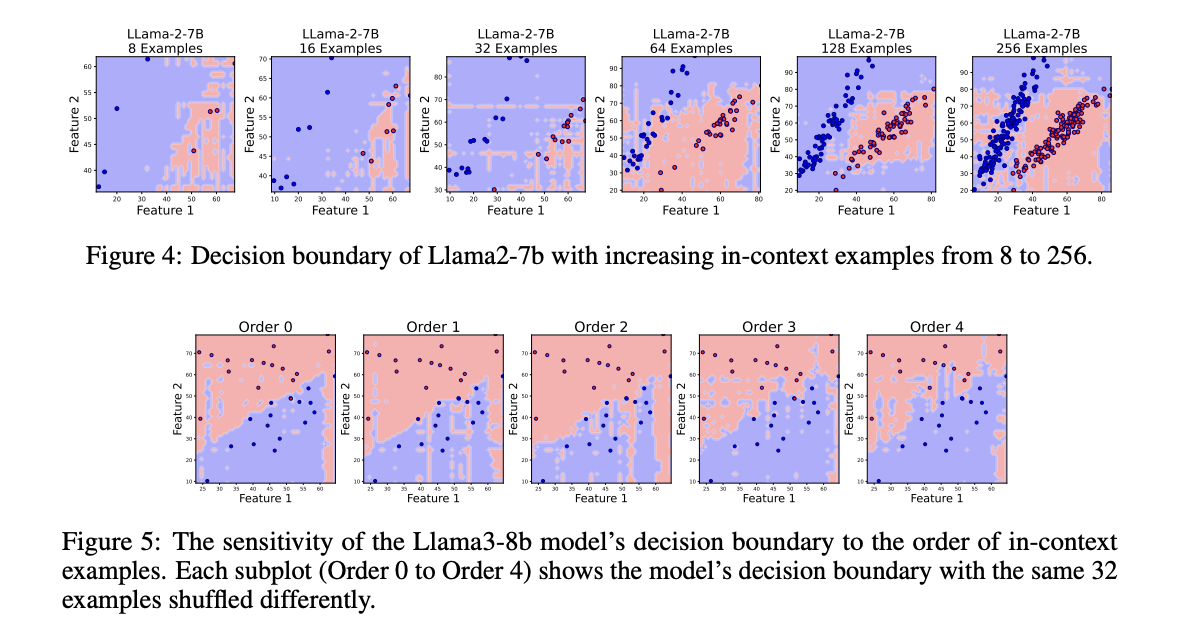
Границы принятия решений LLMs были изучены для классификационных задач, подталкивая их n контекстными примерами BCTs с равным количеством примеров для каждого класса. С использованием scikit-learn были созданы три типа наборов данных, представляющих различные формы границ принятия решений, такие как линейные, круглые и лунные. Более того, были изучены различные LLMs, включая модели с открытым исходным кодом, такие как Llama2-7B, Llama3-8B, Llama2-13B, Mistral-7B-v0.1 и sheared-Llama-1.3B, чтобы понять их границы принятия решений.
Результаты экспериментов продемонстрировали, что донастройка LLMs на контекстных примерах не приводит к более плавным границам принятия решений. Например, когда Llama3-8B был донастроен на 128 контекстных примерах обучения, полученные границы принятия решений остались не плавными. Таким образом, для улучшения плавности границ принятия решений LLMs на наборе задач классификации, предварительно обученная модель Llama была донастроена на наборе из 1000 бинарных классификационных задач, сгенерированных из scikit-learn, которые имели линейные, круглые или лунные границы с равными вероятностями.
В заключение, исследовательская группа предложила новый метод понимания контекстного обучения в LLMs, изучая их границы принятия решений в контекстном обучении в BCTs. Несмотря на получение высокой точности теста, было обнаружено, что границы принятия решений LLMs часто являются не плавными. Таким образом, через эксперименты были выявлены факторы, влияющие на эти границы принятия решений. Кроме того, были исследованы методы донастройки и адаптивной выборки, которые оказались эффективными в улучшении плавности границ. В будущем эти результаты предоставят новые идеи о механике контекстного обучения и предложат пути для исследований и оптимизации.
“`









