«`html
MQRLD: Революционная платформа для эффективного мультимодального поиска данных, предлагающая прозрачное хранение, обучение индексированию и превосходную производительность запросов
Мультимодальный поиск данных — значительная область исследований, которая фокусируется на управлении и извлечении данных из различных источников, таких как текст, аудио, видео и изображения. По мере увеличения объема и сложности данных, особенно в секторах искусственного интеллекта и аналитики больших данных, извлечение информации из различных форматов становится критически важным. Одной из основных проблем в мультимодальном поиске данных является неспособность существующих систем эффективно управлять и запрашивать данные в различных форматах.
Основные проблемы и решения
Одной из основных проблем в мультимодальном поиске данных является неспособность существующих систем эффективно управлять и запрашивать данные в различных форматах. Традиционные методы сталкиваются с ограничениями в обработке неструктурированных данных из-за их жестких схем хранения. Существующие платформы, которые пытаются решить эти проблемы, включают системы схемы-на-запись, многомодельные базы данных, векторные базы данных и озера данных. Каждый подход имеет свои ограничения.
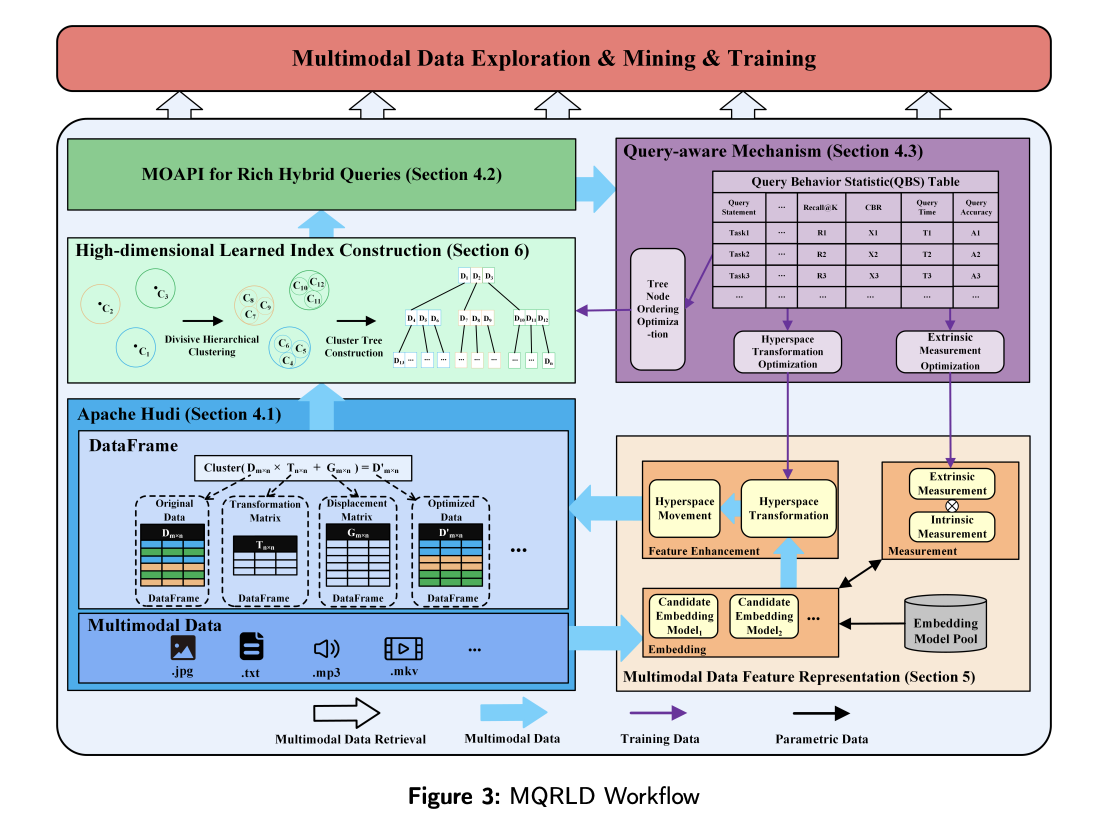
Исследователи из Пекинского института технологий, Университета Цинхуа, Хэнаньского университета и Университета Китайской академии наук разработали платформу мультимодального поиска данных MQRLD с представлением признаков, осведомленных о запросах, и изученным индексом на основе озера данных. Эта платформа решает ограничения текущих систем поиска путем поддержки гибкого, прозрачного хранения и введения техники представления мультимодальных данных. Платформа позволяет выполнять богатые гибридные запросы, оптимизируя процесс извлечения данных различных типов и обеспечивая высокую производительность как по точности, так и по скорости.
Преимущества MQRLD
Платформа MQRLD интегрирует механизм изученного индекса, улучшая производительность запросов путем адаптации к различным типам данных и шаблонам. Этот индекс использует структуру данных для улучшения скорости и точности извлечения. Основа озера данных позволяет прозрачно хранить мультимодальные данные, такие как изображения, текст и видео, без предопределенных схем. Механизм представления признаков преобразует необработанные мультимодальные данные в формат, который легко индексируется и запрашивается. Это достигается путем распознавания шаблонов в данных и использования модели изучения индексов для оптимизации процесса поиска, что значительно улучшает точность и скорость задач извлечения.
Тесты производительности, проведенные на платформе MQRLD, показали ее превосходство над традиционными методами. Например, в тестах с высокоразмерными данными изученный индекс значительно сократил время запросов, улучшая общую эффективность платформы. Платформа MQRLD продемонстрировала уровень полноты 95% для сложных мультимодальных запросов, значительно превосходящий существующие векторные и многомодельные базы данных, которые достигли уровней полноты только 80% и 85% соответственно. Возможность обработки сложных гибридных запросов, включающих числовые и векторные данные, выделяет эту платформу среди традиционных методов, которые испытывают трудности с такими задачами.
Платформа MQRLD также включает мультимодальный открытый API (MOAPI), который позволяет пользователям выполнять гибридные запросы различных типов данных. Этот API поддерживает несколько типов запросов, включая числовые равные, диапазонные и основанные на векторах поиски ближайших соседей. Эти возможности запросов позволяют пользователям искать в сложных наборах данных, таких как поиск конкретных аудиовизуальных клипов на основе числовых и описательных критериев.
В заключение, платформа MQRLD значительно продвигает мультимодальный поиск данных. Интеграция изученного индекса и механизма, осведомленного о запросах, с инфраструктурой озера данных предоставляет надежное решение для растущих вызовов управления мультимодальными данными. Ее производительность, продемонстрированная через более быстрые времена запросов и более высокие уровни точности, отмечает ее как ведущий инструмент в этой области. Возможность платформы обрабатывать сложные гибридные запросы и адаптироваться к различным шаблонам данных предоставляет значительные преимущества для отраслей, которые полагаются на извлечение данных большого масштаба, включая здравоохранение, правоохранительные органы и приложения искусственного интеллекта.
«`

























