Применение Разработанной Системы Категоризации Запросов для Улучшения Точности Больших Языковых Моделей
Большие языковые модели (LLM) изменили область искусственного интеллекта своей способностью генерировать текст, близкий к человеческому, и выполнять сложные рассуждения. Однако LLM требуют помощи в выполнении задач, требующих знания в специфических областях, особенно в здравоохранении, праве и финансах. Для преодоления ограничений таких моделей предлагается улучшить их с помощью внешних данных. Интеграция соответствующей информации делает модели более точными и эффективными, значительно повышая их производительность. Техника Retrieval-Augmented Generation (RAG) – яркий пример такого подхода, позволяющая LLM извлекать необходимые данные в процессе генерации для предоставления более точных и своевременных ответов.
Проблемы и Решения
Одной из основных проблем в развертывании LLM является их неспособность обрабатывать запросы, требующие конкретной и актуальной информации. В то время как LLM высокоэффективны в работе с общими знаниями, они терпят неудачи при выполнении специализированных или оперативных запросов. Такое происходит из-за того, что большинство моделей обучаются на статических данных и могут обновлять свои знания только с внешними входными данными. Поэтому важно разработать модель, способную динамически привлекать соответствующие данные для удовлетворения конкретных потребностей этих областей.
Существующие решения, такие как fine-tuning и RAG, сделали определенные шаги в решении этих проблем. Fine-tuning позволяет переобучить модель на данных, специфичных для области, настраивая ее для конкретных задач. Однако этот подход требует много времени и обширных обучающих данных, которые не всегда доступны. Более того, fine-tuning часто приводит к переобучению, когда модель становится слишком специализированной и нуждается в помощи с общими запросами. С другой стороны, RAG предлагает более гибкий подход. Вместо полаганиясь только на предварительно обученные знания, RAG позволяет моделям извлекать внешние данные в реальном времени, улучшая их точность и актуальность. Несмотря на свои преимущества, RAG все еще сталкивается с несколькими проблемами, например, сложность обработки неструктурированных данных, которые могут представляться в виде текста, изображений и таблиц.
Преимущества Исследования
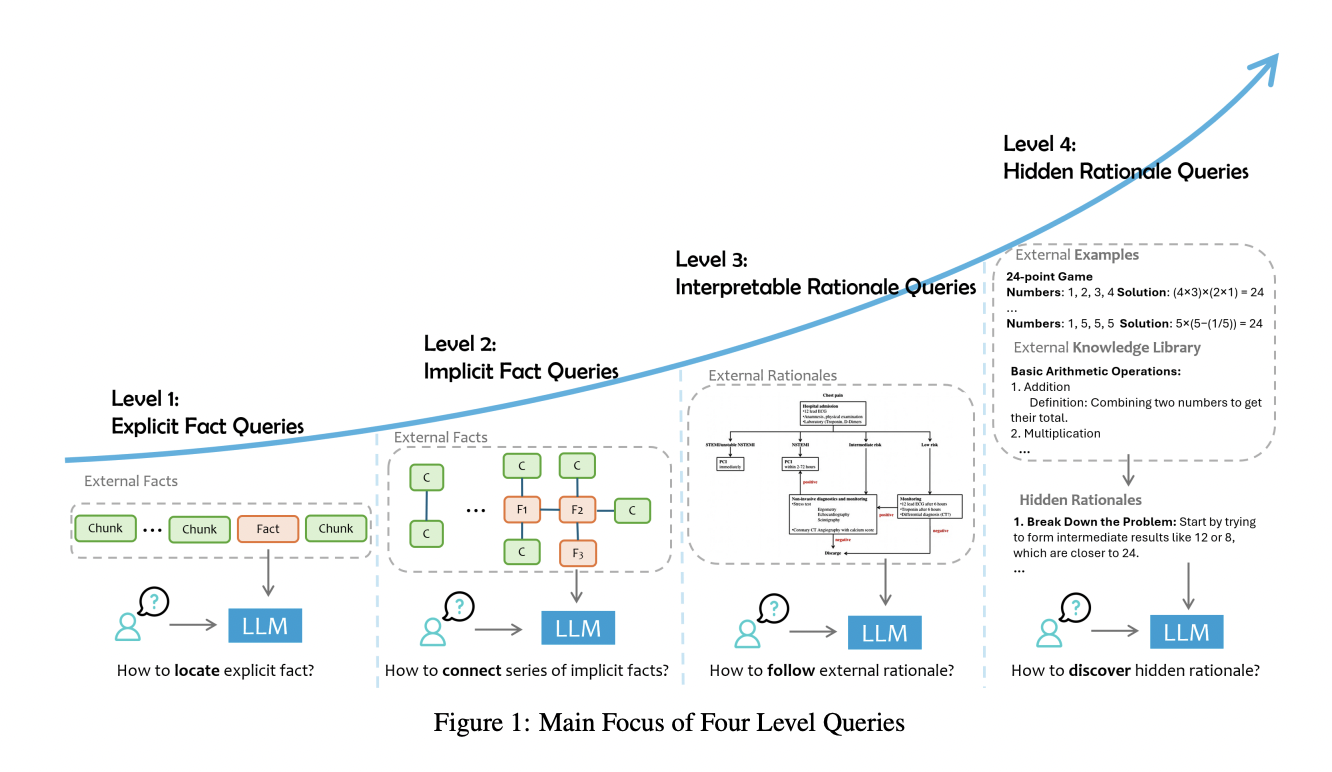
Исследователи из Microsoft Research Asia предложили новый метод, который категоризирует запросы пользователей на четыре уровня в зависимости от сложности и типа необходимых внешних данных. Эти уровни включают явные факты, неявные факты, интерпретируемые обоснования и скрытые обоснования. Такая категоризация помогает настроить подход модели к извлечению и обработке данных, обеспечивая выбор наиболее релевантной информации для задачи. Например, запросы на явные факты включают простые вопросы, например, “Какая столица Франции?”, где ответ можно извлечь из внешних данных. Запросы на неявные факты требуют более сложного рассуждения, например, объединения нескольких фрагментов информации для вывода заключения. Запросы на интерпретируемые обоснования включают в себя предписания, характерные для конкретной области, тогда как запросы на скрытые обоснования требуют глубокого рассуждения и часто занимаются абстрактными концепциями.
