«`html
Новые модели языковых моделей Minitron 4B и 8B от Nvidia AI: ускорение обучения моделей в 40 раз благодаря обрезке и дистилляции
Большие языковые модели (LLM), созданные для понимания и генерации человеческого языка, нашли применение в машинном переводе, анализе настроений и разговорном искусственном интеллекте. Однако их обучение и развертывание требуют значительных вычислительных ресурсов и больших наборов данных, что приводит к значительным затратам.
Основные проблемы и решения
Одной из основных проблем является ресурсоемкость обучения различных вариантов LLM с нуля. Для решения этой проблемы исследователи разработали метод структурированной обрезки, который позволяет значительно уменьшить размер модели и затраты на обучение, сохраняя при этом ее производительность.
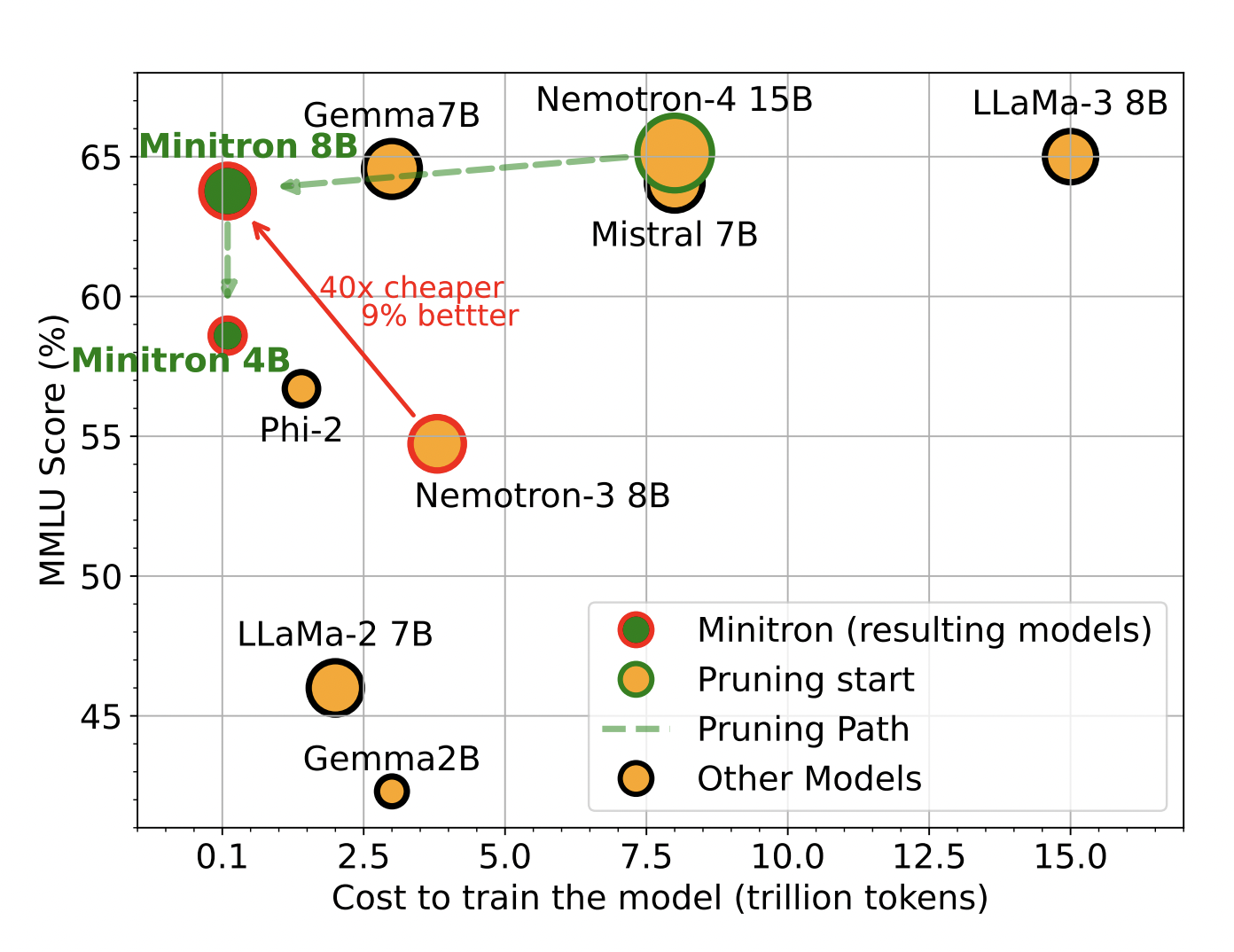
Предложенный метод начинается с существующей большой модели, которую обрезают, чтобы создать более эффективные варианты. Затем прунингованная модель проходит процесс переобучения на основе дистилляции знаний, что помогает восстановить точность модели. Это позволяет существенно сократить затраты на обучение и время.
Результаты и преимущества
Используя этот метод, удалось достичь уменьшения размера модели в 2-4 раза при сохранении сопоставимого уровня производительности. Это привело к экономии затрат на обучение моделей в 1,8 раза. Также было продемонстрировано улучшение показателей производительности на 16% по сравнению с моделями, обученными с нуля. Модели Minitron также оказались сопоставимы с другими известными моделями, превзойдя современные методы сжатия из существующей литературы.
Эти модели были сделаны доступными для общественного использования на платформе Huggingface, предоставляя сообществу доступ к оптимизированным моделям.
Заключение
Исследователи компании NVIDIA продемонстрировали, что структурированная обрезка в сочетании с дистилляцией знаний может значительно снизить затраты и ресурсы, необходимые для обучения больших языковых моделей. Этот инновационный подход открывает путь к более доступным и эффективным приложениям в области обработки естественного языка, делая возможным развертывание LLM на различных масштабах без запредельных затрат.
«`

























