Представляем Инфраструктуру Predibase для Инференции
Predibase анонсирует Predibase Inference Engine — новую инфраструктуру для обслуживания тонко настроенных малых языковых моделей (SLMs). Это решение значительно ускоряет развертывание SLM, упрощает масштабирование и снижает затраты для компаний, работающих с ИИ.
Проблемы при развертывании языковых моделей
С увеличением интеграции ИИ в бизнес, компании сталкиваются с рядом сложностей:
- Проблемы с производительностью: Многие облачные провайдеры не могут обеспечить стабильную работу при высоких нагрузках.
- Сложность инженерии: Использование открытых моделей требует значительных ресурсов для управления инфраструктурой.
- Высокие затраты на инфраструктуру: Доступ к мощным GPU ограничен и может быть дорогим.
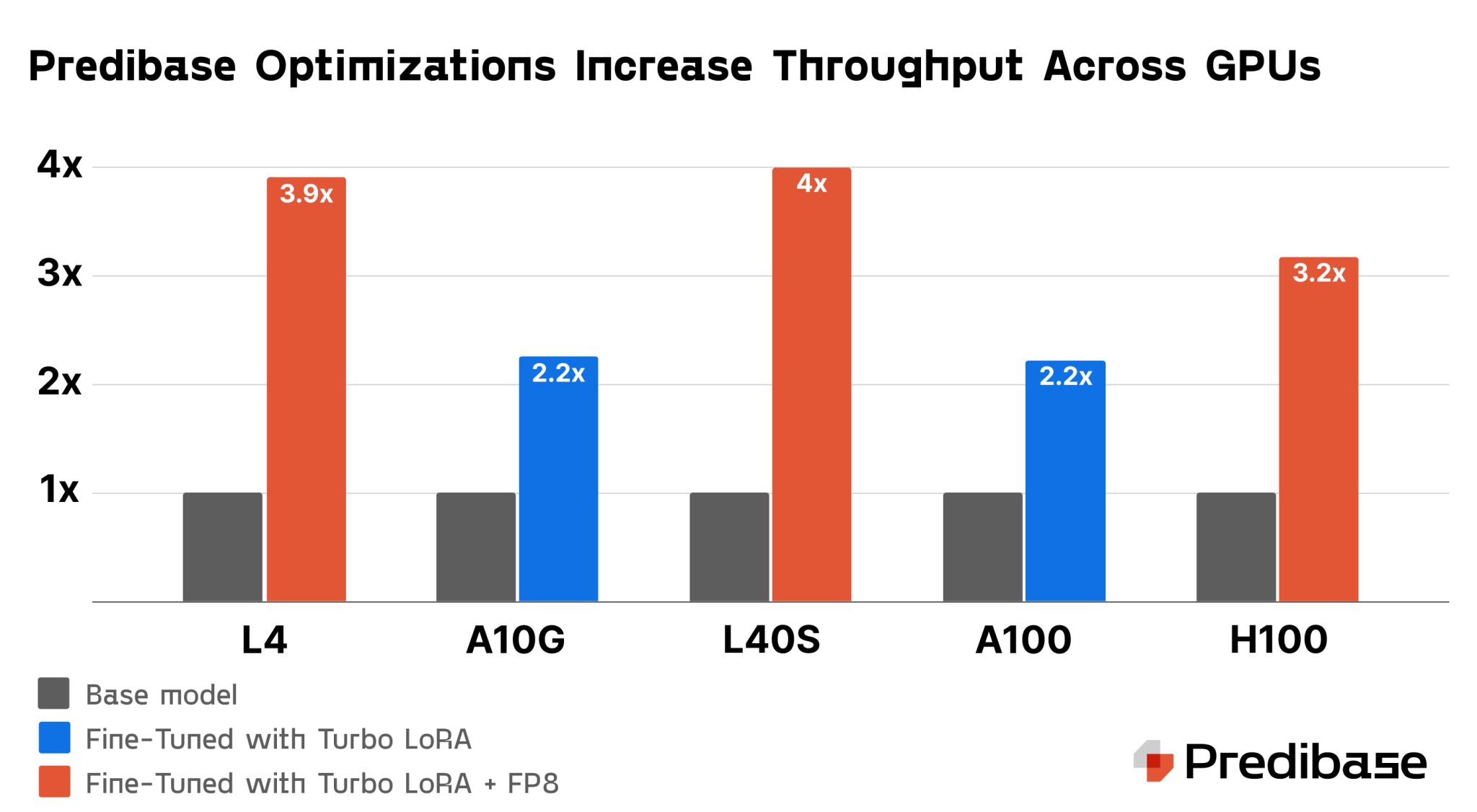
Решения от Predibase
Predibase Inference Engine предлагает решения для этих проблем:
- LoRAX: Позволяет использовать сотни SLM с одного GPU, что значительно снижает затраты.
- Turbo LoRA: Увеличивает скорость обработки в 2-3 раза, не ухудшая качество ответов.
- FP8 Квантование: Снижает объем памяти на 50%, увеличивая производительность.
- Автоскейлинг GPU: Адаптирует ресурсы в зависимости от реального спроса, что позволяет экономить.
Гибкость и доступность
Predibase Inference Engine доступен как в облаке Predibase, так и в вашей инфраструктуре. Это обеспечивает интеграцию с существующими системами безопасности и соответствия.
Многорегиональная высокая доступность
Функция многорегионального развертывания гарантирует непрерывность обслуживания даже при сбоях в регионе.
Аналитика производительности в реальном времени
Инструменты аналитики позволяют отслеживать важные метрики, оптимизируя работу инфраструктуры и снижая затраты.
Почему выбирают Predibase?
Predibase — ведущая платформа для обслуживания тонко настроенных языковых моделей, предлагающая надежную и безопасную инфраструктуру. Если вы хотите улучшить развертывание ваших моделей ИИ, посетите сайт Predibase.com и узнайте больше о Predibase Inference Engine.

























