Language Foundation Models (LFMs) and Large Language Models (LLMs)
Языковые модели и большие языковые модели продемонстрировали свою способность эффективно обрабатывать несколько задач с помощью одной фиксированной модели. Это побудило к разработке моделей основанных на изображениях, которые кодируют общую информацию изображений в векторы встраивания. Однако использование этих техник представляет собой вызов в анализе видео. Одним из подходов является обработка видео как последовательности изображений, где каждый кадр выбирается и встраивается перед объединением; однако этот подход сталкивается с трудностями в захвате детального движения и малых изменений между кадрами. Становится сложно понять непрерывный поток информации в видео, особенно когда речь идет о отслеживании движения объектов и незначительных изменениях между кадрами.
Преодоление вызовов в анализе видео
Существующие работы пытались преодолеть эти вызовы, используя два основных подхода на основе архитектуры Vision Transformer (ViT). Первый подход использует дистилляцию с высокопроизводительными моделями основанными на изображениях, такими как CLIP, в качестве учителей, и второй подход основан на маскированном моделировании, где модель предсказывает отсутствующую информацию из частичного ввода. Однако оба подхода имеют свои ограничения. Методы, основанные на дистилляции, такие как UMT и InternVideo2, испытывают трудности с бенчмарками, чувствительными к движению, такими как Something-Something-v2 и Diving-48. Методы, основанные на маскированном моделировании, такие как V-JEPA, плохо справляются с бенчмарками, сосредоточенными на внешнем виде, такими как Kinetics-400 и Moments-in-Time. Эти ограничения подчеркивают сложность захвата внешнего вида объектов и их движения в видео.
Предложение новой модели TWLV-I
Команда из Twelve Labs предложила TWLV-I, новую модель, разработанную для предоставления векторов встраивания для видео, которые захватывают внешний вид и движение. Несмотря на то, что обучалась только на общедоступных наборах данных, TWLV-I показывает высокую производительность на бенчмарках распознавания действий, сосредоточенных на внешнем виде и движении. Более того, модель достигает передовой производительности в задачах, связанных с видео, таких как временная и пространственно-временная локализация действий, а также сегментация действий во времени. Текущие методы оценки улучшены для анализа TWLV-I и других моделей основанных на видео, с новым аналитическим подходом и техникой определения способности модели различать видео на основе направления движения, независимо от внешнего вида.
Превосходство TWLV-I
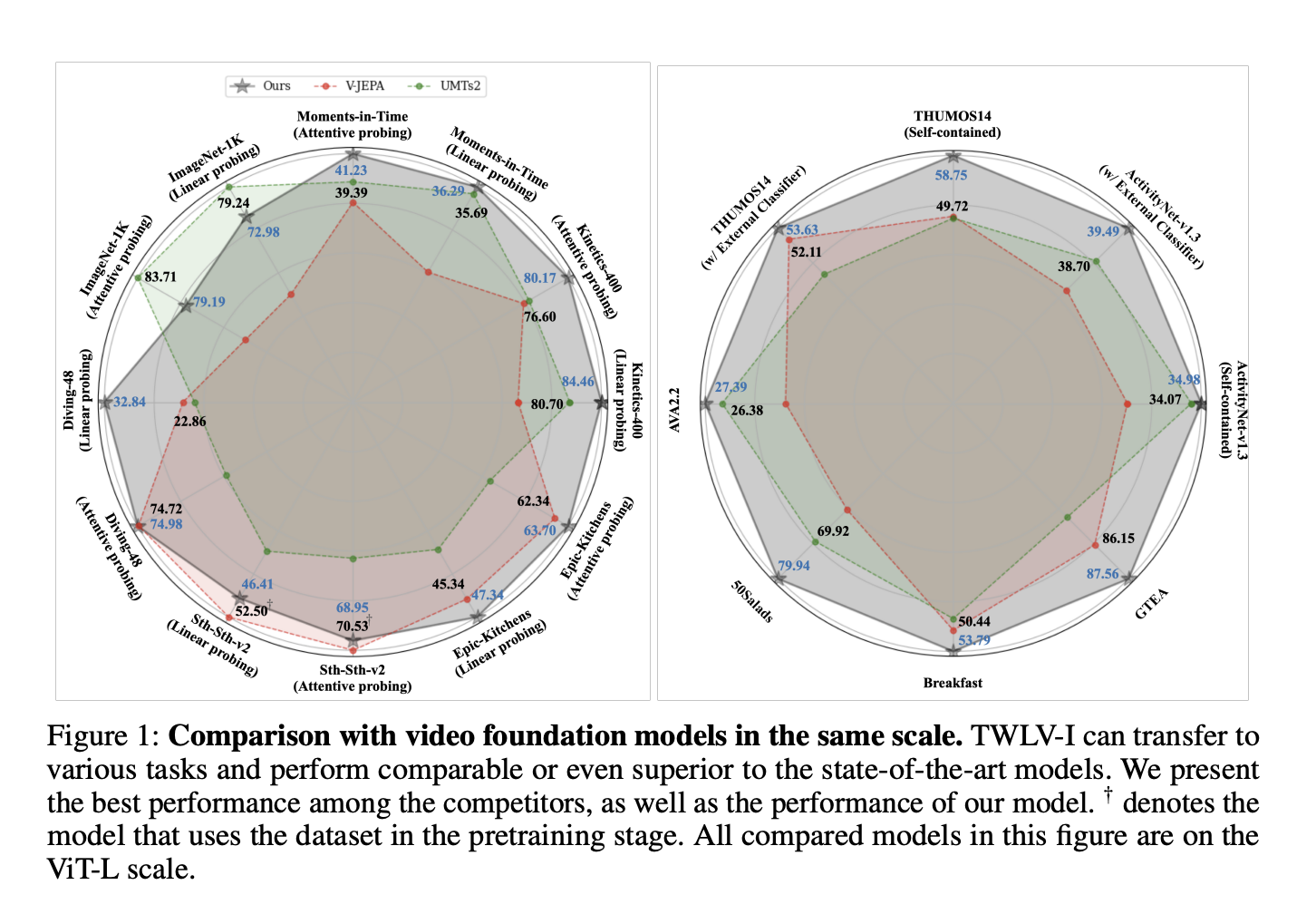
Результаты, полученные с помощью TWLV-I, показывают значительное улучшение производительности по сравнению с существующими моделями в задачах распознавания действий. Основываясь на средней точности линейного зондирования по пяти бенчмаркам распознавания действий и используя только общедоступные наборы данных для предварительного обучения, TWLV-I превосходит VJEPA (ViT-L) на 4,6% и UMT (ViT-L) на 7,7%. Эта модель превосходит более крупные модели, такие как DFN (ViT-H) на 7,2%, V-JEPA (ViT-H) на 2,7% и InternVideo2 (ViT-g) на 2,8%. Исследователи также предоставили векторы встраивания, сгенерированные TWLV-I, из широко используемых видео-бенчмарков и исходный код оценки, который может напрямую использовать эти встраивания.
Заключение
Модель TWLV-I и ее встраивания ожидаются широко использоваться в различных приложениях. Более того, методы оценки и анализа активно будут приняты в области моделей основанных на видео. В будущем ожидается, что эти методы будут направлять исследования в области понимания видео, способствуя дальнейшему развитию более комплексных моделей анализа видео.

























