“`html
DaRec: Новая универсальная система выравнивания для LLM и совместных моделей
Системы рекомендаций приобрели значительное значение в различных областях применения благодаря впечатляющим возможностям алгоритмов на основе глубоких нейронных сетей. Большие языковые модели (LLM) недавно продемонстрировали свою компетентность в нескольких задачах, что побудило исследователей исследовать их потенциал в системах рекомендаций. Однако две основные проблемы мешают принятию LLM: высокие вычислительные требования и игнорирование коллаборативных сигналов.
Недавние исследования сосредоточились на методах семантического выравнивания для передачи знаний от LLM к коллаборативным моделям. Однако существует значительный семантический разрыв из-за разнообразной природы данных взаимодействия в коллаборативных моделях по сравнению с естественным языком, используемым в LLM. Попытки устранить этот разрыв через контрастное обучение показали ограничения, потенциально вводя шум и ухудшая производительность рекомендаций.
Практические решения и ценность:
Для преодоления этих проблем были использованы графовые нейронные сети (GNN), которые приобрели значение в системах рекомендаций, особенно для коллаборативной фильтрации. Методы, такие как LightGCN, NGCF и GCCF, используют GNN для моделирования взаимодействий пользователь-предмет, но сталкиваются с проблемами от шумной неявной обратной связи. Для смягчения этого были применены методы обучения без учителя, такие как контрастное обучение, с подходами, такими как SGL, LightGCL и NCL, показавшими улучшенную устойчивость и производительность.
LLM вызвали интерес в сфере рекомендаций, и исследователи исследуют способы интеграции их мощных представлений. Исследования, такие как RLMRec, ControlRec и CTRL, используют контрастное обучение для выравнивания встраиваний коллаборативной фильтрации с семантическими представлениями LLM.
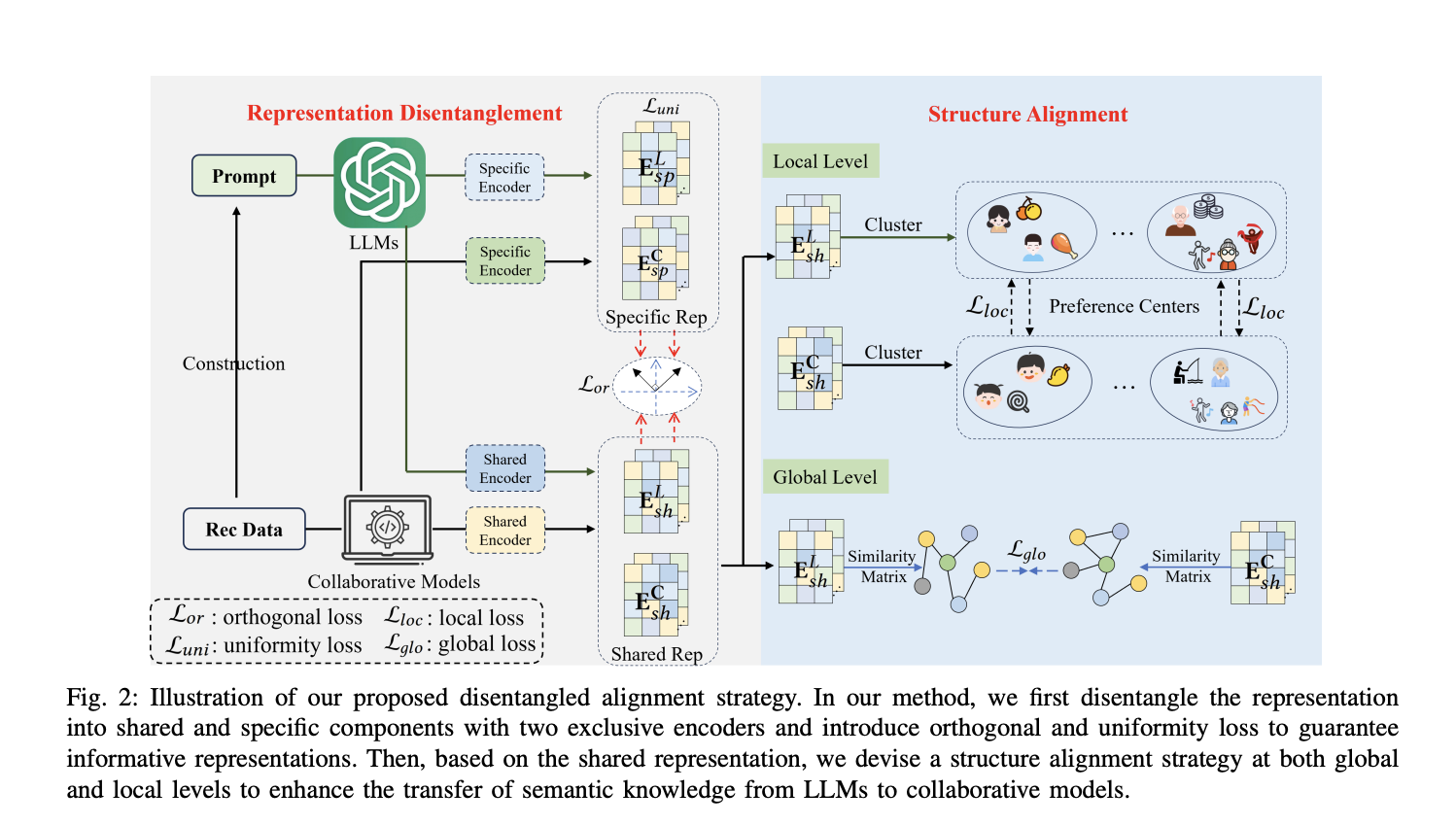
Исследователи из Национального университета обороны, Чанша, Baidu Inc, Пекин, и Ключевой лаборатории провинции Аньхой Университета науки и технологий Китая представили уникальную систему выравнивания для модели рекомендаций и LLM (DaRec), которая решает ограничения интеграции LLM с системами рекомендаций. Вдохновленная теоретическими исследованиями, она выравнивает семантические знания путем диссоциированного представления вместо точного выравнивания. Система состоит из трех ключевых компонент: (1) разделение представлений на общие и специфические компоненты для снижения шума, (2) применение униформности и ортогональной потери для поддержания информативности представлений и (3) реализация стратегии структурного выравнивания на локальном и глобальном уровнях для эффективной передачи семантических знаний.
