Обнаружение произнесенных терминов (STD)
Обнаружение произнесенных терминов (STD) — это важная область обработки речи, которая позволяет идентифицировать конкретные фразы или термины в больших аудиархивах. Эта технология широко используется в голосовых поисках, услугах транскрипции и индексировании мультимедиа. STD улучшает доступность и удобство использования аудиоданных, особенно в таких областях, как подкасты, лекции и трансляции.
Проблемы и вызовы
Среди основных проблем обнаружения произнесенных терминов — это эффективная обработка терминов, не входящих в словарь (OOV), и вычислительные требования существующих систем. Традиционные методы часто зависят от систем автоматического распознавания речи (ASR), которые требуют много ресурсов и подвержены ошибкам, особенно для коротких аудиосегментов или в условиях переменной акустики.
Новые решения
Исследователи из Индийского института технологий Канпур и университета имек в Генте разработали новую систему токенизации речи под названием BEST-STD. Этот подход кодирует речь в дискретные семантические токены, что позволяет эффективно извлекать информацию с помощью текстовых алгоритмов. Использование двунаправленного кодировщика Mamba обеспечивает высокую согласованность токенов при различных произношениях одного и того же термина.
Преимущества BEST-STD
Система BEST-STD использует двунаправленный кодировщик Mamba, который обрабатывает аудиовход в обоих направлениях, захватывая дальние зависимости. Каждая часть кодировщика проецирует аудиоданные в высокоразмерные встраивания, которые затем дискретизируются в последовательности токенов. Система демонстрирует высокую скорость извлечения и эффективность благодаря использованию инвертированного индекса для токенизированных последовательностей.
Результаты и достижения
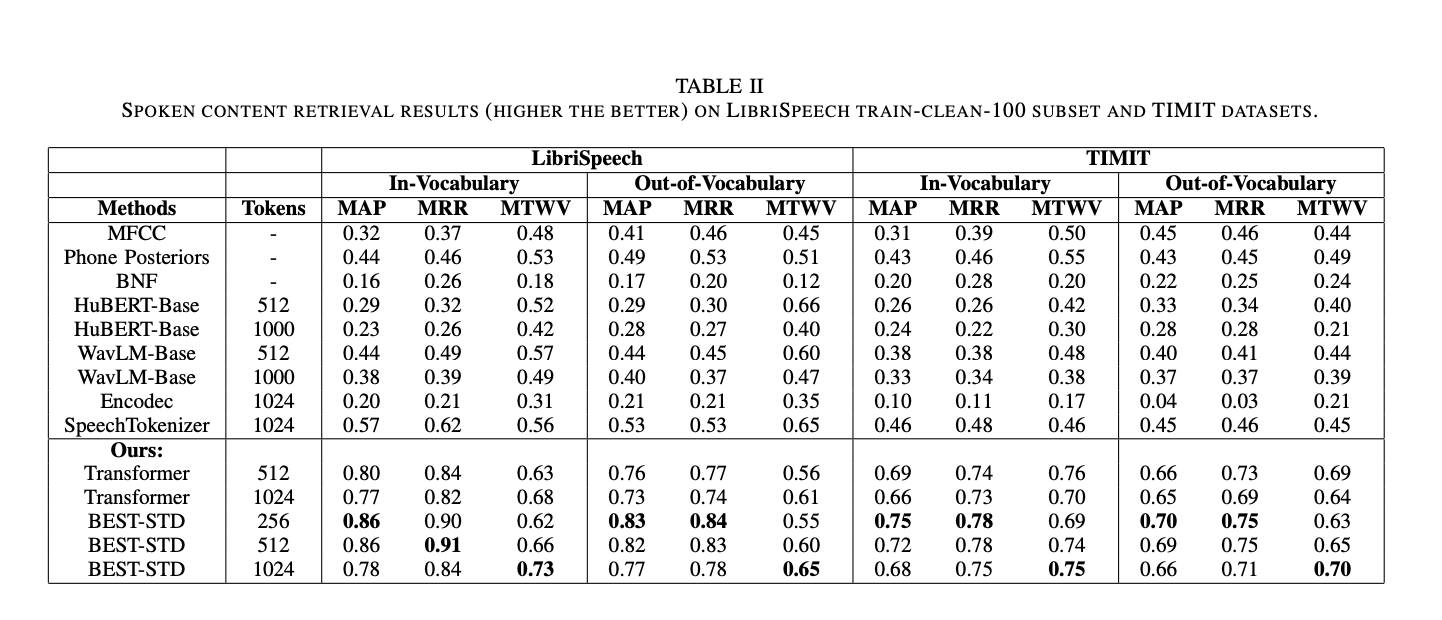
BEST-STD показала превосходные результаты в оценках на наборах данных LibriSpeech и TIMIT. Она достигла значительно более высоких показателей согласованности токенов по сравнению с традиционными методами и современными моделями токенизации. Это подчеркивает способность системы эффективно обобщать информацию по различным типам терминов и наборам данных.
Заключение
Введение BEST-STD представляет собой значительный шаг вперед в обнаружении произнесенных терминов. Этот подход предлагает надежное и эффективное решение для задач извлечения аудио, обеспечивая адаптивность к различным наборам данных. BEST-STD открывает новые возможности для улучшения доступности и поиска в обработке аудио.
Как внедрить ИИ в вашу компанию
Если вы хотите, чтобы ваша компания развивалась с помощью искусственного интеллекта (ИИ), следуйте этим рекомендациям:
- Проанализируйте, как ИИ может изменить вашу работу.
- Определите, где возможно применение автоматизации.
- Выберите ключевые показатели эффективности (KPI), которые хотите улучшить с помощью ИИ.
- Подберите подходящее решение — сейчас много вариантов ИИ.
- Внедряйте ИИ постепенно, начиная с малого проекта.
- Расширяйте автоматизацию на основе полученных данных и опыта.
Если вам нужны советы по внедрению ИИ, пишите нам.
Попробуйте ИИ ассистент в продажах, который помогает отвечать на вопросы клиентов и снижает нагрузку на команду.
Узнайте, как ИИ может изменить ваши процессы с решениями от Flycode.ru.

























