“`html
Оценка языковых моделей: путь к прозрачным и справедливым результатам
Оценка языковых моделей – критически важный аспект исследований в области искусственного интеллекта, направленный на оценку возможностей и производительности моделей в различных задачах. Эти оценки помогают исследователям понять сильные и слабые стороны различных моделей, направляя будущее развитие и улучшения. Одной из значительных проблем в сообществе искусственного интеллекта является отсутствие стандартизированной системы оценки для языковых моделей. Этот недостаток стандартизации приводит к несогласованности в измерении производительности, что затрудняет воспроизведение результатов и справедливое сравнение различных моделей. Общий стандарт оценки поддерживает достоверность научных утверждений о производительности моделей искусственного интеллекта.
Стандартизация оценки языковых моделей
В настоящее время существует несколько усилий, таких как HELM benchmark и Hugging Face Open LLM Leaderboard, направленных на стандартизацию оценок. Однако эти методы должны быть более последовательными в обосновании форматирования запросов, методах нормализации и формулировке задач. Эти несоответствия часто приводят к значительным отклонениям в отчетной производительности, усложняя справедливые сравнения.
Исследователи из Allen Institute for Artificial Intelligence представили OLMES (Open Language Model Evaluation Standard), чтобы решить эти проблемы. OLMES нацелен на предоставление всестороннего, практичного и полностью документированного стандарта для воспроизводимой оценки языковых моделей. Этот стандарт поддерживает значимые сравнения моделей, устраняя неоднозначности в процессе оценки.
Стандартизация процесса оценки
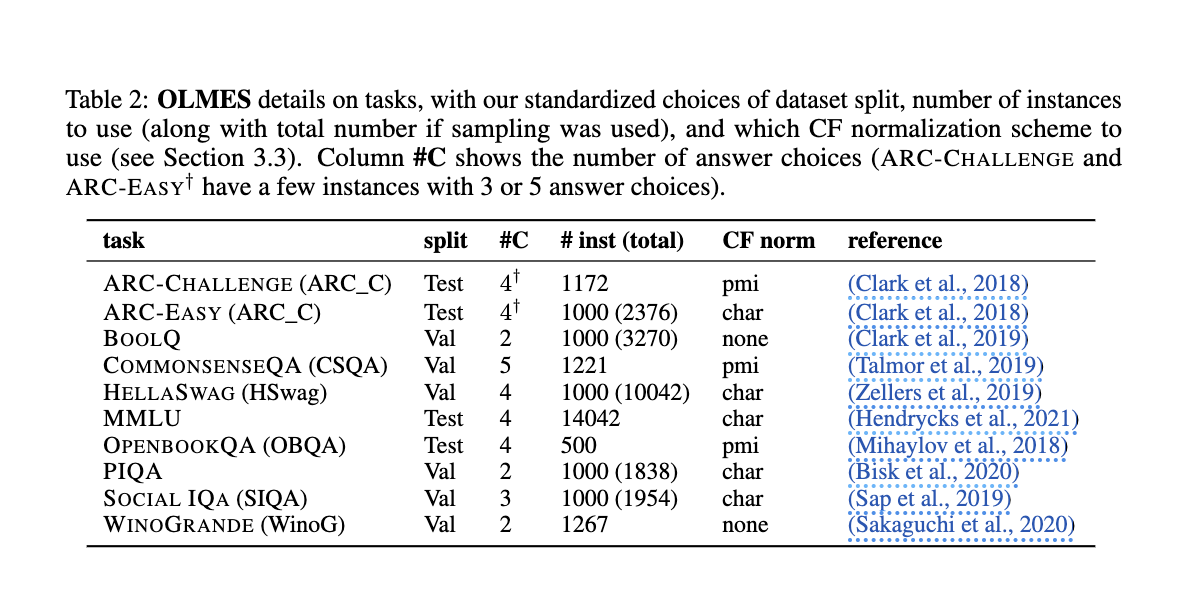
OLMES стандартизирует процесс оценки, устанавливая подробные рекомендации для обработки наборов данных, форматирования запросов, примеров в контексте, нормализации вероятностей и формулировки задач. Например, OLMES рекомендует использовать согласованные префиксы и суффиксы в запросах, такие как “Вопрос:” и “Ответ:”, для естественной ясности задач. Стандарт также предполагает ручную кураторство примеров для каждой задачи, обеспечивая высококачественные и сбалансированные примеры, охватывающие пространство меток эффективно. Кроме того, OLMES предписывает использование различных методов нормализации, таких как нормализация взаимной информации по точкам (PMI), для определенных задач, чтобы скорректировать врожденную вероятность выбора ответов. OLMES нацелен на то, чтобы процесс оценки был прозрачным и воспроизводимым, учитывая эти факторы.
Результаты и перспективы
Команда исследователей провела обширные эксперименты для проверки OLMES. Они сравнили несколько моделей с использованием как нового стандарта, так и существующих методов, демонстрируя, что OLMES обеспечивает более последовательные и воспроизводимые результаты. Например, модели Llama2-13B и Llama3-70B значительно улучшили производительность при оценке с использованием OLMES. Эксперименты показали, что рекомендуемые OLMES методы нормализации, такие как PMI для ARC-Challenge и CommonsenseQA, эффективно снизили вариации производительности. Особенно отметим, что некоторые модели сообщали до 25% более высокую точность с использованием OLMES по сравнению с другими методами, подчеркивая эффективность стандарта в обеспечении справедливых сравнений.
Для наглядности влияния OLMES исследователи оценили популярные бенчмарк-задачи, такие как ARC-Challenge, OpenBookQA и MMLU. Исследования показали, что модели, оцененные с использованием OLMES, показали лучшие результаты и проявили снижение различий в отчетной производительности по различным источникам. Например, модель Llama3-70B достигла замечательной точности 93,7% в задаче ARC-Challenge при использовании формата с множественным выбором, по сравнению с 69,0% при использовании формата с заполнением пропусков. Это существенное различие подчеркивает важность использования стандартизированных практик оценки для получения надежных результатов.
В заключение, проблема несогласованных оценок в исследованиях по искусственному интеллекту была эффективно решена введением OLMES. Новый стандарт предлагает комплексное решение путем стандартизации практик оценки и предоставления подробных рекомендаций для всех аспектов процесса оценки. Исследователи из Allen Institute for Artificial Intelligence продемонстрировали, что OLMES повышает надежность измерений производительности и поддерживает значимые сравнения различных моделей. Приняв OLMES, сообщество искусственного интеллекта может достичь большей прозрачности, воспроизводимости и справедливости при оценке языковых моделей. Ожидается, что это достижение стимулирует дальнейший прогресс в исследованиях и разработке искусственного интеллекта, способствуя инновациям и сотрудничеству среди исследователей и разработчиков.
“`










