«`html
NVIDIA представила Mistral-NeMo-Minitron 8B: новую модель ИИ, улучшающую эффективность и производительность через передовые методы обрезки и дистилляции знаний
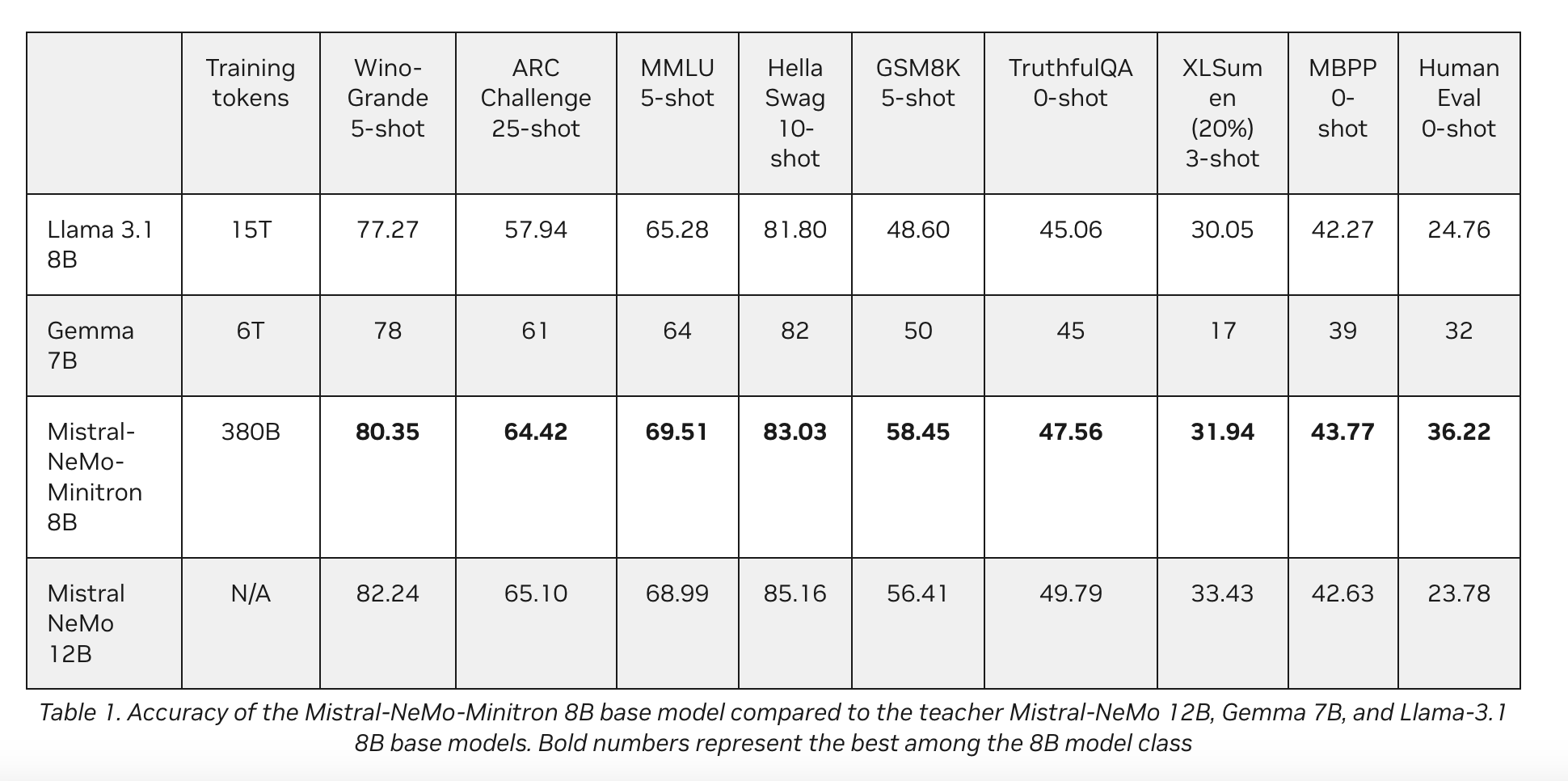
Компания NVIDIA представила Mistral-NeMo-Minitron 8B, высокоуровневую модель большого языка (LLM). Эта модель продолжает работу по разработке передовых технологий искусственного интеллекта. Она выделяется своей впечатляющей производительностью на различных показателях, что делает ее одной из самых передовых моделей в своем классе по доступности.
Процесс обрезки модели и дистилляции
Обрезка модели — это техника уменьшения размера и повышения эффективности моделей ИИ путем удаления менее важных компонентов. В случае Mistral-NeMo-Minitron 8B была выбрана обрезка по ширине для достижения оптимального баланса между размером и производительностью.
После обрезки модель проходит процесс легкой переобучения с использованием дистилляции знаний. Целью является создание более быстрой и менее ресурсоемкой модели при сохранении высокой точности.
Производительность и бенчмаркинг
Производительность Mistral-NeMo-Minitron 8B свидетельствует о успехе подхода обрезки и дистилляции. Модель последовательно превосходит другие модели своего класса по различным популярным бенчмаркам.
Технические детали и архитектура
Архитектура модели Mistral-NeMo-Minitron 8B построена на декодере трансформера для авторегрессивного языкового моделирования. Она включает в себя такие передовые техники, как Grouped-Query Attention (GQA) и Rotary Position Embeddings (RoPE), что обеспечивает устойчивую производительность в различных задачах.
Будущие направления и этические соображения
Выпуск Mistral-NeMo-Minitron 8B — это только начало усилий компании NVIDIA по разработке более компактных и эффективных моделей через обрезку и дистилляцию. Однако важно учитывать ограничения и этические соображения данной модели.
Заключение
Внедрение Mistral-NeMo-Minitron 8B от NVIDIA открывает новый стандарт эффективности и производительности в обработке естественного языка.
«`

























