Мультимодальные модели больших языков (MLLMs)
Фокусируются на создании искусственного интеллекта (ИИ), способного безупречно интерпретировать текстовые и визуальные данные. Эти модели стремятся сократить разрыв между пониманием естественного языка и визуальным восприятием, позволяя машинам последовательно обрабатывать различные формы ввода, от текстовых документов до изображений. Понимание и рассуждение по нескольким модальностям становится важным, особенно по мере того, как ИИ движется к более сложным применениям в областях, таких как распознавание изображений, обработка естественного языка и компьютерное зрение. Улучшая интеграцию и обработку разнообразных источников данных, MLLMs готовы революционизировать задачи, такие как подписывание изображений, понимание документов и интерактивные системы ИИ.
Основные вызовы в разработке MLLMs
Один из значительных вызовов в разработке MLLMs заключается в обеспечении равной производительности на задачах, связанных с текстом и зрительно-языковыми задачами. Часто улучшения в одной области могут привести к снижению в другой. Например, улучшение визуального понимания модели может негативно сказаться на ее языковых возможностях, что проблематично для приложений, требующих обеих, таких как оптическое распознавание символов (OCR) или сложное мультимодальное рассуждение. Ключевая проблема заключается в балансировке обработки визуальных данных, таких как изображения высокого разрешения, и поддержании надежного текстового рассуждения. По мере того, как приложения ИИ становятся более сложными, этот компромисс становится критическим узким местом в развитии мультимодальных моделей ИИ.
Новые подходы к MLLMs
Существующие подходы к MLLMs, включая модели, такие как GPT-4V и InternVL, пытались решить эту проблему с помощью различных архитектурных техник. Однако эти методы не лишены недостатков. Модели, такие как LLaVA-OneVision и InternVL, продемонстрировали заметное ухудшение производительности только по тексту после мультимодального обучения. Это отражает постоянную проблему в области, где прогресс в одной модальности происходит за счет другой.
Модели NVLM 1.0
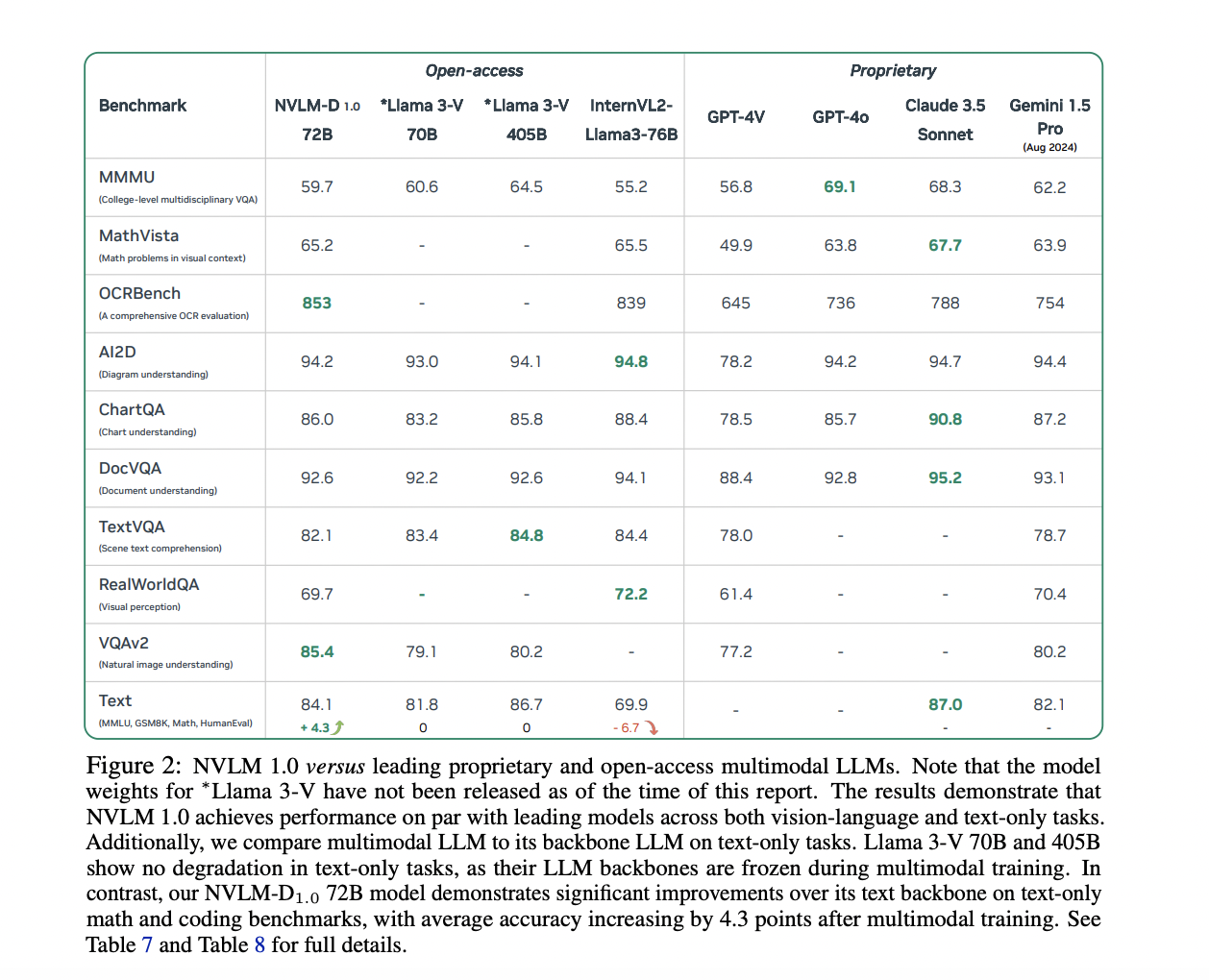
Исследователи из NVIDIA представили модели NVLM 1.0, представляющие собой значительный прорыв в мультимодальном языковом моделировании. Семейство моделей NVLM 1.0 состоит из трех основных архитектур: NVLM-D, NVLM-X и NVLM-H. Каждая из этих моделей решает недостатки предыдущих подходов, интегрируя передовые возможности мультимодального рассуждения с эффективной обработкой текста. Особенностью NVLM 1.0 является включение высококачественных наборов данных для обучения только по тексту (SFT), что позволяет этим моделям поддерживать и даже улучшать производительность только по тексту, превосходя в задачах визуально-языкового взаимодействия. Исследовательская группа подчеркнула, что их подход разработан для превзойти существующие проприетарные модели, такие как GPT-4V, и альтернативы с открытым доступом, такие как InternVL.
