CycleFormer: новая модель трансформера для проблемы коммивояжера (TSP)
Множество новаторских моделей, включая ChatGPT, Bard, LLaMa, AlphaFold2 и Dall-E 2, появились в различных областях с момента появления трансформера в обработке естественного языка (NLP). Попытки решить комбинаторные задачи оптимизации, такие как проблема коммивояжера (TSP), с использованием глубокого обучения логически продвигались от сверточных нейронных сетей (CNN) к рекуррентным нейронным сетям (RNN) и, наконец, к моделям на основе трансформеров. Использование координат N городов (узлов, вершин, токенов) TSP определяет кратчайший гамильтонов цикл, проходящий через каждый узел. Вычислительная сложность растет экспоненциально с увеличением числа городов, что делает ее представительной NP-трудной задачей в информатике.
Решение проблемы
Итеративные алгоритмы улучшения и стохастические алгоритмы – две основные категории, в которые попадают эвристические алгоритмы. Существует много усилий, но они все еще не могут сравниться с лучшими эвристическими алгоритмами. Производительность трансформера критически важна, поскольку он является двигателем, решающим проблемы конвейера; однако это аналогично AlphaGo, который сам по себе был недостаточно мощным, но победил лучших профессионалов в мире, объединив постобрабатывающие техники поиска, такие как Монте-Карло дерево поиска (MCTS). Выбор следующего города для посещения, в зависимости от уже посещенных, лежит в основе TSP, и трансформер, модель, которая пытается обнаружить отношения между узлами с использованием механизмов внимания, хорошо подходит для этой задачи. Из-за его первоначального проектирования для языковых моделей трансформер представлял метафорические вызовы в предыдущих исследованиях, когда он применялся к области TSP.
Среди многих различий между трансформатором в языковой области и трансформатором в области TSP является значение токенов. Слова и их подслова считаются токенами в области языков. С другой стороны, в области TSP каждый узел обычно превращается в токен. В отличие от набора слов, набор координат узлов является бесконечным, непредсказуемым и несвязанным. Индексы токенов и пространственная связь между соседними токенами бесполезны в этой организации. Еще одно важное различие – дублирование. В отношении решений TSP, в отличие от лингвистических областей, гамильтонов цикл не может быть сформирован путем декодирования одного и того же города более одного раза. Во время декодирования TSP используется маска посещенных, чтобы избежать повторения.
Результаты исследования
Исследователи из Сеульского национального университета представляют CycleFormer, решение TSP на основе трансформеров. В этой модели исследователи объединяют лучшие особенности модели трансформера на основе обучения с учителем (SL) с особенностями TSP. Текущие решатели TSP на основе трансформеров ограничены, поскольку они обучаются с использованием RL. Это мешает им полностью использовать преимущества SL, такие как более быстрое обучение благодаря маске посещенных и более стабильная сходимость. NP-трудность TSP делает невозможным для оптимальных решателей SL знать глобальный оптимум при увеличении размеров проблемы. Однако это ограничение можно обойти, если трансформер, обученный на проблемах разумного размера, является обобщаемым и масштабируемым. Следовательно, на данный момент SL и RL будут сосуществовать.
