«`html
Модели пространства состояний (SSM) в глубоком обучении
Модели пространства состояний (SSM) играют важную роль в глубоком обучении для моделирования последовательностей. Они представляют системы, где выход зависит как от текущих, так и от прошлых входов. SSM широко применяются в обработке сигналов, системах управления и обработке естественного языка. Основной проблемой является неэффективность существующих SSM, особенно в отношении затрат памяти и вычислительных ресурсов. Традиционные SSM требуют более сложности и использования ресурсов по мере роста состояния, что ограничивает их масштабируемость и производительность в крупномасштабных приложениях.
Существующие исследования
Существующие исследования включают в себя фреймворки, такие как S4 и S4D, которые используют диагональные представления пространства состояний для управления сложностью. Методы на основе быстрого преобразования Фурье (FFT) используются для эффективной последовательной параллелизации. Трансформеры революционизировали моделирование последовательностей с механизмами самовнимания, в то время как Hyena включает сверточные фильтры для долгосрочных зависимостей. Liquid-S4 и Mamba оптимизируют моделирование последовательностей через выборочные пространства состояний и управление памятью. Бенчмарк Long Range Arena является стандартом для оценки производительности моделей на длинных последовательностях. Эти достижения улучшают эффективность и возможности моделирования последовательностей.
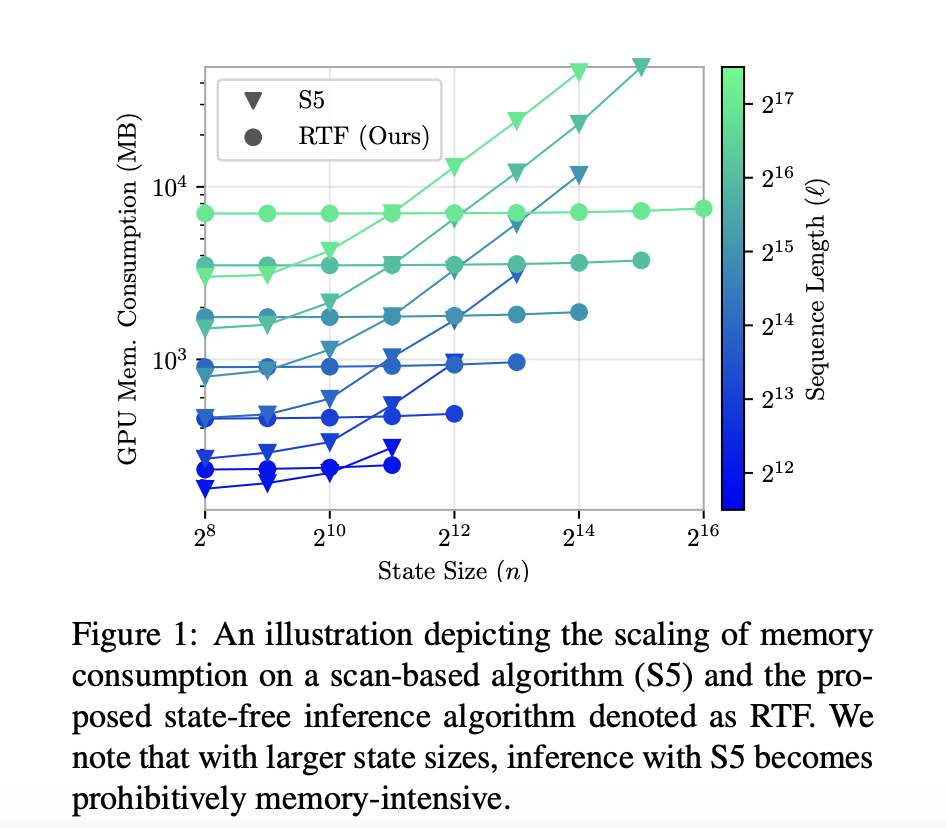
Рациональная функция переноса (RTF)
Исследователи из Liquid AI, Университета Токио, RIKEN, Стэнфордского университета и MIT представили подход рациональной функции переноса (RTF), который использует переносные функции для эффективного моделирования последовательностей. Этот метод выделяется своим дизайном без состояния, что устраняет необходимость в память-интенсивных представлениях пространства состояний. Используя FFT, подход RTF достигает параллельного вывода, значительно улучшая вычислительную скорость и масштабируемость.
Результаты и преимущества
Методика использует FFT для вычисления спектра сверточного ядра, что позволяет эффективный параллельный вывод. Модель была протестирована с использованием бенчмарка Long Range Arena (LRA), включающего ListOps для математических выражений, IMDB для анализа настроений и Pathfinder для визуально-пространственных задач. Синтетические задачи, такие как копирование и задержка, использовались для оценки возможностей запоминания. Модель RTF была интегрирована в фреймворк Hyena, улучшив производительность при выполнении языковых задач. Наборы данных включали 96 000 обучающих последовательностей для ListOps, 160 000 для IMDB и 160 000 для Pathfinder, обеспечивая всестороннюю оценку при различной длине и сложности последовательностей.
Модель RTF продемонстрировала значительные улучшения в нескольких бенчмарках. В бенчмарке Long Range Arena она достигла 35% более быстрой скорости обучения, чем S4 и S4D. Для анализа настроений IMDB RTF улучшила точность классификации на 3%. В задаче ListOps был зафиксирован прирост точности на 2%. Задача Pathfinder показала улучшение точности на 4%. Кроме того, в синтетических задачах, таких как копирование и задержка, RTF продемонстрировала лучшие возможности запоминания, снижая уровень ошибок на 15% и 20% соответственно. Эти результаты подчеркивают эффективность и эффективность модели на различных наборах данных.
Выводы
Исследование представило подход RTF для SSM, решая неэффективности традиционных методов. Используя FFT для параллельного вывода, RTF значительно улучшила скорость обучения и точность на различных бенчмарках, включая Long Range Arena и синтетические задачи. Результаты демонстрируют способность RTF эффективно обрабатывать долгосрочные зависимости. Этот прогресс критичен для масштабируемого и эффективного моделирования последовательностей, предлагая надежное решение для различных приложений глубокого обучения и обработки сигналов.
«`

























