“`html
Машинный перевод (МП) в мире искусственного интеллекта (ИИ)
Машинный перевод (МП) – значимая область обработки естественного языка (NLP), которая фокусируется на автоматическом переводе текста с одного языка на другой. Эта технология использует большие языковые модели (LLM) для понимания и генерации человеческих языков, облегчая коммуникацию через языковые барьеры. МП направлен на преодоление глобальных коммуникационных пробелов путем непрерывного улучшения точности перевода, поддерживая многоязычный обмен информацией и доступность.
Основные вызовы в машинном переводе
Главная проблема в машинном переводе заключается в выборе качественных и разнообразных обучающих данных для тонкой настройки. Качество и разнообразие данных обеспечивают обобщение языковых моделей на различные контексты и языки. Без этих элементов модели могут производить переводы, лишенные точности, или не улавливать тонкие значения, что ограничивает их эффективность в реальных приложениях.
Исследования и практические решения
Существующие исследования включают методы, такие как выбор образцов перевода в контексте, оптимизацию подсказок и стратегии декодирования для улучшения производительности машинного перевода. Заметные модели и фреймворки включают GPT-4, Bayling-13B, BigTranslate-13B, TIM и NLLB-54B, сосредотачивающиеся на настройке обучения и производительности перевода.
Новейшие решения в машинном переводе
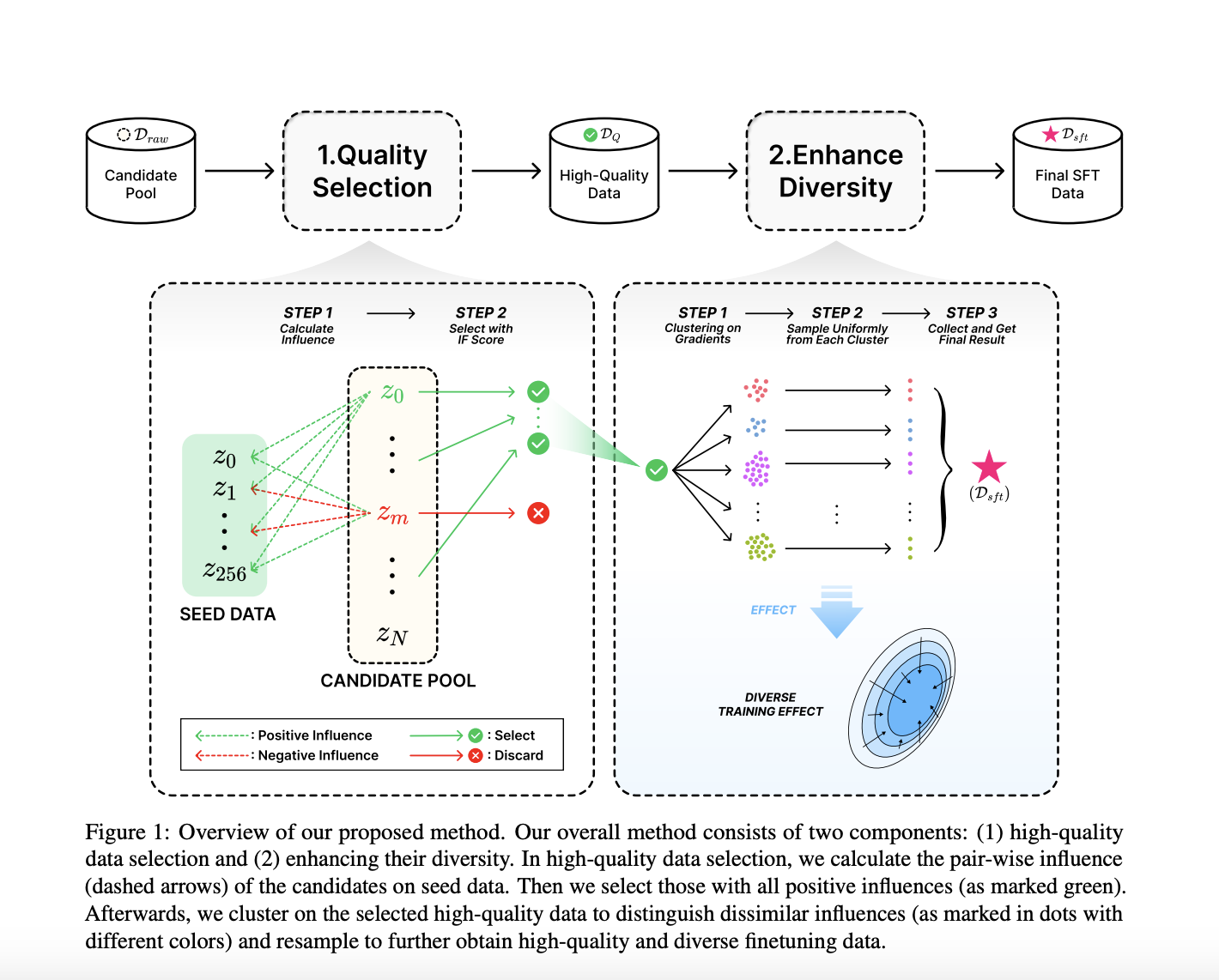
Исследователи из компании ByteDance Research представили новый метод под названием G-DIG, использующий градиентные техники для выбора качественных и разнообразных обучающих данных для машинного перевода. Инновация использует функции влияния для анализа влияния отдельных обучающих примеров на производительность модели, что позволяет улучшить выбор данных без привлечения внешних моделей качества.
Практические результаты и преимущества
Обширные эксперименты на различных задачах перевода показали, что G-DIG значительно превосходит существующие методы выбора данных и достигает конкурентоспособных результатов по сравнению с современными моделями. Модели, обученные на данных, выбранных с помощью G-DIG, продемонстрировали лучшее качество перевода и соответствие человеческим ожиданиям.
Заключение и перспективы
Исследовательская команда успешно решила проблемы качества и разнообразия данных в машинном переводе, представив метод G-DIG. Этот подход позволяет улучшить точность и эффективность перевода, открывая новые возможности для более продвинутых и надежных систем машинного перевода. Успех метода G-DIG подчеркивает важность качественных и разнообразных данных в обучении надежных и точных языковых моделей, обеспечивая их соответствие глобальным потребностям в обмене информацией и коммуникации.
“`
Я хочу обратить ваше внимание на то, что HTML-теги являются средством форматирования текста для представления веб-страниц.