Практические решения и ценность:
DaRec представляет собой инновационную систему для выравнивания семантических знаний между LLM и коллаборативными моделями в системах рекомендаций. Этот подход мотивирован теоретическими исследованиями, указывающими на то, что точное выравнивание представлений может быть неоптимальным. DaRec состоит из трех основных компонент:
Разделение представлений: Система разделяет представления на общие и специфические компоненты для коллаборативных моделей и LLM, что уменьшает негативное влияние специфической информации, которая может ввести шум во время выравнивания.
Униформность и ортогональные ограничения: DaRec использует функции потерь униформности и ортогональности для поддержания информативности представлений и обеспечения уникальной, дополняющей информации в специфических и общих компонентах.
Стратегия структурного выравнивания: Система реализует двухуровневый подход к выравниванию:
Глобальное структурное выравнивание: Выравнивает общую структуру общих представлений.
Локальное структурное выравнивание: Использует кластеризацию для выявления центров предпочтений и адаптивного выравнивания их.
DaRec стремится преодолеть ограничения предыдущих методов, предоставляя более гибкую и эффективную стратегию выравнивания, потенциально улучшающую производительность систем рекомендаций на основе LLM.
Результаты: DaRec превзошла как традиционные методы коллаборативной фильтрации, так и методы рекомендаций, усиленные LLM, на трех наборах данных (Amazon-book, Yelp, Steam) по нескольким метрикам (Recall@K, NDCG@K). Например, на наборе данных Yelp DaRec улучшила производительность по сравнению со вторым лучшим методом (AutoCF) на 3,85%, 1,57%, 3,15% и 2,07% по метрикам R@5, R@10, N@5 и N@10 соответственно.
Анализ гиперпараметров показал оптимальную производительность при числе кластеров K в диапазоне [4,8], параметре компромисса λ в диапазоне [0,1, 1,0] и размере выборки N̂ в 4096. Экстремальные значения этих параметров привели к снижению производительности.
Визуализация t-SNE показала, что DaRec успешно захватила основные кластеры интересов в предпочтениях пользователей.
В целом, DaRec показала превосходную производительность по сравнению с существующими методами, проявив устойчивость при различных значениях гиперпараметров и эффективно захватив структуры интересов пользователей.
Это исследование представляет DaRec, уникальную систему для выравнивания коллаборативных моделей и LLM в системах рекомендаций. Основываясь на теоретическом анализе, показывающем, что нулевое выравнивание может быть неоптимальным, DaRec разделяет представления на общие и специфические компоненты. Она реализует стратегию двухуровневого выравнивания структуры на глобальном и локальном уровнях. Авторы предоставляют теоретическое доказательство того, что их метод производит представления с более значимой и менее незначимой информацией для задач рекомендаций. Обширные эксперименты на эталонных наборах данных демонстрируют превосходную производительность DaRec по сравнению с существующими методами, представляя значительное преимущество в интеграции LLM с моделями коллаборативной фильтрации.
Проверьте статью. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter и присоединиться к нашему Telegram-каналу и группе LinkedIn. Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему SubReddit по машинному обучению с более чем 49 тыс. подписчиков.
Находите предстоящие вебинары по ИИ здесь
Статья оригинально опубликована на MarkTechPost.
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ) и оставалась в числе лидеров, грамотно используйте DaRec: A Novel Plug-and-Play Alignment Framework for LLMs and Collaborative Models.
Проанализируйте, как ИИ может изменить вашу работу. Определите, где возможно применение автоматизации: найдите моменты, когда ваши клиенты могут извлечь выгоду из AI.
Определитесь какие ключевые показатели эффективности (KPI): вы хотите улучшить с помощью ИИ.
Подберите подходящее решение, сейчас очень много вариантов ИИ. Внедряйте ИИ решения постепенно: начните с малого проекта, анализируйте результаты и KPI.
На полученных данных и опыте расширяйте автоматизацию.
Если вам нужны советы по внедрению ИИ, пишите нам на https://t.me/flycodetelegram
Попробуйте ИИ ассистент в продажах https://flycode.ru/aisales/ Этот ИИ ассистент в продажах, помогает отвечать на вопросы клиентов, генерировать контент для отдела продаж, снижать нагрузку на первую линию.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru
“`


