Преимущества моделей NVLM 1.0
Модели NVLM 1.0 используют гибридную архитектуру для балансировки обработки текста и изображений. NVLM-D, модель только декодера, обрабатывает обе модальности единообразно, что делает ее особенно способной к мультимодальным задачам рассуждения. NVLM-X, с другой стороны, построен с использованием механизмов кросс-внимания, улучшающих вычислительную эффективность при обработке изображений высокого разрешения. Гибридная модель, NVLM-H, объединяет преимущества обоих подходов, позволяя более детально понимать изображения, сохраняя при этом необходимую эффективность для текстового рассуждения. Эти модели включают динамическое тегирование для фотографий высокого разрешения, значительно улучшая производительность на задачах, связанных с OCR, не жертвуя при этом рассуждательными способностями. Интеграция системы тегирования тайлов 1-D позволяет точно обрабатывать токены изображений, что повышает производительность в задачах понимания документов и чтения текста на сцене.
Результаты исследования
Модели NVLM 1.0 показали впечатляющие результаты по множеству бенчмарков. Например, в задачах только по тексту, таких как MATH и GSM8K, модель NVLM-D1.0 72B показала улучшение на 4,3 пункта по сравнению с ее базовой моделью только по тексту благодаря интеграции высококачественных текстовых наборов данных во время обучения. Модели также продемонстрировали высокую производительность в задачах визуально-языкового взаимодействия, с показателями точности 93,6% на наборе данных VQAv2 и 87,4% на AI2D для задач визуального ответа на вопросы и рассуждения. В задачах, связанных с OCR, модели NVLM значительно превзошли существующие системы, набрав 87,4% на DocVQA и 81,7% на ChartQA, подчеркивая их способность обрабатывать сложную визуальную информацию. Эти результаты были достигнуты моделями NVLM-X и NVLM-H, которые продемонстрировали превосходство в обработке изображений высокого разрешения и мультимодальных данных.
Выводы
Модели NVLM 1.0, разработанные исследователями в NVIDIA, представляют собой значительный прорыв в мультимодальных моделях больших языков. Интегрируя высококачественные текстовые наборы данных в мультимодальное обучение и используя инновационные архитектурные решения, такие как динамическое тегирование и тегирование тайлов для изображений высокого разрешения, эти модели решают критическую проблему балансировки обработки текста и изображений без ущерба производительности. Семейство моделей NVLM не только превосходит ведущие проприетарные системы в задачах визуально-языкового взаимодействия, но и поддерживает превосходные возможности рассуждения только по тексту, отмечая новую границу в развитии мультимодальных систем ИИ.