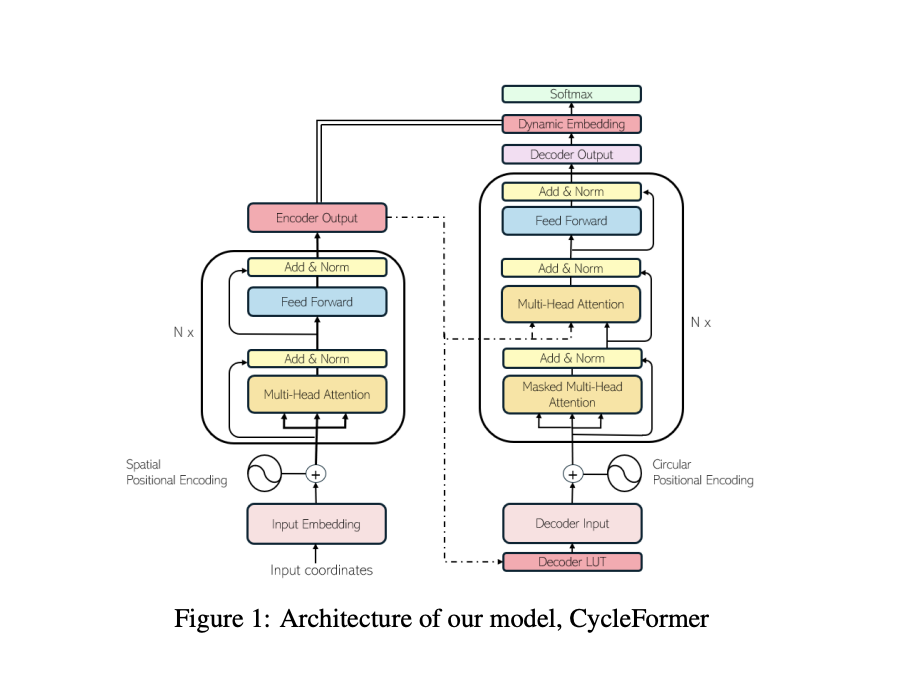
Эксклюзивное внимание команды сосредоточено на симметричной TSP, определяемой расстоянием между любыми двумя точками и постоянной во всех направлениях. Они существенно изменили первоначальное проектирование, чтобы гарантировать, что трансформер воплощает свойства TSP. Поскольку решение TSP является циклическим, они обеспечили, что их позиционное кодирование (PE) на стороне декодера будет нечувствительным к вращению и отражению. Таким образом, начальный узел тесно связан с узлами в начале и конце тура, но очень несвязан с узлами посередине.
Исследователи используют 2D координаты кодировщика для пространственного позиционного кодирования. Используемые кодирования позиций кодировщика и декодера полностью различны. Контекстное вложение (память) из выхода кодировщика служит входом для декодера. Эта стратегия позволяет быстро максимизировать использование полученной информации, используя тот факт, что набор токенов, используемых в кодировщике и декодере, одинаков в TSP. Они заменяют последний линейный слой трансформера на динамическое вложение; это контекстное кодирование графа и действует как выход кодировщика (память).
Использование позиционного кодирования и токенного кодирования, а также изменение входа декодера и использование контекстного вектора кодировщика в выходе декодера – два способа, которыми CycleFormer существенно отличается от первоначального трансформера. Эти улучшения демонстрируют потенциал решателей TSP на основе трансформеров для улучшения путем применения стратегий улучшения производительности, используемых в больших языковых моделях (LLM), таких как увеличение размерности вложения и количество блоков внимания. Это подчеркивает текущие вызовы и захватывающие возможности для будущих достижений в этой области.
Согласно обширным экспериментальным результатам, с этими характеристиками дизайна CycleFormer может превзойти SOTA-модели на основе трансформеров, сохраняя форму трансформера в TSP-50, TSP-100 и TSP-500. “Оптимальный разрыв”, термин, используемый для измерения разницы между лучшим возможным решением и решением, найденным моделью, между SOTA и TSP-500 во время многократного декодирования составляет от 3,09% до 1,10%, улучшение в 2,8 раза благодаря CycleFormer.
Предложенная модель, CycleFormer, имеет потенциал превзойти SOTA-альтернативы, такие как Pointerformer. Ее соблюдение архитектуры трансформера позволяет включать дополнительные подходы LLM, такие как увеличение размерности вложения и стекание нескольких блоков внимания, для улучшения производительности. При увеличении размера проблемы методы ускорения вывода в больших языковых моделях, такие как Retention и DeepSpeed, могут оказаться выгодными. Хотя исследователи не могли экспериментировать с TSP-1000 из-за ограничений ресурсов, они считают, что с достаточным количеством оптимальных ответов TSP-1000 CycleFormer может превзойти существующие модели. Они планируют включить MCTS в качестве постобработки в будущих исследованиях для дальнейшего улучшения производительности CycleFormer.
Подробнее ознакомьтесь с документом. Вся заслуга за это исследование принадлежит исследователям этого проекта. Также не забудьте подписаться на наш Twitter. Присоединяйтесь к нашему каналу в Telegram, каналу в Discord и группе в LinkedIn.
Если вам понравилась наша работа, вам понравится наша рассылка.
Не забудьте присоединиться к нашему 43k+ ML SubReddit. Также ознакомьтесь с нашей платформой AI Events.