Метод, предложенный Microsoft Research, позволяет LLM различать эти типы запросов и применять соответствующий уровень рассуждения. Например, в случае запросов на скрытые обоснования, где нет четкого ответа, модель может выявлять закономерности и использовать методы рассуждения, характерные для конкретной области, для формирования ответа. Разбив запросы на эти категории, модель становится более эффективной в извлечении необходимой информации и предоставлении точных, контекстно обусловленных ответов. Такая категоризация также помогает снизить вычислительную нагрузку на модель, поскольку теперь она может сосредоточиться на извлечении только данных, релевантных для типа запроса, а не сканировании огромного объема несвязанной информации.
Результаты
Проведенное исследование подчеркивает впечатляющие результаты данного подхода. Система значительно улучшила производительность в специализированных областях, таких как здравоохранение и анализ права. Например, в приложениях в области здравоохранения модель снизила частоту галлюцинаций до 40%, предоставляя более обоснованные и надежные ответы. Точность модели в обработке сложных документов и предоставлении детального анализа увеличилась на 35% в правовых системах. В целом, предложенный метод позволил более точно извлекать релевантные данные, что привело к лучшим решениям и более надежным результатам. Исследование показало, что системы на основе RAG снизили число случаев галлюцинаций, опираясь ответы модели на проверяемые данные, улучшая точность в критических приложениях, таких как медицинская диагностика и обработка правовых документов.
В заключение, это исследование предлагает важное решение одной из фундаментальных проблем в развертывании LLM в специализированных областях. За счет введения системы категоризации запросов на основе сложности и типа, исследователи из Microsoft Research разработали метод, который повышает точность и интерпретируемость выводов LLM. Такой подход позволяет LLM извлекать наиболее релевантные внешние данные и эффективно применять их к специфическим запросам, снижая галлюцинации и улучшая общую производительность. Исследование продемонстрировало, что использование структурированной категоризации запросов может улучшить результаты на 40%, что является значительным шагом вперед в системах на основе ИИ. Решая проблему извлечения данных и интеграции внешних знаний, данное исследование предлагает путь к более надежным и прочным приложениям LLM в различных отраслях.